이번 포스팅에서는 앞으로 하게 될 실습의 전체 구성도를 정리하고, Amazon API Gateway를 구성했던 내용에 대해서 정리해본다. (앞으로 API Gateway를 설정할때 remind를 하기 위해 참고하도록 하자)
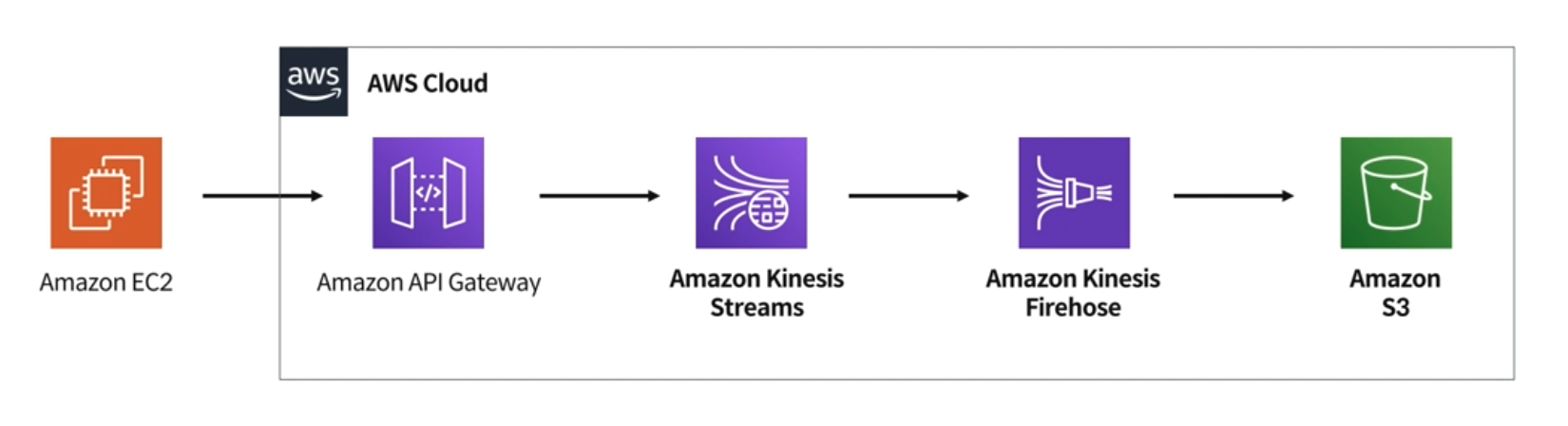
두 번째 데이터 수집 파이프라인 구축 실습 구성도
이번 실습에서는 EC2(외부 데이터 발생 source 부분)를 하나 준비해서 데이터를 발생시키고, 발생시킨 데이터를 API Gateway를 통해서 Amazon Kinesis Stream으로 넘겨주고, Amazon Kinesis Firehose에서 Stream의 데이터를 받아서 Amazon S3의 특정 폴더에 최종적으로 저장을 해주는 flow를 구성한다.
(Mac/Window환경에서는 curl명령을 사용해서 외부에서 데이터를 발생시킬 수 있다)
API Gateway 구성하기
시스템을 구성할때에는 버전관리가 필요하다. 나중에 버전관리에 따른 업그레이드된 버전을 적용해야되는 경우가 생기기 때문이다. 새로운 API를 생성한 다음에 리소스 - [작업] - [리소스 생성] - [새 하위 리소스] - 리소스 이름 : v1 (버전 이름 지정)
[API 메소드 생성]
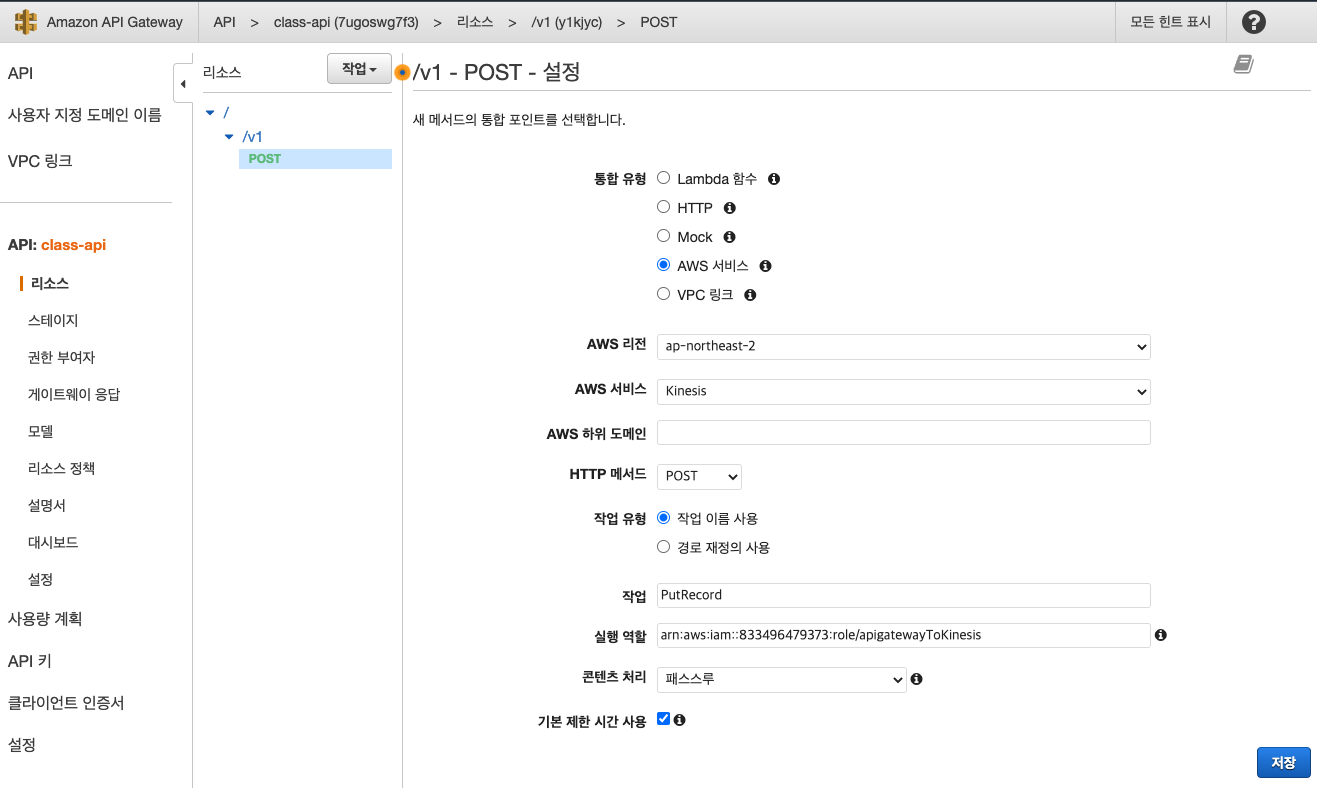
