이번 포스팅에서는
221016 Mapper class Bean 등록 Issue
우선 본 포스팅에서 다루고자 하는 에러가 어떤 상황에서 발생하게 되었는지에 대해서 간략하게 설명을 하고, 어떤 접근으로 해결하려고 했는지에 대해서 기술해보려고 한다.
프로젝트 진행
회사에서 진행중인 프로젝트에서 백엔드를 구성하면서 간단한 CRUD 처리의 경우에는 JPA를 사용하고, 복잡한 쿼리 사용의 경우에는 MyBatis를 사용하기로 했다. 여기서 말하는 복잡한 쿼리란 간단한 CRUD 이외의 복잡한 쿼리를 말한다.
그냥 이렇게 하라고 하니깐 하는 게 아니라 이렇게 구성을 하면 어떤 이점이 있는지에 대해서 간단하게 짚고 넘어가도록 하자.
Hibernate vs MyBatis
과거 EJB2로 개발을 하던 당시 Gavin king이라는 사람이 사용자 친화적이지 않은 자바 애플리케이션 개발 방식을 좀 더 사용자 친화적이게 만들고자 개발을 하게 된 것이 바로 그 유명한 Hibernate이다. 이 Hibernate가 점차 인기가 많아지자 자바 진영에서 Gavin king을 영입해서 자바
ORM(Object Relational Mapping)기술에 대한 표준 명세를 개발하도록 하였는데, 그것이 바로JPA(Java Persistent API)이다.JPA는 ORM을 사용하기 위한 인터페이스를 모아둔 것으로, 이를 구현한 프레임워크 중 대표적으로 Hibernate가 있고, Spring에서는 대부분 Hibernate를 사용하고 있다.
Spring에서는 JPA를 사용할 때 구현체들을 직접 다루지 않고,구현체들을 좀 더 쉽게 사용하고자 추상화 시킨 Spring Data JPA라는 모듈을 시용하여 JPA 기술을 다룬다.그렇다면, JPA 하나만 사용해서 개발하면 만능일까? 찾아보니 대부분 단순한 CRUD의 처리를 하는 경우에는 JPA만을 사용해도 괜찮다고 한다. 하지만, 복잡한 통계나 정산관련 조회 쿼리가 포함된 경우, MyBatis로 처리하면 좀 더 개발자에게 편하다. 물론 JPA로도 복잡한 집계성 쿼리를 처리하는 것도 가능은 하지만 구현이 쉽지 않기 때문에 MyBatis를 사용하는 것이 낫다고 한다.
따라서 JPA 또는 MyBatis만 사용하는 것이 아닌, 두 개를 적절히 조합해서 프로젝트를 진행하면 업무적으로 효율이 높아질 수 있다는 결론이 나온다.
- MyBatis의 사용
MyBatis는 Mapper를 별도로 구성하며, SqlSession을 직접 사용하는 형태가 아닌 Mapper를 통해 처리한다. 기본적으로 Mapper를 사용하게 되면, Mapping 파일이 자동으로 Mapper의 단위가 되기 때문에 유지보수 및 관리에 용이하다.
221015 Spring boot 스터디 (작성중...)
이번 포스팅에서는 Spring boot의 프로젝트 구성에 대해서 작성해보려고 한다.
현재 회사에서 진행하고 있는 프로젝트의 백엔드가 Spring으로 구성이 되어있고, 각 회사마다 같은 기술스택이라도 그 구성이 다르게 적용되어있기 때문에 좀 더 빠르게 익숙해지고자 본 포스팅에 내용을 정리해서 작성하려고 한다.
Custom annotation - Datasource switching
현재 백엔드에서는 DataMart와 DataWarehouse에 해당되는 데이터베이스와 연결이 되어있다.
