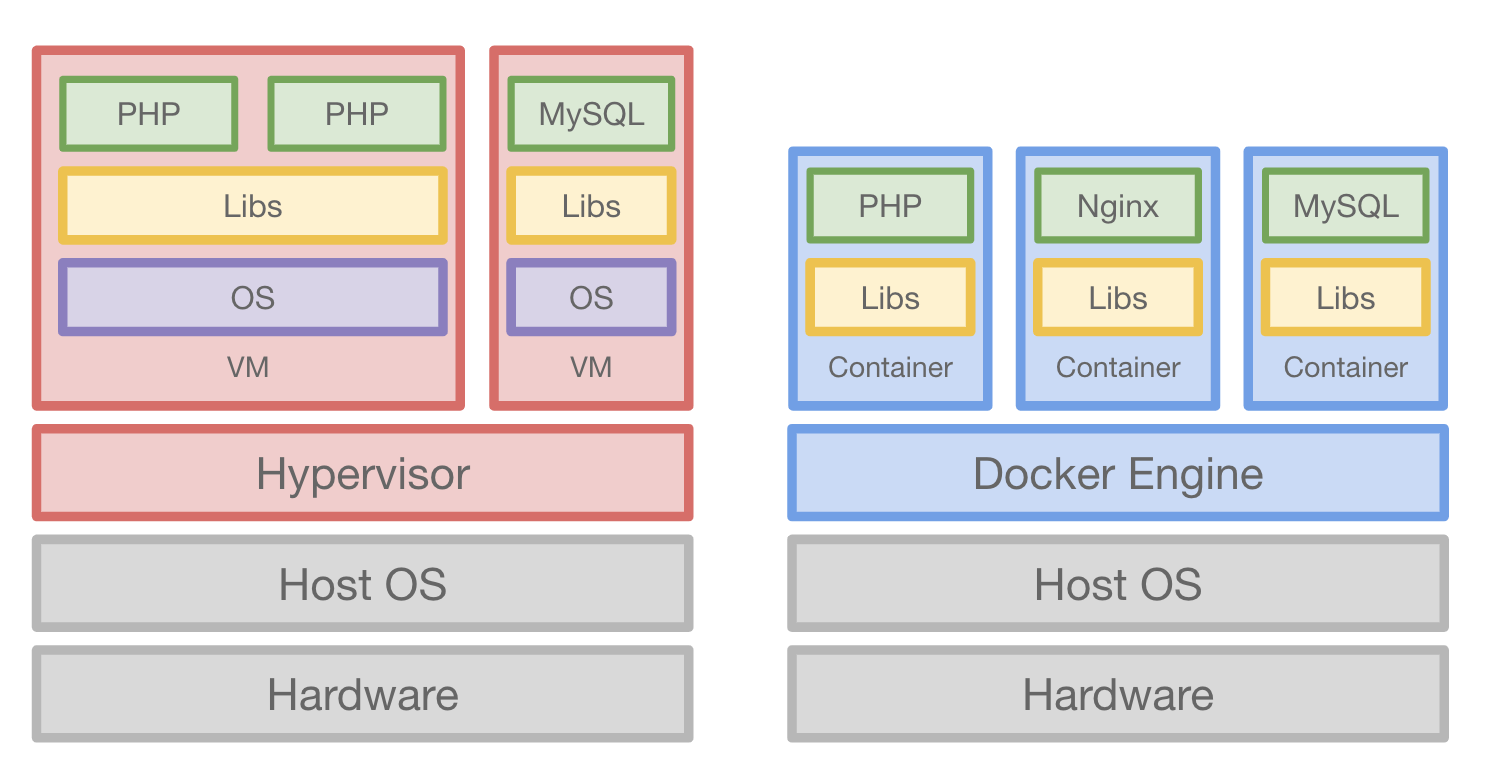
이번 포스팅에서는 도커에 대해 학습한 내용에 대해서 정리하려고 한다.
도커를 이해하기 위해서는 서버를 관리하는 것에서부터 시작해야 되는데, 서버관리는 내부적으로 매우 복잡하고, 각 각의 과정이 서로 종속되어있다.
전통적인 서버 관리 방식으로 비춰보면, 서버에 특정 서비스를 설치하고자 할 때, 환경적인 제약으로 인하여 예상하지 못한 문제가 발생하기도 하고, 지속적으로 바뀌는 서버 및 개발 환경으로 인해 지속적으로 기존의 서버를 다시 설정해야 되는 경우가 생겨서, 서버의 유연성이 많이 떨어진다.
Docker의 등장
위와같은 전통적인 서버 관리 방식에서의 환경적 제약으로 인한 설정 오류와 유연한 서버 환경 교체에 대한 솔루션으로 등장하게 된 것이 바로 도커(Docker)라는 친구이다.
Docker를 사용하면, 어떠한 서비스(프로그램)을 하나의 컨테이너로 만들어서 관리를 할 수 있다.
그리고 만들어진 컨테이너는 어떤 환경적인 제약도 없이 어디서든 돌아가게 된다.(AWS, AZURE, GOOGLE CLOUD, KT UCLOUD, NAVER CLOUD PLATFORM 등…)
Docker가 등장하기 전에는 서버내에서 각 각의 서비스가 다른 버전의 Package를 사용하는 경우, 버전 변경에 있어 어려움이 있었다. 그로인해 배포를 위한 전체 과정 중에 한 부분이라도 문제가 생기게 되면 서비스가 구동이 되지 않는 문제에 직면하기도 하고, 전통적인 서버관리의 방법에는 많은 문제가 있었다.
서버 관리 방법의 변천
위의 전통적인 서버관리 방식에서 생겨나게 된 문제를 개선하기 위해서 가장 먼저 도입된 것이 바로 "서버배포를 위한 메뉴얼화(문서화)"였다. 하지만, 잘 정리된 문서를 보고 따라하더라도 제대로 동작하지않는 경우도 있었고, 문저 정리가 중간에 잘 안되는 경우도 많았다. 그리고 특정 OS를 타겟으로 작성된 문서의 경우, 다른 OS에서 예외가 발생하는 경우도 많이 생겼다.
이러한 문서관리에 문제가 많아 생겨나게 된 것이 바로 "상태관리 도구(CHEF, PUPPET LABS, ANSIBLE)"이다. 이 상태관리 도구는 각 서버 설정의 단계를 스크립트로 작성을 하고 관리를 하기 때문에 스크립트를 실행함으로써 마치 서버 관리자가 STEP BY STEP으로 명령어를 작성한 것과 같은 효과를 준다.
이렇게 코드로 관리함으로써 다른 관리자들과 협업도 가능하고, 버전관리도 가능하며, 코드이기 때문에 깃과 같은 저장소로 공유도 가능하다. 하지만 상태관리 도구를 사용함에 있어 러닝커브가 높다는 문제와 한 서버에 다른 버전의 동일 서비스를 설치할 때 문제가 있다는 것을 알게 되었다.
Read More