
Kubernetes ?
큰 기업은 대규모의 서비스를 운영하고 있기 때문에 최대한 자원을 효율적으로 써야 비용적으로 유리하다. 따라서 서버자원을 효율적으로 쓰기 위해서는 가상화 기술에 대해서 이해해야 한다.
과거에는 리눅스의 자원격리 기술(1991)이 있었다. 이후에 VMware, Xen, openstack VM(Virtual Machine)(2010.7)
가상화를 위해서 띄우고자 하는 가벼운 서비스를 사용하기 위해 더 무거운 OS를 올려야되는 상황이 생겼다.
어려운 자원격리기술을 dotCloud라는 회사에서 쉽게 사용할 수 있도록 container 서비스를 만들었고, 회사를 docker로 변경하면서 만든 서비스를 오픈소스로 공개하였다. (2014.06)
컨테이너 가상화 기술은 서비스간에 자원격리를 하는데 별도의 OS를 안띄워도 되기 때문에 OS 기동시간이 필요없게 되고, 자동화시 엄청 빠르고 자원의 효율도 매우 높아지게 되었다.
이러한 이유로 도커는 유명해졌다. 하지만 도커 자체는 하나의 서비스를 컨테이너로 가상화시켜서 배포를 하는 것이기 때문에 많은 서비스들을 운영할때 일일이 배포하고 운영하는 역할을 해주지 않기 때문에 불편함이 있었다.
이러한 불편함을 해소하는데 도움을 준 것이 바로 컨테이너 Orchestrator 개념인 쿠버네티스이다. 여러 컨테이너를 관리해주는 서비스인데, docker가 오픈소스이기 때문에 많은 기업에서 다양한 Orchestrator를 출시하게 된다.
대표적으로 AWS의 EKS(Elastic Kubernetes Service), RANCHER, HashiCorp의 Vault, Google의 Kubernetes 등이 있다.
이 중에서 Kubernetes의 프로젝트에 구글의 주도 하에 여러 기업(RedHat, MS, IBM, docker, SALTSTACK 등)이 참여하였고, 타 기업의 서비스보다 만족도가 높았다고 한다.
이러한 Kubernetes를 활용해서 Google cloud, AWS, Azure, IBM Cloud, Oracle Cloud에서 서비스들을 만들어서 운영하고 있다.
쿠버네티스 공부 순서
쿠버네티스를 운영하는 운영자, 쿠버네티스를 기능을 활용해서 서비스를 배포하는 사용자로 나뉜다.(아무것도 모르는 상태에서 운영에 대한 내용을 먼저 학습하면 너무 어려워서 질려버릴 수 있다) 초반에는 사용자 기능을 중점으로 학습하고, 운영에 대한 내용은 차후에 학습을 하는 것을 권장한다고 한다.
쿠버네티스의 자동화 기능
서버 운영에 있어 충분한 서버 자원이 뒷받침 되어야 한다.
서버의 자원을 효율적으로 사용하기 위해 쿠버네티스는 서버 자원에 대해 Auto Scaling을 해주게 되는데, 시간대별로 트래픽에 따른 자원의 사용량이 다른 각기 다른 서비스간에 평균 자원 사용량을 계산해서 Kubernetes는 최대한 낭비하지 않는 선에서 서버 자원을 사용할 수 있도록 도와준다.
서버 자원에 대해 백업 및 장애대응을 위해 여분의 서버를 서비스당 한 대씩 준비하고 있으며, 쿠버네티스로 관리되는 서버는 Auto Healing 기능을 제공하기 때문에 여분의 서버로 서비스를 이전시켜서 서비스를 유지시켜준다.
서비스의 중단이 허용되면 모든 서버를 내렸다가 업데이트 작업 후에 다시 전체 서버를 올리는 경우도 있으며, 무중단 서비스를 해야되는 경우, 한 개의 서비스씩 내렸다가 업데이트 작업후에 서비스를 올리는 방식으로 진행된다.