스프링에서는 Type을 기반으로 Bean component를 scan하기 때문에 같은 DataSource 타입을 기반으로 하는 두 Bean 객체를 주입할 때는 구분을 해줘야 한다. (@Primary, @)
따라서 현재 프로젝트에서는 별도의 config package 내에 데이터베이스별로 구분을 해서 custom annotation을 만들어서 Mapper class에 적용해서 Mapper class에 해당되는 Spring Bean이 등록되어 관리되도록 하고 있다.
JPA와 MyBatis의 사용
Spring 백엔드 프로젝트의 구성은 우선 JPA와 MyBatis를 사용하여 구성한다.
- JPA : 간단한 CRUD 처리를 위한 query 관리
- MyBatis : 상대적으로 복잡한 query (
inc. JOIN)
221008 Apache NiFi 스터디 (작성중...)
이번 포스팅에서는 최근에 새롭게 접하게 된 ETL 툴인 Apache NiFi에 대해서 정리해보려고 한다.
NiFi의 기술적 배경
NiFi는 NAS라는 미국의 국가 안보국에서 Apache에 기부한 Dataflow 엔진으로, ETL툴의 일종이다.
NiFi는 과거에 NSA에 의해 개발되었다가 2014년 기술 전송 프로그램의 일부로, 오픈소스화된 나이아가라파일즈(NiagaraFiles)에 기반을 두고 있다.
NiFi는 분산환경에서 대량의 데이터를 수집, 처리한다. => FBP개념을 구현한 오픈소스 프로젝트
여기서 FBP란 사전에 Data Flow를 정의하고, 이를 지속적으로 유지하면서 데이터를 교환하는 프로그래밍 패러다임이다.
(마치 Apache Airflow에서 DAG를 작성해서 전체적인 Task flow를 구성한 뒤에 반복적인 데이터 처리를 자동화 시키는 것과 같은 맥락이다)
NiFi의 필요성
그래서 왜 NiFi가 필요할까? 앞서 이미 정의했듯이 NiFi는 ETL툴의 일종으로, 클러스터로 구성이 되어있기 때문에 대량의 데이터를 분산시켜서 처리할 수 있다.
NiFi는 A 시스템에서 B 시스템으로 데이터를 이관하는 것을 손쉽게 할 수 있도록 도와주는 서비스 툴로, 데이터를 이관하는 중간에 데이터를 변형(정제)할 수 있다. 그 외에도 관리 및 모니터링이 가능하다.
NiFi의 구성
NiFi는 FlowFile, Processor, Connection, 이 세 가지로 구성이 되어있다.
[FlowFile]
FlowFile은 NiFi가 인식하는 데이터 단위로, 속성과 내용이 Key/Value 혀태로 구성이 되어있다. Processor마다 이동시 복사본이 생성되어, 추적이 용이하다.
ref.query를 작성할때 [table명] 대신에 FLOWFILE을 작성하게 되면, 파이프라인 상에서 흘러가는 파일 정보를 읽을 수 있다.[Processor]
FlowFile을 수집, 변형 및 저장하는 기능이 있으며, 자주 사용되는 프로세서로는
http, kafka, db, ftp와 관련된 프로세서, 속성을 변경하는updateattribute, 데이터를 합치는mergecontent, 데이터를 분할하는split, 데이터 타입을 변경하는convert등이 있다.[Connection]
각 Processor별로 연결해서 FLOWFILE을 전달하는 역할을 담당하고, FlowFile의 우선순위, 만료, 부하조절 기능도 제한하고 있다.
NiFi 아키텍쳐
[Web Server]
발생하는 이벤트를 모니터링, 소프트웨어를 시각적으로 제어하기 위해서 사용된다. (
HTTP기반 구성요소)[Flow controller]
NiFi 동작의 뇌 역할을 담당한다.
NiFi 확장기능의 실행을 통제하고, 이를 위한자원 할당을 스케줄링한다.[Extensions]
NiFi가 다양한 종류의 시스템과 통신할 수 있게 하는 다양한 플러그인이다.
