이번 포스팅에서는 본격적으로 Hadoop이라는 녀석의 개요와 역사 그리고 생태계에 대해 알아보고 본격적으로 설치를 해보는 것에 대해 작성해보려고 한다. 처음이라 마냥 어렵게 느껴지지만, 이 친구도 이 세상의 많은 기술들 중에 하나이며, 다 이유가 있어서 태어난 친구이기 때문에 한 번 친해져보려고 한다.
재미있는 것은 이 하둡(Hadoop)이라는 녀석과 나는 초면이 아니라는 것이다. (그냥 과거에 스쳐간 인연..) 내가 라즈베리파이에 관심이 한창 있을 무렵에 구글링을 하다가 우연히 라즈베리파이로 슈퍼컴퓨터를 만든 사람이 올린 사진을 보았었는데, 그때 어떻게 만들었는지 너무 궁금해서 이것 저것 찾아보다가 컴퓨터 클러스터링 기술과 관련된 내용을 보았었는데, 이 곳에서 데이터 분산저장하는 기술로 이 하둡(Hadoop)이라는 친구에 대한 내용이 있었다. 딱 여기까지..그때는 컴퓨터로 클러스터링(병렬화)한다는 내용과 이런 내용들이 마냥 어렵게만 느껴져서 이 친구와의 인연은 딱 거기서 마무리되었었다. 그런데 이번에 데이터 엔지니어관련 공부를 하면서 인연의 끈이 있었던 것인지, 이렇게 다시 좀 더 딥하게 공부할 수 있는 기회가 되었다.
자, 이제 컴퓨터 클러스터의 방대한 데이터 세트를 변형하고 분석하는 강력한 도구인 하둡(Hadoop)과 친해져보도록 하자.
HDP(Hortonworks Data Platform)?
분산 스토리지 및 대규모 멀티 소스 데이터 세트 처리가 가능한 오픈소스 프레임워크이다. 이 프레임워크를 설치하는 이유는 이 프레임워크에 Hadoop이 이미 설치가되어있고, 관련 기술들도 일괄 설치가 되어있다. 그래서 나와 같이 하둡을 처음 접하는 사람에게는 적합하다. 간단하게 Virtualbox에 이미지를 올려서 실습하려고 했는데, 기본 RAM이 8GB로 설정이 되어있다.내가 휴대하면서 사용하고 있는 노트북의 RAM이 8GB라 어려울 것 같다는 느낌적인 느낌이 든다. 그래서 간단하게 AWS에 이미지를 올려서 사용을 해보기로 했다. (이번 기회에 RAM 32GB/SSD 1TB/i5 11세대 스펙이 되는 노트북 하나를 장만했다. 아무래도 향후 프로젝트를 진행하게 되면서 다양한 프로그램을 돌리게 될텐데, 사양이 안좋은 PC로 더 이상 작업을 이어가기 어려울 것 같아 이번 기회에 사양대비 저렴한 노트북 한 대를 구매하였다. 미래를 위한 일종의 투자라고 생각하자.)
# <class 'pandas.core.frame.DataFrame'> # RangeIndex: 4 entries, 0 to 3 # Data columns (total 4 columns): # # Column Non-Null Count Dtype # --- ------ -------------- ----- # 0 Bank Client ID 4 non-null int64 # 1 Bank Client Name 4 non-null object # 2 Net Worth [$] 4 non-null int64 # 3 Years with Bank 4 non-null int64 # dtypes: int64(3), object(1) # memory usage: 256.0+ bytes
Pandas series는 pd.Series constructor method의 parameter로 data를 넘겨주어 Pandas series를 정의하였다. Pandas DataFrame도 마찬가지로 위와같이 pd.DataFrame constructor method의 parameter로 python의 dictionary data를 넘겨주어 정의한다. Dictionary의 key/value에서 key값이 DataFrame의 column명이 되며, value의 리스트 타입의 값이 각 row의 값이 된다.