외부에서는 오는 이벤트를 받을때에는 POST 방식으로 받는다. 기본적으로 들어온 데이터는 Lambda로 처리하기 때문에 Lambda가 default로 선택이 되어있다. 하지만, 이번 실습에서는 Kinesis Stream에 연결을 해줄 것이기 때문에 AWS 서비스를 선택해준다. (통합 유형)
AWS 리전 : ap-northeast-2
AWS 서비스 : Kinesis
HTTP 메서드 : 내부 서비스간에 통신하는 부분 정의(POST)
작업 : API Gateway에서 Kinesis로 넘길때 약속된 작업 명령어 (대소문자 구분) PutRecord
실행역할 : IAM (AWS안에서 실행되는 서비스들도 role을 가지고 있기 때문에 권한 없이 다른 서비스에 명령어를 날리거나, 실행을 요청할 수 없다. 따라서 항상 role을 만들어서 서비스에 권한을 줘야 다른 서비스에 action을 할 수 있다)
[역할 만들기]
=> IAM - [역할 만들기] - 역할 이름 : apigatewayToKinesis 역할이 추가되면, 생성된 역할에서 [정책 생성] - "정책 연결"을 선택해서, "AmazonKinesisFullAccess"를 선택 - "정책 연결" - 생성된 역할 페이지에서 ARN 주소를 복사를 해준다.
통합요청 부분이 메시지를 처리하는 부분이고, Kinesis에서 정상처리되면, 200 Response code를 반환해준다.
[통합요청 부분 추가 처리]
통합 요청부분은 메시지가 왔을 때 어떻게 처리할지 정의하는 부분으로 추가적인 작업이 필요하다.