[FlowFile Repository]
NiFi가 현재 실행중인 FlowFile의 상태를 추적하고, 정비하기 위해 사용된다.
[Content Repository]
전송 대상의 데이터가 관리된다.
220813 Docker 스터디

이번 포스팅에서는 docker를 사용하면서 유용하다고 생각되는 명령어들을 정리해두려고 한다.
Docker container 일괄 중지 및 삭제
1 | $docker stop $(docker ps -a -q) # docker container 전체 중지 |
Docker container로 올린 애플리케이션 build 다시 하기
FastAPI로 만든 API 애플리케이션을 Docker로 올린 후 코드를 수정하면, 수정된 코드 내용이 반영이 안되는데 이때 아래 명령으로 다시 빌드하면 수정된 코드가 반영이 된다.
1 | $docker-compose up --builds |
220808 Apache Airflow

Configuration 살펴보기
더 많은 Airflow Worker가 필요하다면, 추가 machine에서 celery worker를 명령한다.
Flower
Airflow workers를 dashboard를 통해서 모니터링하기 위한 툴이다. Celery Executor를 사용하면, Flower에 접속해서 Celery Executor의 Administrator와 Airflow worker를 대시보드를 통해 모니터링 할 수 있다.
localhost:5555/dashboard
아래의 Worker dashboard를 살펴보면, Max concurrency 값이 16인 것으로 보아, 최대 16개의 Task를 동시에 실행하는 것이 가능하다. 이는 사용하는 PC의 리소스에 따라 줄일 수도 늘릴 수도 있다.
다음으로 Queues 메뉴는 유용하게 사용될 수 있는데, 특정 Task를 특정 worker로 라우팅되도록 할 수도 있다.
예를들어 높은 리소스를 소비하는 Task가 존재하고, 현재 하나의 높은 리소스 Worker를 가진다고 가정하면, queue를 생성해서 queue를 Worker에 붙이고, 높은 리소스 소비 Task를 생성한 queue로 보내서 해당 Worker만 해당 작업을 실행할 수 있도록 queue를 지정해서 사용할 수 있다.
220808 FastAPI, ASGI, Uvicorn

FastAPI?
FastAPI는 Python web framework로, API를 만들 수 있고, Python 버전은 3.6이상에서 적용이 가능하다. 그리고 Uvicorn ASGI Server를 사용한다.
ASGI(Asynchronous Server Gateway Interface)
ASGI는 비동기 웹 서버를 의미하고, DB나 API 연동 과정에 발생하는 대기시간을 없이 CPU가 복수의 작업을 할 수 있도록 하는 방식을 말한다. 동기 방식은 WSGL을 사용한다.
WSGI(Web Server Gateway Interface)
WSGI는 ASGI가 나오기 전에 사용되던 것인데, 비동기적인 처리를 제공하기 위해서 ASGI가 등장하였다. 사용자가 서버에 요청을 보내면, 해당 요청에 대해서 결과를 반환하게 되는데, 서버에서 만든 API 프로그램이 작동할 수 있도록 서버와 API 프로그램을 연결해주는 입구 역할을 해주는 것이 바로 ASGI(WSGI)이다.
ASGI는 작성한 FastAPI 애플리케이션 프로그램의 실행 결과를 웹 서버에 전달해주고, 웹 서버는 ASGI로부터 전달받은 응답 결과를 웹 클라이언트인 브라우저에 전송을 한다.
Uvicorn(프로세스 관리자, 실행기)
uvloop과 httptools를 사용하여 ASGI 서버를 구현한 구현체이다. 다시말해, Uvicorn은 ASGI 웹 애플리케이션을 실행하는 서버이다.
220807 Apache Airflow
Backfilling
DAG를 처음 실행하게 되면, scheduler는 자동으로 non-triggered DagRuns을 시작 날짜(start_date)와 현재(now) 사이 시점에서 실행하게 된다.
catch up mechanism은 자동으로 non-triggered DagRun을 마지막으로 실행된 날짜와 현재 시간 사이에서 실행할 수 있도록 허용한다.