portfolio_df['price per share[$]'] portfolio_df['number of shares']
stocks_dollar_value = portfolio_df['price per share[$]'] * portfolio_df['number of shares'] print(stocks_dollar_value)
stocks_dollar_value.sum()
print('Total Portfolio Value = {}'.format(stocks_dollar_value.sum()))
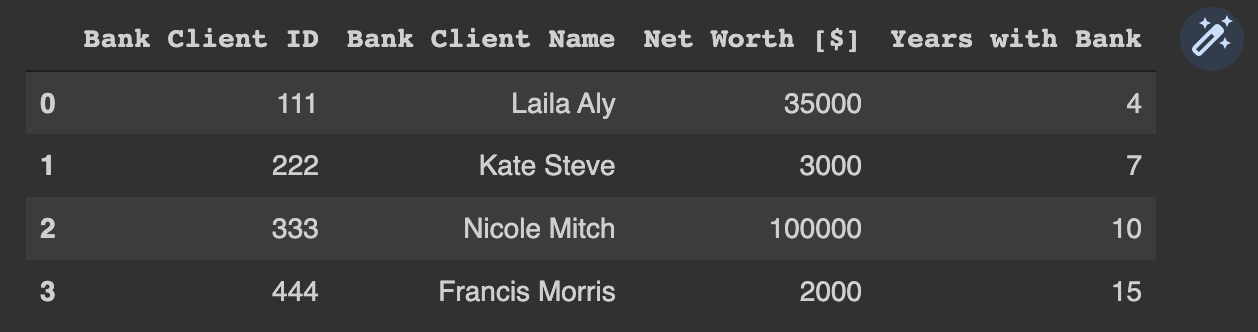
1. DEFINE A PANDAS DATAFRAME [2] 1초 import pandas as pd [3] 0초 # Let's define a two-dimensional Pandas DataFrame # Note that you can create a pandas dataframe from a python dictionary bank_client_df = pd.DataFrame({'Bank Client ID':[111, 222, 333, 444], 'Bank Client Name':['Laila Aly', 'Kate Steve', 'Nicole Mitch', 'Francis Morris'], 'Net Worth [$]':[35000, 3000, 100000, 2000], 'Years with Bank':[4, 7, 10, 15]}) bank_client_df
[4] 0초 # Let's obtain the data type type(bank_client_df) pandas.core.frame.DataFrame [7] 0초 # you can only view the first couple of rows using .head() bank_client_df.head(3)
[8] 0초 # you can only view the last couple of rows using .tail() bank_client_df.tail(1)
[9] 0초 # You can obtain the shape of the DataFrame (#rows, #columns) bank_client_df.shape (4, 4) [10] 0초 # Obtain DataFrame information bank_client_df.info() <class'pandas.core.frame.DataFrame'> RangeIndex: 4 entries, 0 to 3 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Bank Client ID 4 non-null int64 1 Bank Client Name 4 non-null object 2 Net Worth [$] 4 non-null int64 3 Years with Bank 4 non-null int64 dtypes: int64(3), object(1) memory usage: 256.0+ bytes
MINI CHALLENGE #1:
A porfolio contains a collection of securities such as stocks, bonds and ETFs. Define a dataframe named 'portfolio_df' that holds 3 different stock ticker symbols, number of shares, and price per share (feel free to choose any stocks) Calculate the total value of the porfolio including all stocks [20] portfolio_df = pd.DataFrame({ 'stocker ticker symbols': ['NVDA','MSFT','FB', 'AMZN'], 'number of shares': [3, 4, 9, 8], 'price per share[$]': [3500, 200, 300, 400] })
bank_df.to_csv('sample_output_noindex.csv', index = False) bank_df.to_csv('sample_output_noindex.csv', index = False, compression='gzip') # 용량을 줄인다.(압축 파일 *.csv.gz)
이번 포스팅에서는 학습했던 Pandas series에 대한 내용에 대해서 복습 및 실습을 하고, 그에 대한 내용을 정리해보고자 한다.
우선 Pandas란 데이터를 분석하고 각종 처리를 할 때 이용하는 파이썬 언어 기반의 라이브러리이다.Pandas로 데이터를 표현하는 두 가지 방법이 있는데 바로 여지까지 학습했던 시리즈(Series)라는 녀석과 데이터프레임(DataFrame)이란 놈이다.
이전 포스팅에서 두 개념(시리즈/데이터프레임)에 대해서 간단하게 다뤄보았지만, 아주간단하게 요약을 하자면,
시리즈(Series)란, 표(table)로 포멧팅되지 않은 리스트 형태로만 표현된 것으로, 열(Column)이 하나인 데이터 프레임이라고 생각하면 된다. 즉, 데이터 프레임은 여러 column의 series를 dictionary형태로 묶은 것이라고 볼 수 있다.
1 2 3 4 5 6 7
# DataFrame 예시
import pandas as pad
# DataFrame 생성 # 각 행과 열에들어가는 값은 숫자는 물론, 문자나 boolean 형태도 가능하다. pd.DataFrame({ 'Nanun' : [0, 3], 'Zoey' : [4, 2]}, index=['Apple', 'Banana'])
그래서 왜 Pandas를 사용하는데?