(1) Type은 JSON으로 정의하도록 한다. HTTP 헤더에 아래 정보를 추가해준다.
1 2
이름 : Content-Type Mapped from : 'application/x-amz-json-1.1'
(2) 매핑 템플릿에서 패스스루 방식에서 매핑 템플릿 추가로 application/json를 해준다.
(3) velocity programming language를 사용해서 템플릿을 생성해준다. 아래의 스크립트를 참고하도록 하자.
enter값을 넣는 이유는 메시지 데이터값이 오면, queue에 담겼다가 오기 때문에 enter가 없으면 다음 row로 넘어가지 않기 때문에 넣어준다. 한 줄 한 줄씩 받아온 메시지 데이터를 읽어서 Kinesis에 RESTFul 방식으로 넘겨주는 Script이다.
Data 자체를 base64로 encoding한다. (이유는 우리가 흔히 쓰는 이메일도 base64로 encoding되어있다. web contents는 특수한 기호가 많기 때문에 base64로 encoding하지 않으면 전문이 갈때 특수문자에 의해서 원하지 않은 부분에서 짤리는 상황이 발생한다)
Partitionkey는 Shard를 3개를 나눈다고 가정할 때 Kinesis가 Shard의 index 순서에 맞게 만들어주게 하기 위해서 정의한다.
StreamName은 어느 스트림으로 보낼지에 대한 이름을 정의한다.
(4) API 배포 작업 상단에 작업 드롭다운 메뉴에서 API 작업 - API 배포를 클릭해서 생성한 API 메서도를 배포해준다.
배포 스테이지 : [새 스테이지] 스테이지 이름 : PROD
최종적으로 서비스에 대한 END POINT도 확인할 수 있다.
(5) curl명령어를 사용해서 END POINT로 생성한 데이터를 API Gateway END POINT를 통해 Kinesis Stream으로 넘겨준다.
1
curl -d "{\"value\":\"30\",\"type\":\"Tip 3\"}" -H "Content-Type: application/json" -X POST https://xxxxxxxx.execute-api.ap-northeast-2.amazonaws.com/PROD/v1
(6) 서비스 모니터링 서비스를 한 개 만들때마다 모니터링을 해줘야한다. API Gateway와 같은 경우에는 로그가 CloudWatch에 떨어진다. Api Gateway에 CloudWatch에 대한 설정을 해줘야한다.
[설정] - CloudWatch 로그 역할 ARN 입력 (IAM에서 CloudWatch 권한이 추가되어있는 정책 ARN 입력)
(7) 배포된 API 경우에는 스테이지 항목에 올라가있기 때문에 스테이지에서 API 항목을 클릭한 뒤에 CloudWatch 설정에서 CloudWatch 로그 활성화를 체크하고 INFO 수준으로 체크해준다.
현재는 실습단계이기 때문에 CloudWatch에 로그가 쌓으는 것만 확인하고 바로 서비스를 disable한다. (별도 비용발생)
이번 포스팅에서는 앞으로 하게 될 실습의 전체 구성도를 정리하고, Amazon API Gateway를 구성했던 내용에 대해서 정리해본다. (앞으로 API Gateway를 설정할때 remind를 하기 위해 참고하도록 하자)
두 번째 데이터 수집 파이프라인 구축 실습 구성도
이번 실습에서는 EC2(외부 데이터 발생 source 부분)를 하나 준비해서 데이터를 발생시키고, 발생시킨 데이터를 API Gateway를 통해서 Amazon Kinesis Stream으로 넘겨주고, Amazon Kinesis Firehose에서 Stream의 데이터를 받아서 Amazon S3의 특정 폴더에 최종적으로 저장을 해주는 flow를 구성한다.
