이번 포스팅에서는 데이터 수집 -> 전처리 및 저장 -> 분석/시각화에 이르는 데이터 파이프라인의 흐름에 대해 이해하고, 각 단계에서 필요한 AWS 서비스와 각 각의 용어와 의미에 대해서 정리해보려고 한다.
(정리를 하는 이유는 반복학습을 위해서이다. 물론 한 번에 보고 이해를 하고 외워지면 좋겠지만, 그렇지 않기 때문에 정리를 하는 것이고, 시간날때마다 반복해서 보고 추가적으로 다른 제 3자에서 설명할 수 있을때까지 추가적인 노력하자)탄탄한 이론 위에서 실습을 해야 향후에 새로운 기술들이 나왔을 때 연결고리를 만들어서 새롭게 가지치기를 하면서 학습을 이어나갈 수 있다.
데이터 엔지니어 채용관련 공고를 보았을 때 드는 생각이 AWS 클라우드 환경에서의 개발/운영 경험에 대한 요구사항이 많았다.
그렇다면, 온프레미스(On-premise)방식과 클라우드 환경에서의 데이터 처리가 차이가 있다는 것인데, 요구사항이 많다는 것은 온프레미스 방식보다는 클라우드 환경에서의 데이터 처리가 훨씬 더 효율적이고 좋다는 결론이 나온다.
앞으로 클라우드 환경에서 데이터 파이프라인을 구축했을 때의 장점에 대해서 인지하면서 실습을 해보도록 하겠다.
(1) 데이터 파이프라인의 흐름의 이해 STEP BY STEP
파이프라인은 하나의 데이터 처리 단계의 출력이 다음 단계의 입력으로 이어지는 형태로, 서로 파이프가 연결된 것과 같은 연결구조로 생각하면 된다.
[1단계] 데이터 수집 : 이 데이터가 왜 중요한지? 요구사항 수집 및 데이터 선정
[2단계] 데이터 전처리(Transformation) 저장 : 데이터 수집 단계에서 취득한 데이터를 전처리하고 저장하는 과정
[3단계] 데이터 시각화 분석 : 전처리 후 저장된 데이터를 SQL이나 데이터 시각화 지식이 없는 다른 부서에 제공을 해주기 위한 데이터 시각화 과정
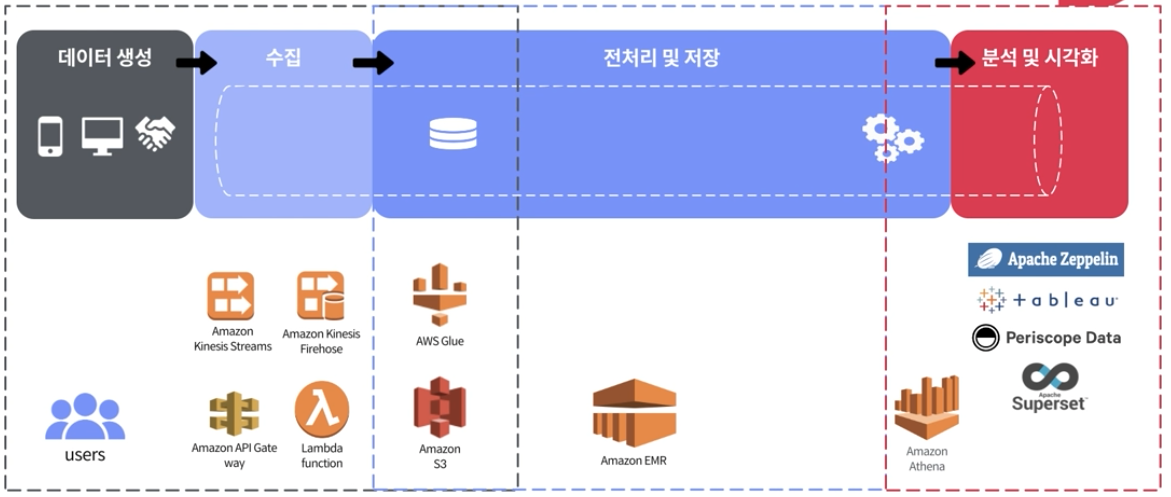
(2) 데이터 파이프라인에 필요한 AWS 서비스에 대한 이해
앞서 이미 정리를 했지만 온프레미스 방식의 서버 운영보다는 AWS와 같은 클라우드 기반의 서버 운영방식(off-premise)이 훨씬 장점이 많다고 했다. 그렇다면, AWS 서비스를 기반으로 데이터 파이프라인을 구축했을 때, 많은 AWS 서비스 중에서 어떤 서비스를 선택해서 사용해야되고, 해당 서비스가 어떤 기능을 제공하는지에 대한 기반 지식이 필요하다.