예를들어, 만약에 DAG를 2일동안 중지시키고나서 DAG를 다시 시작했다면, 이 기간 동안 트리거되지 않은 DAG 실행에 해당하는 일부 DAG 실행이 발생합니다.
Backfilling mechanism은 historical DagRuns를 실행하도록 하는데, 예를들어 start date 이전의 기간에 DagRun을 실행할 수 있다.
방법은 Airflow DAG Backfill 명령을 실행하는 명령을 사용하면 된다.
(예를들어 01/03(start_date)부터 01/07(now)까지 DAG RUN을 실행했고, start_date 이전인 01/01부터 01/02 기간동안 DAG RUN을 실행하고자 한다면, Backfilling mechanism을 위한 명령을 사용하면 된다)
1 | with DAG('my_dag', start_date=datetime(2022, 1, 1), schedule_interval='@daily', catchup=False) as dag: |
이렇게 catchup=False로 설정값을 바꿔주면, non-triggered DAG RUN이 실행되게 된다. 이 mechanism은 과거에 non-triggered DAG RUN을 자동으로 재실행할때 사용된다.
Executor
이전 포스팅에서도 다뤘던 내용이지만, Executor는 이름 자체는 Task를 실행할 것 같지만, Task를 실행하지 않는다. 단지 tasks를 시스템에서 어떻게 실행할 것인가에 대해 정의한다.
Executor에는 다양한 종류가 있는데, local executors와 remote executors가 있다. local executor는 여러 개의 task를 single machine에서 실행을 하고, sequential executor는 single machine에서 한 번에 하나의 task를 실행할때 사용된다.
remote executor에는 Celery executor가 있는데, tasks를 multiple machine, 그리고 salary cluster에서 실행한다. K8s executor는 multiple machine에서 K8s cluster의 multiple pods에서 multiple tasks를 실행한다.