(Mac/Window환경에서는 curl명령을 사용해서 외부에서 데이터를 발생시킬 수 있다)
API Gateway 구성하기
시스템을 구성할때에는 버전관리가 필요하다. 나중에 버전관리에 따른 업그레이드된 버전을 적용해야되는 경우가 생기기 때문이다. 새로운 API를 생성한 다음에 리소스 - [작업] - [리소스 생성] - [새 하위 리소스] - 리소스 이름 : v1 (버전 이름 지정)
[API 메소드 생성]
외부에서는 오는 이벤트를 받을때에는 POST 방식으로 받는다. 기본적으로 들어온 데이터는 Lambda로 처리하기 때문에 Lambda가 default로 선택이 되어있다. 하지만, 이번 실습에서는 Kinesis Stream에 연결을 해줄 것이기 때문에 AWS 서비스를 선택해준다. (통합 유형)
AWS 리전 : ap-northeast-2
AWS 서비스 : Kinesis
HTTP 메서드 : 내부 서비스간에 통신하는 부분 정의(POST)
작업 : API Gateway에서 Kinesis로 넘길때 약속된 작업 명령어 (대소문자 구분) PutRecord
실행역할 : IAM (AWS안에서 실행되는 서비스들도 role을 가지고 있기 때문에 권한 없이 다른 서비스에 명령어를 날리거나, 실행을 요청할 수 없다. 따라서 항상 role을 만들어서 서비스에 권한을 줘야 다른 서비스에 action을 할 수 있다)
이번 포스팅에서는 앞으로 실습할때 사용하게 될 AWS인 API Gateway,Kinesis Stream, Kinesis Firehose에 대해서 공부한 내용을 정리해보겠다.
두 번째 실습내용
이번 실습에서는 AWS 서비스인 Object Storage 서비스 S3를 이해하고, 대규모 데이터 스트림을 실시간으로 수집하고 처리하는 Kinesis Stream을 사용하고 이해한다. 더 나아가 이전 포스팅에서 정리한 것처럼, 1주차에 배운 데이터 온프레미스 수집방법과 클라우드상에서 데이터를 수집하는 방법의 차이를 이해한다.
(1) 실습내용 : AWS 패키지들을 이용한 데이터 수집 실습
(2) 실습 구성 : Api-Gateway, Kinesis Stream, Firehose, S3의 이해 (Simple한 데이터 수집방법 / 구체적으로 왜 이렇게 파이프라인을 구성했는지에 대해 이해한다)
(3) 실습환경 설정 : Kinesis Stream, Firehose, S3 설정하기
(4) 구성한 실습환경에서 데이터 수집 : AWS 서비스에서 데이터 수집하기
개인 실습에서는 웹/앱에서 데이터를 발생시킬 수 없기 때문에 간단하게 EC2에서 웹 접속하는 것과 똑같은 환경을 구성한다. (CLI에서 curl명령을 통해서 데이터를 생성하고, 테스트용으로 만든 데이터를 S3에 저장해서 실습한다)
API Gateway
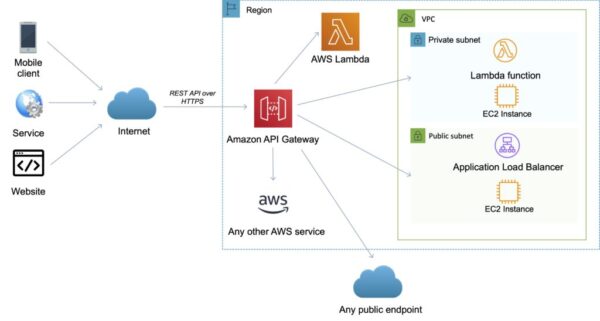
AWS에서 앱이나 웹을 개발할 경우에는 외부의 이벤트들(모바일/서비스/웹)을 AWS 서비스로 받아들이는 관문으로 이해하면 된다.
이벤트 같은 경우에는 백엔드에서 처리해도 되지만, 앱에서 발생하는 이벤트 중에서 백엔드의 자체 프로세스에서 처리되지 않는 이벤트(화면상에서 전환되는 이벤트)같은 이벤트도 처리하기 위해서 API Gateway를 사용해서 이벤트를 AWS 클라우드 안으로 받아들이도록 처리하기도 한다.
관련 서비스 050, 애드브릭스 등과 같이 최근 클라우드상에서 Parse 형태로 서비스되고 있는 서비스들이 있는데, 이벤트가 발생하면 바로 회사로 이벤트를 넘겨주는 데이터들도 있다. 외부에서 발생하는 이런 데이터들을 내제화할때 사용을 꼭 해야되는 시스템으로 API Gateway가 사용된다.
모바일 및 웹 어플리케이션에서 AWS 서비스에 액세스할 수 있는 RESTFul API를 제공을 하며, 사용자는 RESTFul API를 생성, 구성, 호스팅하여, 어플리케이션의 AWS 클라우드 액세스를 지원한다.
