이번 포스팅에서는 웹 서버 전용 EC2 인스턴스를 생성하고, 생성한 EC2 인스턴스에 httpd 설치 및 실행을 해보고 간단한 테스트 웹 페이지를 띄워보는 실습을 해본다.
Httpd
우선 웹 서버 전용 EC2 인스턴스를 생성한 뒤에 해당 EC2 인스턴스에 Httpd demon을 설치해줬다. 선택한 AMI가 CentOS와 비슷한 이미지를 가지고 만들었기 때문에 설치한 httpd 서비스가 EC2 lifting시에 자동으로 로드되게 하기 위해서는 서비스를 등록해야되는데, 설치하면 default로 서비스에 등록이 되기 때문에 아래와 같은 프로세스로 서비스 설치 및 시작을 하면 된다.
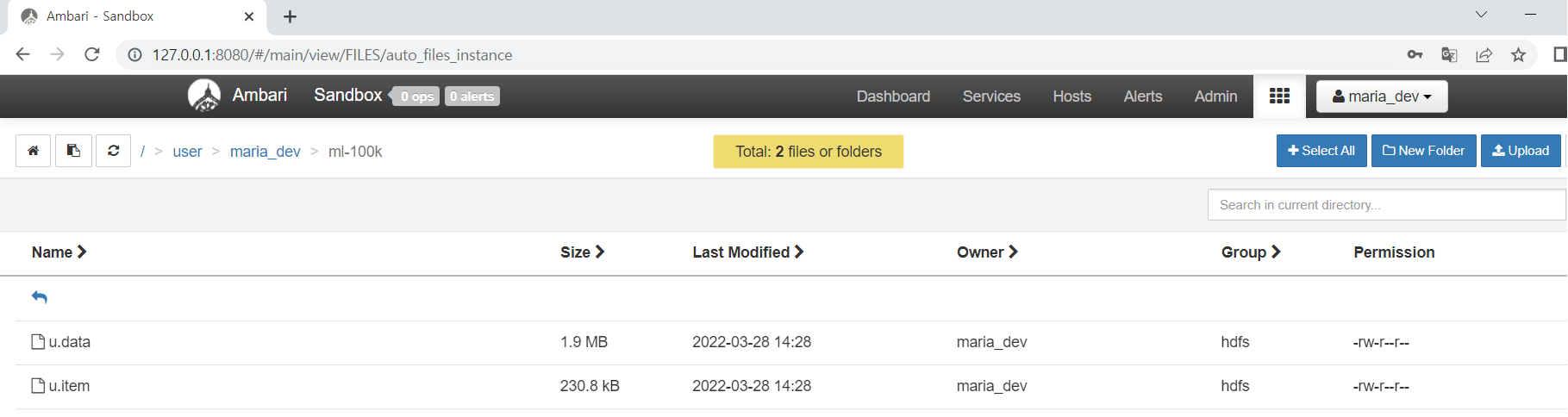
설치된 Httpd에 기본 Home 디렉토리(/var/www/html)가 있는데, 해당 위치에 웹 기본이 되는 파일(index.html)을 생성해서 간단하게 웹 페이지 테스트를 할 수 있다.
1 | # httpd 설치 |
위에서 index.html 파일내에 HTML 코드를 작성 후, 주소표시줄에 “연결” 메뉴에서 확인하였던 퍼블릭 DNS 주소를 웹에 붙여넣으면, 작성했던 HTML 페이지가 출력됨을 확인 할 수 있다.
이처럼 Public DNS 주소를 통해 생성된 EC2 인스턴스의 리소스에 접근을 할 수 있다는 것을 알 수 있다.
추가적으로 위의 httpd를 설치 및 서비스 시작하는 일련의 과정을 EC2 인스턴스 생성시에 고급 세부 정보 세션에서 사용자 데이터 부분에 스크립트로 넣어서 간단하게 실습해볼 수도 있다. (웹 서버 시작 부분까지)
1 | $yum update -y |