쿠버네티스도 Deployment라는 객체를 통해서 업데이트 방식에 대해 자동적으로 처리되도록 하고 있다. (RollingUpdate, Recreate)
VM과 Container 비교
VM은 Host OS 위에 Hypervisor를 올리고 그 위에 각 각의 Guest OS를 올리는 형태로 관리가 되며, Container는 Host OS 위에서 각 각의 서비스들이 자원격리 기술을 통해 각 각의 Container로 분리되서 관리가 된다. (namespace: 커널에 관련된 영역을 분리, cgroups: 서버의 자원에 대한 분리)
컨테이너에서 Pod은 하나의 배포 단위를 말하며, 각 각의 micro service단위로 쪼개진 컨테이너를 배포 단위에 따라 각 각의 Pod으로 묶어서 관리를 하게 된다.
Kubernetes 첫 실습
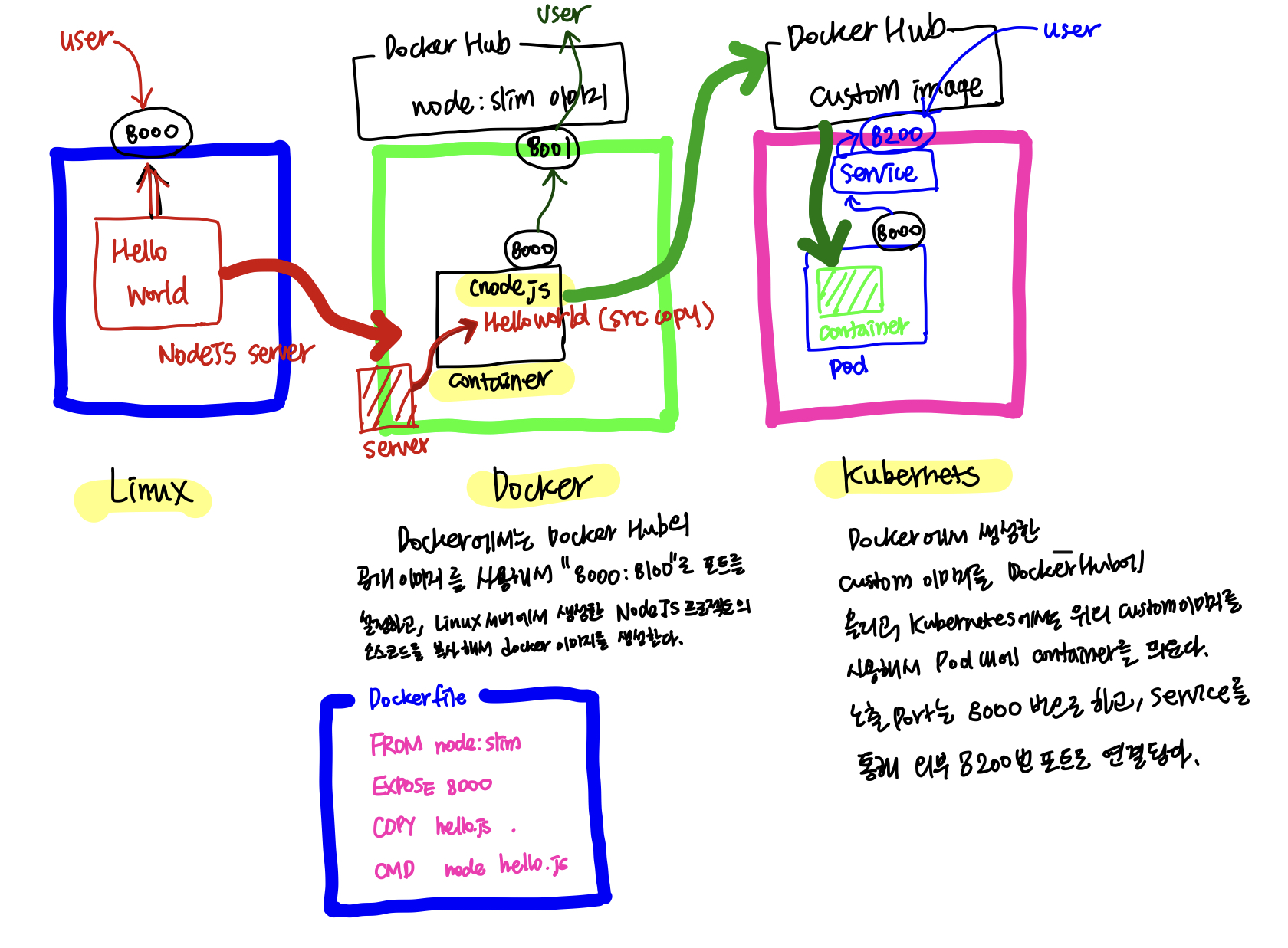
그래도 이전에 도커에 대해서 어느정도 기본적인 학습을 해서 위의 구조도에 대한 전반적인 이해는 된다.