이번 파트에서는 AWS 기반으로 데이터 파이프라인을 구축했을 때, 데이터 파이프라인의 각 세션(수집/전처리 및 저장/분석 및 시각화)에서 AWS의 어떤 서비스를 적용해야되는지에 대해 정리를 해보려고 한다.
데이터 생성의 원천
기업에서 서비스를 운영할때, 데이터 기반으로 기존에 운영하고 있는 서비스를 개선한다는 이야기는 많이 들어봤다. 따라서 데이터란 기본적으로 운영되는 서비스의 기반 플랫폼이 되는 앱 또는 웹 사이트에 의해서 발생하는 이벤트를 통해 데이터가 생성되며, 이를 통해 수집할 수 있다.
수집된 데이터를 기준으로 서비스를 이용하고 있는 고객들의 성향이나 고객이 필요로하는 서비스를 분석하여, 서비스 개선시에 반영을 하고 있다.
각 기업마다 사용되는 외부에서 제공되는 분석 서비스가 있는데, 그 예로, 앱스플라이어와 같은 서비스가 있다. 클라우드가 활성화되면서 이를 통해 간단하게 스크립트만 넣으면 원하는 데이터를 뽑을 수 있도록 하는 서비스의 형태이다.
[1단계] 데이터 수집 단계 :
데이터 수집 단계에는 아래의 네 가지 AWS 서비스가 있다.
- Amazon Kinesis Streams
- Amazon Kinesis Firehose
- Amazon API Gate wway
- Lambda function
우선 첫 번째 Amazon Kinesis Streams은 일종의 큐 서비스이며, 레디스 큐(=스트림 큐))라고도 한다. 스트림은 흐름의 의미로, 강물에 비유하기도 하며 앞단부터 차근차근 쌓아놓고 흘러가는 데이터의 형태라고 이해하면 된다.
강물에서 물고기를 그물을 사용해서 잡는다고 가정했을 때, 강물이 바로 분석하고자 하는 데이터이고, 물고기가 바로 내가 찾고자하는 데이터이며, 던진 그물의 크기를 윈도우라고 한다.
데이터 전체를 일괄적으로 저장할 수 없기 때문에 폭포가 있는 강처럼 일정 사이즈 용량으로 한정하고, 일정 시간이 되면, 데이터가 소멸하게 되는 형태로 구성된다.
데이터를 스트림 형태로 사용하는 이유는 대량의 데이터를 가지고 있기 때문에 여러 서비스에서 분석 가능하며, 만약 앱상에서 발생한 데이터를 클라우드에 저장하거나 한다면, 사용자가 앱 내에서 네이게이션을 하고 있을 때 앱의 퍼포먼스에 영향을 줘서 버벅거리거나 하는 사용감에 불편함을 줄 수 있다.
앞서 언급한 단점으로 인해서 스트림 형태로 데이터를 사용한다.
수집된 데이터 -> RDBMS에 직접 저장하게 되면, RDBMS는 리소스가 한정적이기 때문에, 트래픽이 일괄적으로 몰리면 앱이 느려지는 경향이 있다.
