Passport.js를 활용한 로그인 흐름
아래는 passport-local을 사용한 일반 로그인 과정의 예시이다.
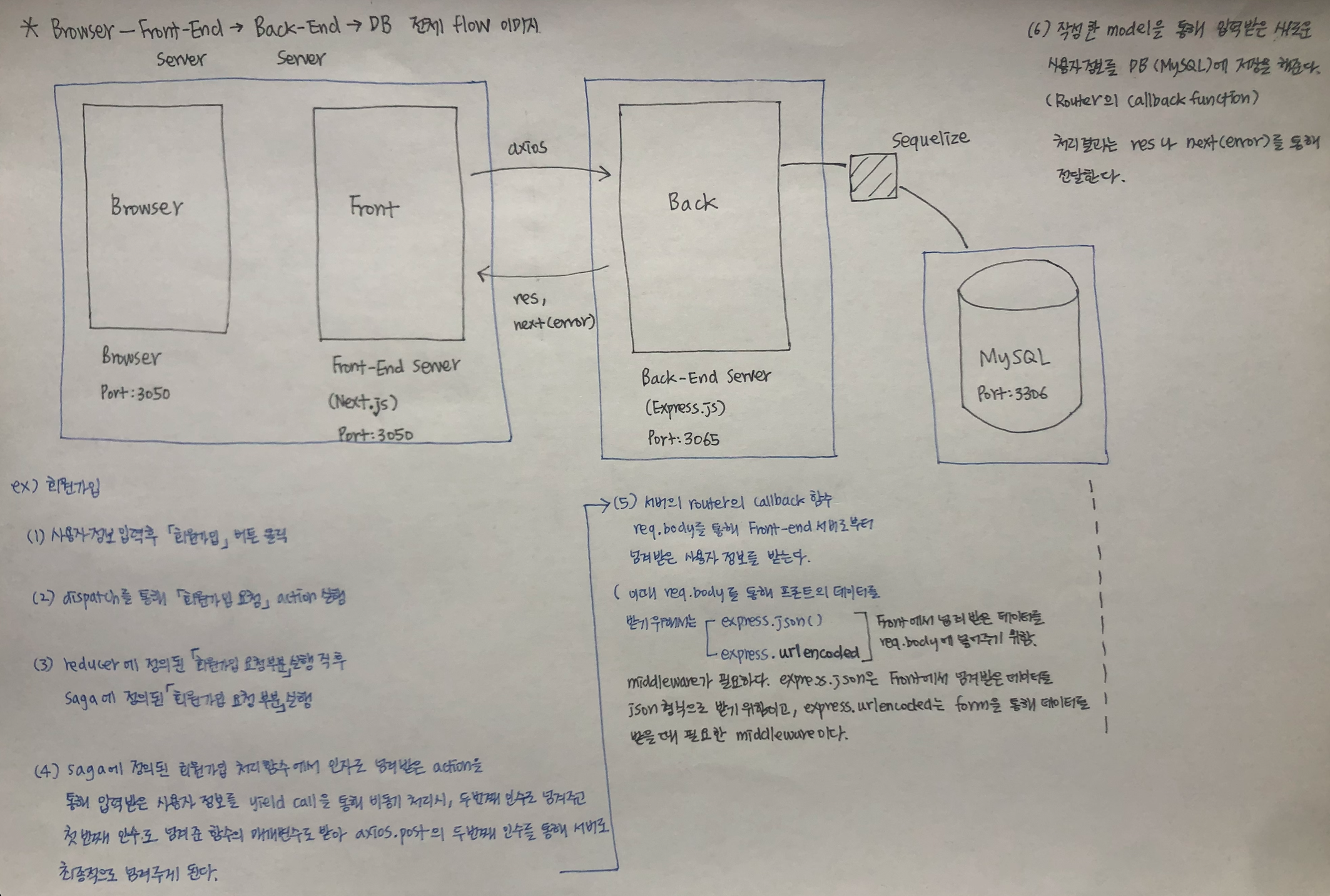
Front-End
(1) 로그인 폼에 이메일과 비밀번호를 입력
(2) saga의 로그인 함수 실행
Back-End
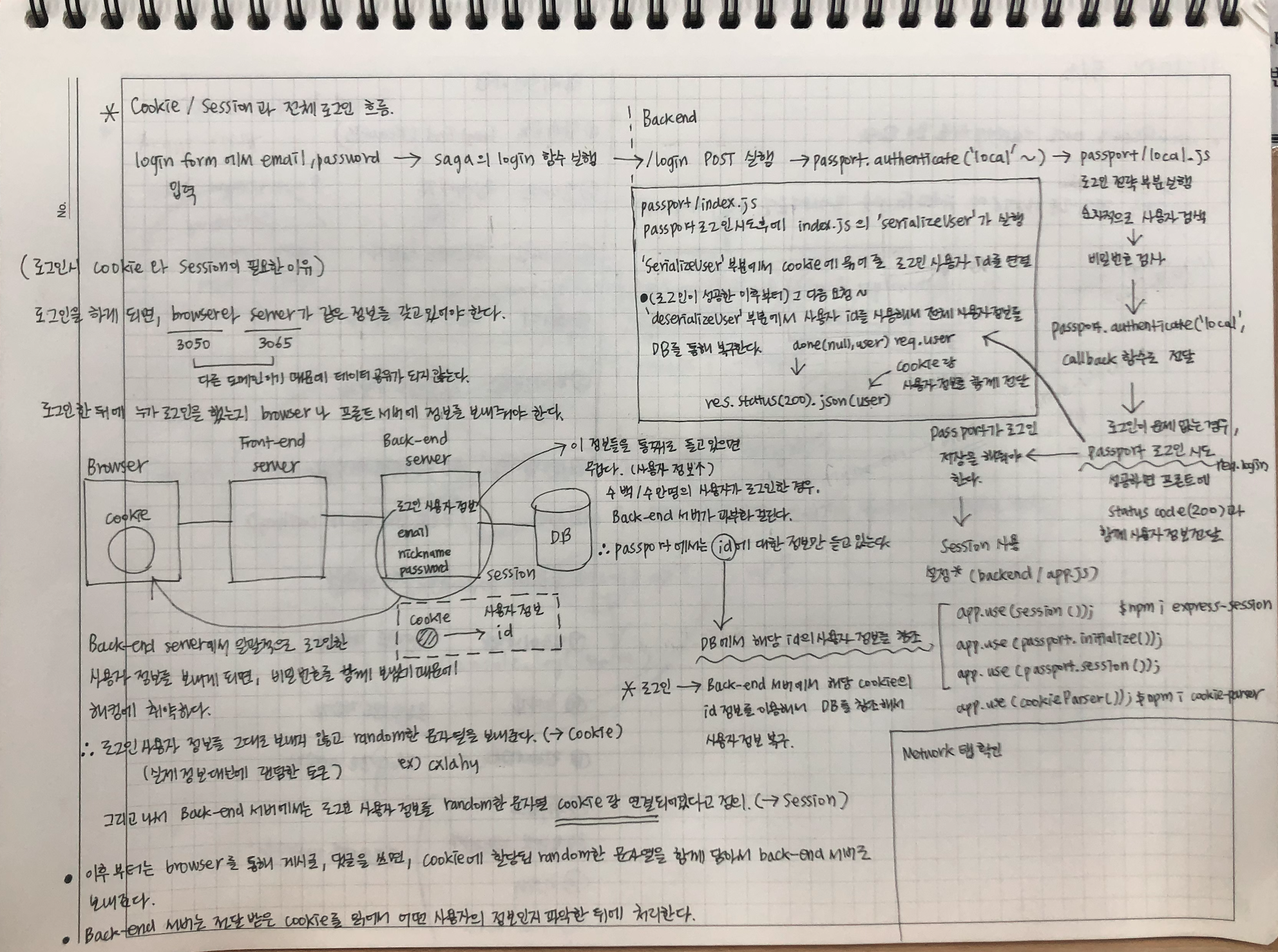
(3) login POST router 실행
(4) passport.authenticate(‘local’, …) 부분이 실행
(5) passport/local.js 로그인 전략 부분이 실행
(6) (5)의 결과가 passport.authenticate(‘local’, …) 부분의 callback 함수로 전달되고, 로그인에 문제가 없는 경우, passport 로그인 시도(req.login)
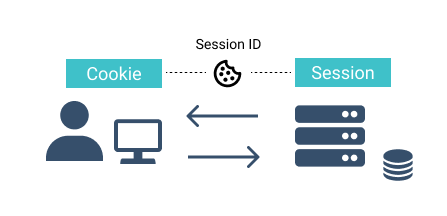
(7) passport/index.js의 serializeUser부분이 실행된다.serializeUser부분에서는 cookie에 묶어 줄 로그인 사용자 id를 전달한다.
deserializeUser부분은 로그인이 성공한 이후부터의 요청부터 router가 실행되기 이전에 실행된다.
deserializeUser부분이 실행되면, 저장되었던 사용자의 id를 토대로 사용자 정보를 복구해서 done(null, user)를 통해 req.user로 사용자 정보를 전달한다.
이를통해 router에서는 req.user로 사용자 정보의 참조가 가능해진다.
(8) 내부적으로 header를 통해 Front-End로 전달할 cookie 정보를 전달한다.
(9) Cookie 정보와 함께 Front-End로 사용자 정보를 전달한다.
노트필기 참고