실습에 있어서, 우선 간단한 nodejs 프로젝트를 생성해주고, 커스텀 이미지를 생성할때 프로젝트의 코드를 COPY해서 새로운 도커 이미지를 빌드할 것이기 때문에 프로젝트 폴더 내에 프로젝트에 필요한 기본 구성을 한 다음에 .dockerignore파일과 Dockerfile을 작성해준다.
Dockerfile
1 | FROM node:slim |
파일이 준비된 다음에는 docker build -t [dockerhub username]/[image name] . 명령으로 도커 커스텀 이미지를 생성해준다.
컨테이너가 구동된 상태에서 접속을 하기위해서는 docker exec -it [container id] /bin/bash로 내부 컨테이너로 접속할 수 있다.
이제 이미지가 생성이 되었으니, 위 환경 구성에서와 같이 8000번 포트를 local의 8100번 포트와 mapping 해준다.(8100:8000)
local에서 8100번을 통해 컨테이너가 잘 구동되었는지 페이지를 확인한다.
이제 커스텀해서 생성한 도커 이미지를 Docker Hub에 올린다.
1 | $docker login |
docker Hub에 업로드한 이미지가 확인이 되었으면, 이제 Kubernetes에서 사용할 컨테이너의 이미지가 준비된 것이다.
쿠버네티스에서는 dashboard를 제공하기 때문에 실습할때 활용하도록 한다. 실제 운영환경에서는 dashboard를 사용하지 않도록 권고한다.(보안적인 부분이 직관적으로 볼 수 있기 때문에 해킹의 우려가 있다)
Kubernetes의 Pod를 통해서 컨테이너 구동시키기
이제 본격적으로 앞서 생성한 컨테이너 이미지를 활용해서 Pod를 통해 컨테이너를 구동시킬 것이다.
우선 쿠버네티스 실습을 위해서 Kubernetes 클러스터를 위한 환경구성을 해야한다.
Pod를 띄워주기 위한 *.yml 파일
아래 스크립트를 복사해서 dashboard의 +생성을 클릭해서 쿠버네티스의 objects을 생성할 수 있다.
Pod를 생성한 후에는 파드(Pod)메뉴를 통해서 현재 생성된 파드의 상태정보를 확인할 수 있다.
그 다음에 EXEC 버튼을 클릭해서 파드에 생성된 컨테이너에 직접 내부에 접근할 수 있다.
1 | apiVersion: v1 |
이렇게 생성된 Pod를 외부에서 접근할 수 있도록 서비스를 만들어야 한다.
Service도 Pod와 동일한 방법으로 object를 생성해준다.
생성이 된 Service를 확인해보면, 외부 엔드포인트 정보가 있는데, 엔드포인트를 통해서 외부에서 파드에 접근할 수 있다.
Service를 띄워주기 위한 *.yml 파일
1 | apiVersion: v1 |
쿠버네티스의 기능 전반에 대해 살펴보기
서버 한 대는 Master로 사용하고, 다른 서버들은 Node로써 Master에 연결해서 사용한다. 이렇게 쿠버네티스 클러스터가 구성이 된다.
Master는 쿠버네티스 전반을 컨트롤하는 역할을 하고, 나머지 노드들은 자원을 제공해주는 역할을 한다.
만약 클러스터 자원을 늘리고 싶다면, 노드들을 늘려주면 된다.