따라서 이러한 경우에는 수집된 데이터 -> (큐 서비스) -> RDBMS의 형태로 RDBMS에 데이터를 적재하기 전에 큐 서비스가 사이에서 모든 데이터를 받고, 사용자가 네비게이션을 할 때 불편함이 없도록 원활하게 앱이 동작할 수 있도록 도와준다.
두 번째로 Amazon Kinesis Firehose라는 큐에 있는 데이터를 별도의 코딩없이 S3에 저장할 수 있도록 지원하는 서비스가 있다. (요즘에는 S3 뿐 아니라 ElasticSearch와 같은 third party에 실시간으로 데이터를 넣을 수 있는 스토리지가 있다)
세 번째로 Amazon API Gate way라는 외부에서 웹/앱에서 AWS와 연결시켜주는 역할을 해주는 프록시 서비스가 있다. 각 서비스간에 서로 영향을 주지 않는 마이크로 서비스라고도 하며, 10개의 서비스 중에 1개의 서비스가 fail out이 되더라도 나머지 9개가 정상적으로 동작할 수 있도록 도와주는 서비스이다.
마지막으로 네 번째, Lambda function이있다. Lambda function은 Event-driven 데이터 처리를 할때 이벤트에서 발생하는 여러가지 서비스를 핸들링하기 위해서 사용된다.
초기에는 Amazon kinesis Stream -> (Lambda function) -> S3 / RDBMS의 형태로 해서 데이터를 저장하였다.
[1.5단계] 데이터 수집과 전처리의 교차점 : AWS Glue
이 과정에는 AWS Glue라는 서비스가 있다.
우선 AWS Glue의 등장배경은 AWS의 Pipeline이라는 서비스이다. 데이터 파이프라인을 통해서 기본적인 ETL(Extract/Transformation/Load)라는 처리를 하게 되는데, Amazon의 Pipeline이라는 녀석이 관리되는 파이프라인이 많아졌을 때 관리 및 운영하는데 어려움이 있었기 때문에 이러한 문제를 개선하기 위해 등장한 친구가 바로 AWS Glue이다. AWS Glue에는 파이프라인의 기본적인 서비스들이 추가가 되어있으며, 가장 비용 효율적으로 잘 활용되고 있는 부분은 바로 메타 스토어 정보가 포함되어있는 부분이다. 이 메타 스토어 정보에는 데이터 위치/포멧/버전의 변경사항등에 대한 정보를 포함하고 있다.
[2단계] 전처리 및 저장 : Amazon S3, Amazon EMR
Amazon EMR는 AWS에 있는 Hadoop Eco System을 가지고 있는 관리형 서비스이다.
과거에는 하둡을 설정하려면 서버에서 리눅스 설치, 하둡에 필요한 라이브러리 및 서비스를 설치하고 각 노드들을 연결하기 위해 네이밍을 하는 작업들을 해야만 했는데, 대략 2주정도 소요가 된다고 한다.
그런데 이 Amazon EMR을 이용하면, 기본적으로 구축된 환경을 제공해기 때문에 최대 5-10분 사이에 구축된 서비스를 이용할 수 있다.
Amazon EMR을 통해 전처리하고 전처리된 데이터를 저장하고자하는 타겟 요소에 저장되도록 도와준다.
[3단계] 분석 및 시각화 : AWS Athena, Tableau, Periscope Data, Superset
AWS Athena는 adhoc하게 데이터를 분석할 수 있도록 도와준다.
그외의 시각화 툴인 녀석들을 이용해서 SQL관련 지식이 없는 타 부서 업무 담당자에게 시각화를 해서 정보를 제공해줄 수 있다.
앞서 정리한 [1단계] ~ [3단계]에서 정리한 내용은 틈틈이 실습을 하면서 내가 지금 하고있는 실습이 몇 단계에 해당되는 내용인지 확인을 하고 실습 및 활용을 하는 것이 좋다.