Amazon Redshift는 빅 데이터 분석에 사용할 수 있는 데이터 웨어하우징 서비스이다. 이 서비스는 여러 원본에서 데이터를 수집하여, 데이터 간의 관계 및 추세를 파악하는데 도움이 되는 기능을 제공한다.
때로는 비즈니스 요구 사항은 현재 진행중인 일이 아닌, 과거에 일어난 일과 연결되기도 한다. 물론 모든 곳에 단일 데이터베이스를 사용하는 만능 모델을 사용할 수도 있지만, 빠른 속도와 실시간 수집 및 쿼리를 고려해 설계된 현대적인 데이터베이스가 적절하지 않은 경우도 있다. 기록/분석의 문제점은 쿼리를 요청한 시점에 데이터가 수집을 멈추지 않고 지속한다는 것이다. 그리고 최신 원격 분석과 IoT의 폭발적 증가 때문에 데이터는 결국 최고 용량의 기존 관계형 데이터베이스도 감당할 수 없는 양이 될 것이다. 더 나아가 데이터의 다양성도 문제가 될 수 있는데, 재고,금융 및 소매 영업 시스템과 같은 다양한 데이터 장소에서 오는 데이터를 상대로 BI(Business Intelligence) 프로젝트를 실행하는 경우, 여러 데이터 베이스에 단일 쿼리를 사용하는 것은 기존 데이터베이스에서는 쉽게 처리하지 못한다.
데이터가 너무 복잡해서 기존 관계형 데이터베이스로 처리하기 어려워지면, DW로 처리하게 되는데, DW는 이러한 유형의 빅데이터용으로 특별히 제작되었고, 사용자는 운영 분석이 아닌 기록 분석을 살펴보게 된다.
기록이란, “지난 1시간동안 모든 점포에서 기록한 매출정보를 출력”과 같이 지난 1시간은 이제 과거이므로 현재 판매하는 건은 포함되지 않는다는 것을 의미한다. “지금 모든 점포에서의 매출은 어떻게 되지?”라는 질문과 비교해보면, 말하는 이 순간에도 결과는 바뀔 수 있으며, 비즈니스 질문이 과거를 향하다면 해당 BI에는 DW가 올바른 솔루션이 될 수 있다.
DW팀이 엔진관리 대신에 데이터에만 집중할 수 있도록 나온 서비스가 바로 Amazon Redshift이다. 서비스로서의 데이터 웨어하우징 제품이다. 확장성이 매우 뛰어나며, 수 Petabyte 크기의 Redshift 노드도 흔하다. 실제로 Redshift Spectrum을 통해 데이터 레이크에서 실행되는 수 Exabyte 바이트의 비정형 데이터를 대상으로 단일 SQL 쿼리를 실행할 수 있다. 여기서 핵심읁 빅데이터 BI 솔루션이 필요할 때 Redshift를 이용하면 단일 API 호출로 작업을 시작할 수 있다는 것이다.
이번 포스팅에서는 이전에 작성했던 Python으로 작성한 MapReduce 코드를 HDP 2.6.5 환경에서 구동시켜볼 것이다. Hadoop을 사용하지 않고, local에 copy된 dataset을 가지고 로컬에서 실행해보고, Hadoop을 기반으로 실행해보는 두 가지 방법으로 실습을 해볼 것이다.
HDP2.6.5에서 MapReduce 실습환경 구축
[STEP1] 가장 먼저 VirtualBox에 올린 HDP2.6.5 OS Image를 구동시킨다.
[STEP2] Putty를 사용해서 가상 OS환경에 접속한다.
[Putty host/port configuration]
1 2
host: maria_dev@127.0.0.1 port: 2222
[STEP3] PIP 설치를 위한 SETUP
1 2 3 4 5 6 7 8 9 10 11 12 13
# root 계정으로 switch
$su root # root account initial password : hadoop
$yum-config-manager --save --setopt=HDP-SOLR-2.6-100.skip_if_unavailable=true # HDP Solar라는 저장소를 무시하고 설치하기 위한 configuration
$yum install https://repo.ius.io/ius-release-el7.rpm https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # IUS package를 수동으로 설치
이번 포스팅에서는 AWS의 가장 기초적인 자격증인 Practitioner 자격증 공부를 하면서, 기록할 필요가 있다고 생각되는 내용을 정리해보려고 한다.