실제로 실무에서 분석하고 처리해야되는 데이터는 위에서 예시로 든 데이터와는 비교도 안 될 정도로 엄청 크고 방대할 것이다. 따라서 한눈에 보기 어려운 많은 양의 데이터가 어떤 개요(Overview)와 성향(Features)를 가지고 있고, 그 성향을 좀 더 잘 해석하기 위해서는 어떻게 데이터가 그룹화되어 표현되어야 하는지에 대한 남다른 해석능력도 필요하다. 그리고 데이터 중에서 유독 튀는 이상한 값은 없는지, 항상 확인하고 조작하는데 이 Pandas를 활용한다.
(Kaggle dataset)구글 플레이 스토어 앱 다운로드
CSV 파일을 Pandas를 이용해서 읽어보고 직접 조작해보도록 하겠다. dataset은 kaggle에서 제공해주는 데이터 중에서 개인적인 흥미에 따라 구글 플레이 스토어 앱 다운로드와 관련된 데이터셋 데이터 정보를 다운받았다.
1 2 3 4 5 6 7 8 9 10 11 12
import pandas as pd
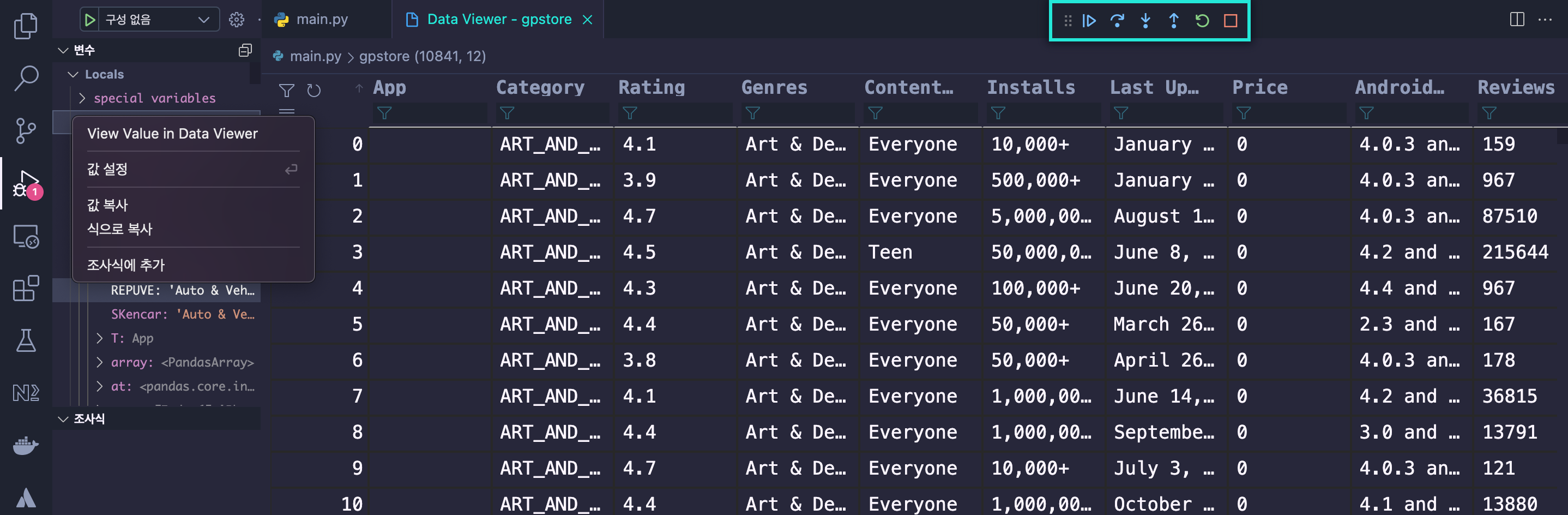
gpstore = pd.read_csv('./googleplaystore.csv', index_col=0) #vscode에서 DataViewer로 DataFrame의 데이터 리스트를 