Executor의 변경은 Airflow의 환경설정 파일에서 executor parameter를 변경함으로써 적용할 수 있다. (사용되는 executor에 따라 변경해야 되는 별도의 환경설정 요소가 있다)
220805 Python 동시성 & 병렬성 프로그래밍
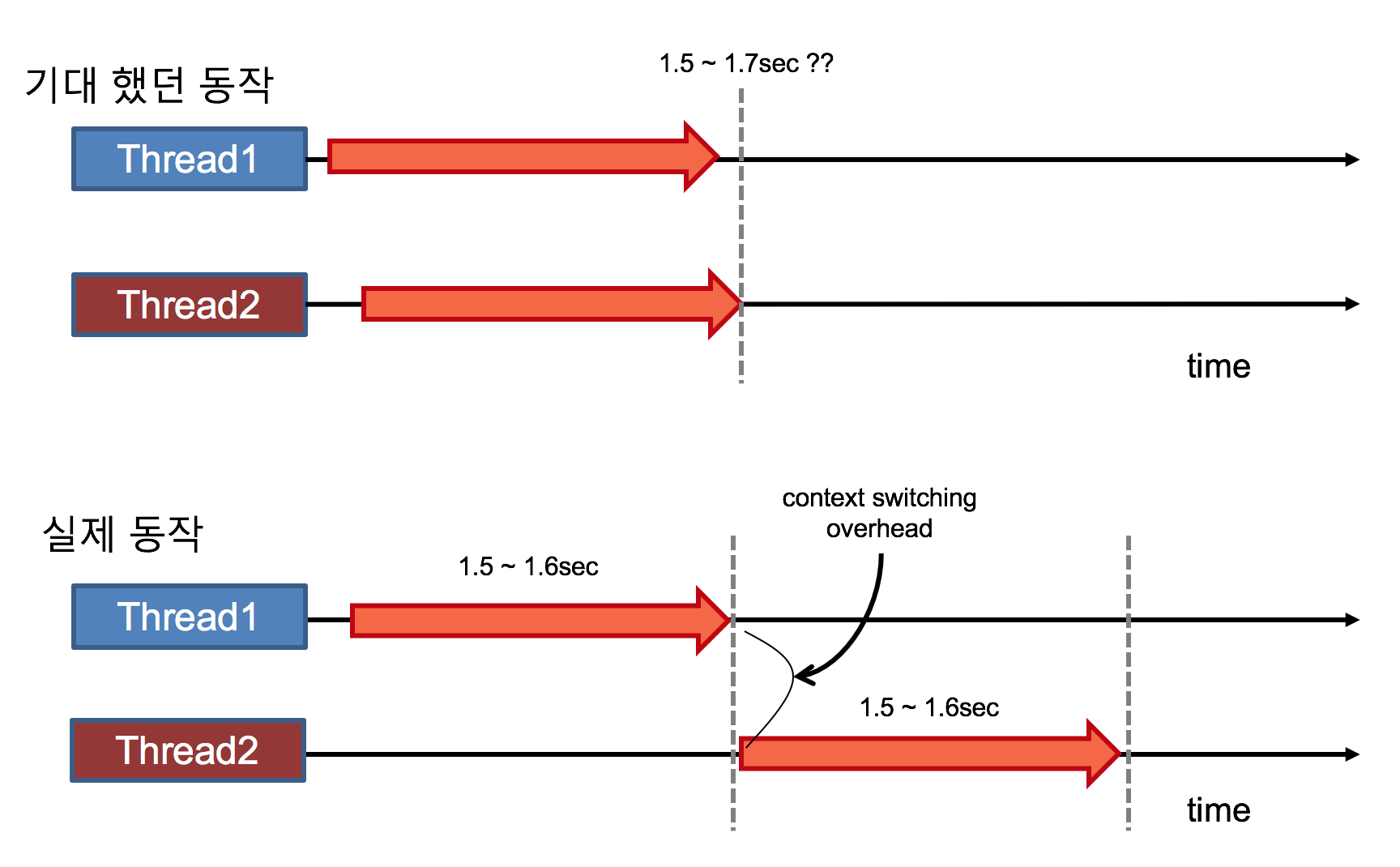
venv 명령어
1 | $python -m venv venv # venv이름으로 가상환경 생성 |
pip 명령어
pip는 Python의 패키지 매니저로, 외부 패키지나 라이브러리, 프레임워크를 설치하고 관리할 수 있도록 도와준다.
1 | $pip install pip --upgrade # pip upgrade |
설치된 페키지를 text로 보내고 설치하기(협업)
1 | $pip freeze > requirements.txt # requirements.txt 파일에 설치된 패키지 리스트를 파일로 뽑아내기 |
1 | # python version: 3.8.1 |
CPU 바운드, I/O 바운드, Blocking
바운드
바운드란 장애물에 막혀서 실행이 되지 않는 상태를 말한다.
CPU 바운드
프로그램이 실행될 때 실행속도가 CPU 속도에 의해 제한되는 것을 말하며, 복잡한 수학 수식을 계산하는 경우, CPU의 연산 작업에 의해 프로그램이 실행될때 실행속도가 느려지거나 멈춰있는 되는 현상이 발생하게 되는데, 이를 CPU 바운드라고 한다.
I/O 바운드
프로그램이 실행될 때 실행속도가 I/O에 의해 제한되는 것을 말하며, 프로그램에서 사용자의 입력을 기다리기 위해 프로그램이 멈춰있는 경우가 발생하는데, 이를 I/0 바운드라고 한다.
Network I/O 바운드
사용자로부터 입력을 기다리기 위해 프로그램이 멈추는 것이 아닌, 외부 서버에 요청을 하여 응답을 기다리는 경우에도 프롤그램이 멈춰있는 현상이 발생하는데, 이를 Network I/O 바운드라고 한다.