현재 데이터 파이프라인 구축관련 공부를 하면서 AWS 서비스를 활용하여 실습을 하고 있는데, Storage와 Database 부분이 중요하다고 생각되기 때문에 우선적으로 이 부분에 대한 정리를 시작으로 다른 중요한 AWS 서비스들도 정리를 해나가보려고 한다.
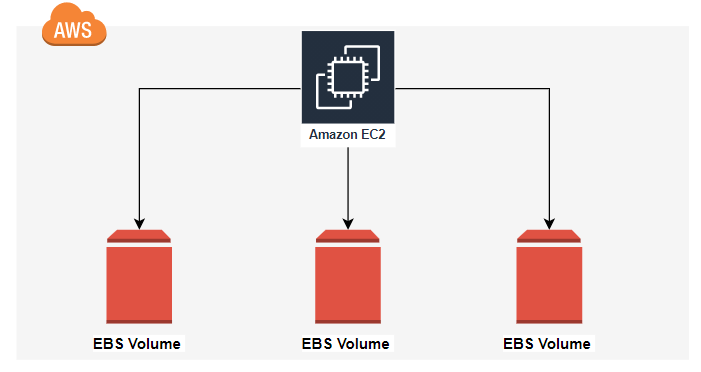
Amazon EBS(Amazon Elastic Block Storage)
데이터 파이프라인을 실습하면서 복수 개의 EC2 인스턴스를 생성하고, 계속 구동시켜놓으면 비용이 발생하기 때문에 사용하지 않을때에는 잠시 중지상태로 전환시켜두었다. 그런데 다시 구동시켰더니 내부에 저장해두었던 리소스들이 사라져있었다. 그 이유는 바로 EC2 인스턴스 가상 서버로, 내부 리소스는 Instance store volume이라는 블록 저장 공간에 저장을 하게 되는데, 중지 후 다시 재구동을 하게 되면 가상 서버는 베이스가 되는 부분이 재 생성되면서 기존에 사용되었던 instance store가 삭제되게 된다. (EC2의 임시 블록 수준 스토리지) 이러한 이유로 EC2 인스턴스를 중지후 재구동을 하여도 지속적으로 남기게 하기 위해, Amaozn EBS라는 블록 스토리지 솔루션이 등장했다. Amazon EBS는 EC2 인스턴스를 중지한 뒤에 다시 실행하여도 내부에서 저장하였던 리소스를 보존시켜준다. EC2 인스턴스에 EBS를 연결하려면 동일한 가용 영역(AZ)상에 있어야 한다. 저장은 하지만, 2GB EBS 볼륨을 프로비저닝해서 가득 채우게 되면, 볼륨이 자동으로 확장되지 않는다.
Snapshot을 지원해는데, 나중에 Snapshot에서 data를 복구할 수도 있다. (최대 16TiB, SSD, HDD 모두 제공) cf.SI 접두어 방식으로 하면, TB(테라바이트)인데, 이를 이진 접두어 방식으로 하면, TiB(테비바이트)가 된다.
이번 포스팅에서는 현재 진행중인 실습과 앞으로 하게 될 실습내용에 대한 간단한 회고에 대한 내용을 정리해보려고 한다.
이번 실습내용과 앞으로의 실습내용에 대한 이해 및 정리
우선 아직 마무리되지 않은 이번 실습과 앞으로 하게 될 한 번의 실습에 대해서 간단하게 짚고 넘어가고자 한다. 그냥 단순히 실습을 진행하는 것 보다는 왜 내가 이 실습을 하고 있는지에 대한 셀프 피드백이 필요하다. 단순히 실습을 하고 기록을 남기는 것에 그친다면 학습에 있어 방향을 잃을 수 있고, 향후에 내가 포트폴리오를 만들 때 분명 AWS 서비스 기반으로 Cloud Topologies를 구상할 것이기 때문이다. 아직 극초반이지만, 좀 더 앞으로의 큰 그림을 생각하고 학습해나가보자. 이러한 연습이 단순 포트폴리오 영역을 넘어서 나중에 업무에 있어서 빠르게 업무에 녹아드는데 도움이 될 것이라고 생각한다.
자 그럼 지금 하고 있는 첫 실습 내용과 앞으로 하게 될 실습내용을 연관지어서 한 번 정리를 해보자.