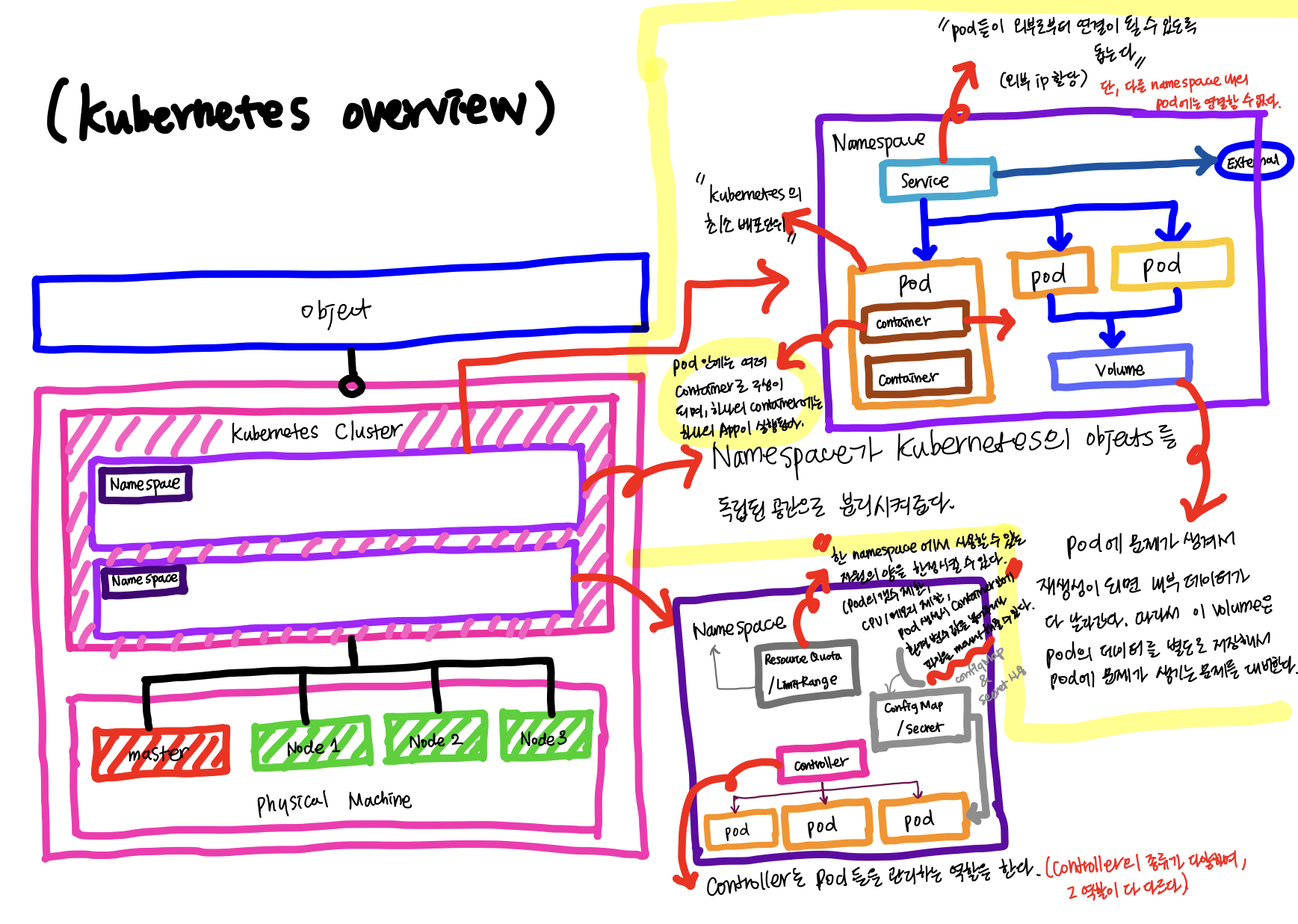
위의 쿠버네티스의 Controller의 세부 구조를 보면, 아래와 같다.