Blocking
바운드에 의해 코드가 멈추게 되는 현상이 일어나는 것을 블로킹이라고 한다.
220805 Apache Airflow
Apache Airflow UI 구성
Apache Airflow UI에서 DAGs 리스트를 보면, 현재 Apache Airflow에 포함되어있는 DAG의 목록이 출력된다. 리스트 중 하나의 아이템을 살펴보면, DAG의 이름의 좌측에 해당 DAG를 Pause/Unpause 할 수 있는 토글 버튼이 있고, 이름의 아래에는 data pipeline이나 팀 또는 기능별로 묶어서 관리할 수 있도록 태그가 표시되어있다. (단, tag에 따라 permission을 부여할 수 없다)
그 외에 Owner에 대한 정보와 Runs 칼럼에서는 queued, success, running, failed 상태별로 현재 DAG이 실행 상태를 확인할 수 있다. Last Run 및 Next Run 항목을 통해서는 DAG가 언제 마지막으로 실행이 되었고, 그 다음 실행은 언제 되는지에 대해 확인할 수 있다.
Recent Tasks에서는 총 15개의 상태 정보로 나뉘어 활성화된 DAG의 Task들의 실행 상태에 대해서 확인을 할 수 있다. (none, removed, scheduled, queued, running, success, shutdown, ...)
Actions에서는 강제로 Trigger 시키거나 DAG를 삭제할 수 있는데, DAG를 삭제한다는 의미가 DAG 자체를 삭제하는 것이 아닌, Meta store에서 DAG RUN Instance를 삭제한다는 것을 의미한다.
Apache Airflow DAG item 상세보기
DAG의 이름을 클릭하면, Grid를 통해 실행한 DAG들의 상태 정보에 대해서 모니터링 할 수 있으며, Graph View를 통해서는 DAG의 각 Tasks가 어떤 Tasks를 dependencies로 가지고 있는지에 대해서 구조적으로 확인을 할 수 있다.
Landing Times에서는 DAG에서의 모든 작업들이 scheduled 상태에서 completion으로 완료되는데 얼마나 걸렸는지에 대한 정보를 시각화된 그래프로 확인할 수 있다. 만약 시간이 오래걸린다면, 걸리는 시간을 줄일 수 있도록 별도의 대응이 필요하다.
Calendar view에서는 각 각의 네모칸이 특정 DAG의 상태 다이어그램 정보를 종합해서 보여준다. 특정 DAG가 특정 날짜에 문제가 생긴다면, 빨간색으로 칸이 표시되며, 성공적으로 DAG가 시행이 되었다면 해당 일자에 초록색으로 포시된다. 점으로 표시된 칸은 얼마나 많은 다이어그램이 해당 날에 계획되어있는지에 대한 정보를 제공한다. 따라서 이러한 모니터링 정보를 기반으로 어떤 날에 데이터 파이프라인을 수정해서 문제를 해결해야되는지 알 수 있다.
Gantt view에서는 DAG의 특정 Task가 완료되는데에 얼마나 시간이 걸렸는지와 pipeline에서 bottleneck이 발생했는지에 대한 전반적인 overview를 제공한다. 상대적으로 긴 직사각형은 그만큼 Task를 실행하는데 시간이 걸렸다는 의미이고, 오래걸린 작업에 대해서는 어떻게 하면 작업이 완료되는데 걸리는 시간을 단축시킬 수 있는지에 대한 고민이 필요하다.
직사각형이 overlapping되었다는 것은 복수 개의 Task를 동시에 실행할 수 있다는 것을 의미한다. (DAG parallelism)
Code view에서는 데이터 파이프라인의 코드에 접근할 수 있는데, 이를 통해서 적용한 수정사항이 DAG에 제대로 적용이 되었는지 확인을 할 수 있다.