이번 포스팅에서는 Hadoop의 생태계에서 핵심이 되는 MapReduce의 세부동작에 대해서 정리해보려고 한다.
MapReduce에 동작에 대해서 이전 포스팅에서 정리를 했듯이 Mapper와 Reducer가 하는 일은 그렇게 복잡해보이지 않는다. 다만 Hadoop의 Cluster내에서 MapReducer가 동작하는 방식이 복잡하기 때문에 이 부분에 대해서 정리가 필요하다.
이전 포스팅에서 다뤘던 내용은 입력받은 데이터를 Mapper가 Key-Value 쌍으로 데이터를 Transformation해주고, 그 결과를 MapReduce가 자체적으로 셔플과 정렬(Shuffling and Sorting)해준다. 이후에 Reducer는 구조화된 정보를 전달받아서 최종 출력물을 생산해내는 역할을 한다.
만약에 정말로 큰 데이터 세트를 가진 클러스터를 운영한다면, 아마 처리 과정을 여러 컴퓨터에 배분하거나 각 노드에서 여러 작업에 걸쳐 진행을 할 것이다. MapReduce 작업을 세 개의 노드에 나눠서 Mapping작업을 한다고 가정한다면, 데이터에서 몇 줄은 첫 번째 노드에 보내서 처리하고, 나머지 데이터는 나머지 노드에 배분해서 처리할 것이다. 입력 데이터를 여러 파티션에 끼워 맞추고, 각 파티션에 작업 할당을 하게 되는 것이다. 바로 여기서 다른 파티션에 있는 데이터는 신경쓰지 않아도 되기 때문에 작업의 병렬화가 가능해진다. 최종적으로 각 각 작업 배분한 컴퓨터에서 작업이 끝나면 Hadoop은 정보를 잘 받아오고 마무리가 된다.
[MapReduce procedure 반복 숙지]
[STEP1 - Mapping] 클러스터의 각 노드로 대량의 데이터를 작은 블록으로 배분함으로써 key:value 쌍으로 전환하는 Mapping 처리과정을 배분할 수 있다.
[STEP2 - Shuffling and Sorting] 그 다음으로는 Shuffle & Sort작업인데, 앞서 key:value 쌍으로 Mapping하는 과정에서 복수 개의 key를 갖는 데이터가 생기기 때문에 이 과정을 통해서 같은 키 값끼리 모아서 Reducer로 보낼 데이터로 가공하게 된다. 이 과정은 MapReduce가 대신 수행을 하게 된다. 단순히 네트워크상에서 데이터를 주고 받는 형태가 아닌, 모든 정보를 merge sort하는 형태로 처리한다.
[STEP3 - Reducing] 최종적으로 Reducer 단계에서는 데이터를 Key 값을 기준으로 정렬된 세트를 Reducing하게 된다.
다시 정리하자면, Mapping단계에서는 입력된 데이터를 작은 block으로 쪼개서 클러스터 내의 여러 노드로 분산시키고, 셔플과 정렬 작업 이후에는 각 노드가 각 각의 세트를 담당하여 reducing하게 된다. 클러스터 내의 각 노드에서 reducing 작업까지 완료된 데이터들은 Hadoop에 의해 최종적으로 수집되어 마무리된다.
이번 포스팅에서는 웹 서버 전용 EC2 인스턴스를 생성하고, 생성한 EC2 인스턴스에 httpd 설치 및 실행을 해보고 간단한 테스트 웹 페이지를 띄워보는 실습을 해본다.
Httpd
우선 웹 서버 전용 EC2 인스턴스를 생성한 뒤에 해당 EC2 인스턴스에 Httpd demon을 설치해줬다. 선택한 AMI가 CentOS와 비슷한 이미지를 가지고 만들었기 때문에 설치한 httpd 서비스가 EC2 lifting시에 자동으로 로드되게 하기 위해서는 서비스를 등록해야되는데, 설치하면 default로 서비스에 등록이 되기 때문에 아래와 같은 프로세스로 서비스 설치 및 시작을 하면 된다. 설치된 Httpd에 기본 Home 디렉토리(/var/www/html)가 있는데, 해당 위치에 웹 기본이 되는 파일(index.html)을 생성해서 간단하게 웹 페이지 테스트를 할 수 있다.