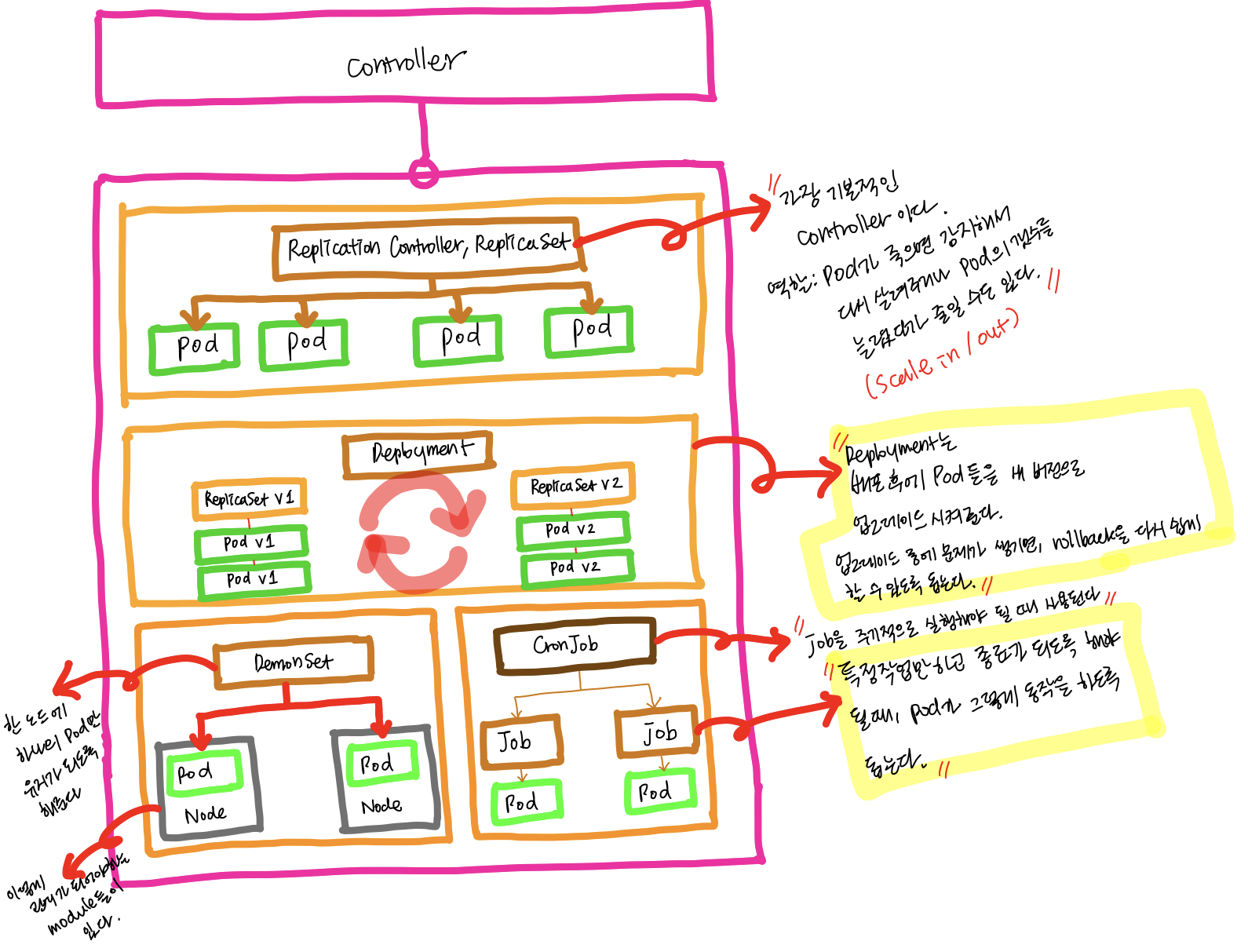
이제 막 쿠버네티스를 배우는 단계라 아직 이해가 되지 않는 부분이 많지만, 일단 Kubernetes 클러스터의 전체적인 구조에 대해서 머릿속으로 그려가면서 부분 지식을 습득해야겠다.