확인하기 위해서는 데이터가 출력되는 부분에 Break Point를 두고, #"실행 및 버그"에서 활성화 세션의 "변수" 영역에서 Break Point영역 변수명에 마우스 우측클릭해서 "View Value in Data Viewer" 항목을 선택한다. print(gpstore)
#.shape를 통해 (rows x columns)를 확인할 수 있다. print(gpstore.shape) #[10841 rows x 12 columns]
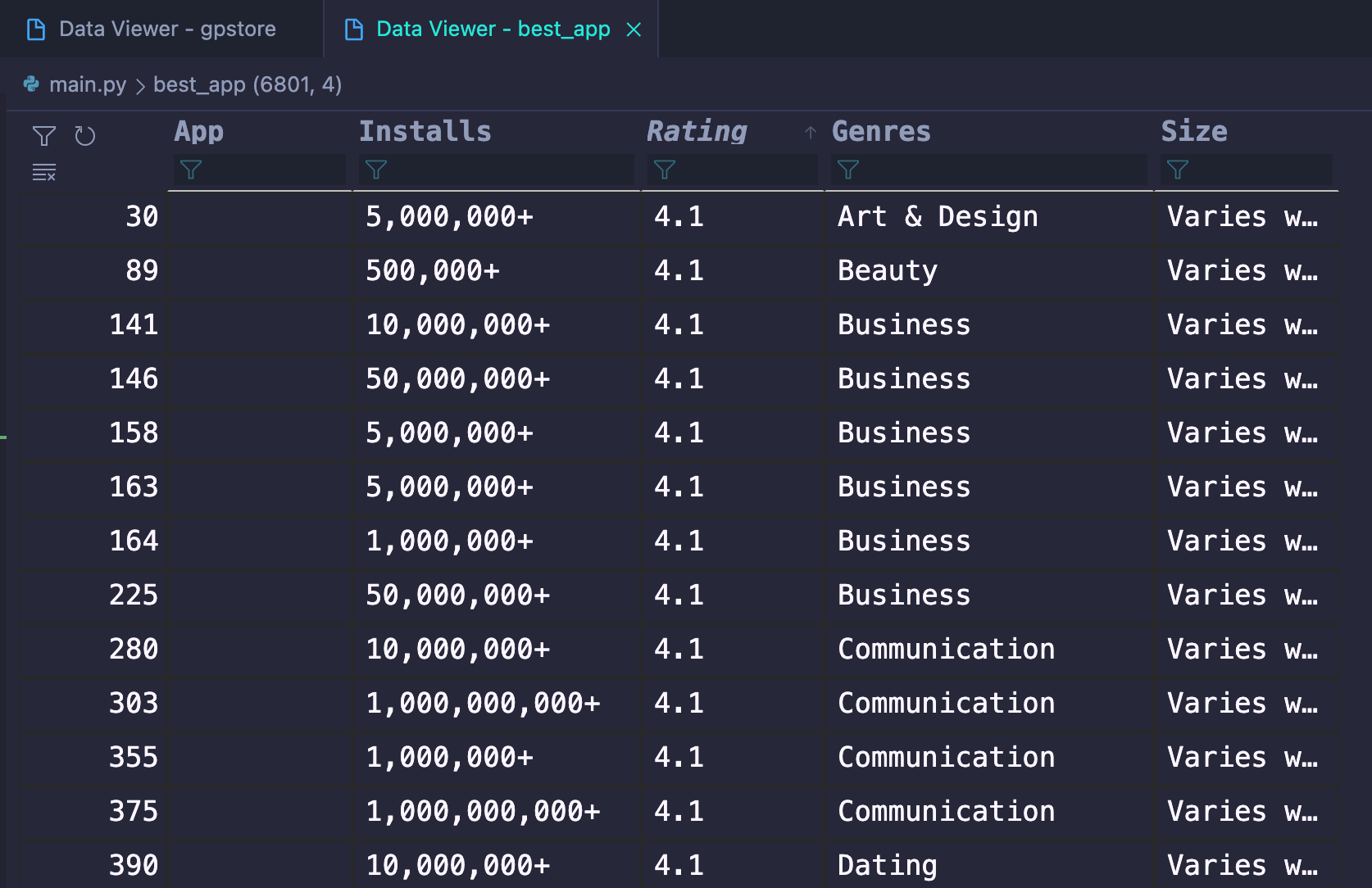
# 구글플레이 스토어에서 다운받은 앱들 중에서 평점이 4.0 이상인 것들만 Genres, Rating, Installs, Size 항목으로 분류해서 나타낼 수 있도록 DataFrame 구성 best_app = gpstore.loc[gpstore.Rating > 4.0, ['Genres', 'Rating', 'Installs', 'Size']]
print(best_app)
# 평점이 4.0이 넘는 구글 플레이스토어의 앱의 수 (6801) print(best_app.count())
이번 포스팅에서는 이전에 포스팅하였던 지도학습(Supervised Learning)의 학습 과정에 대해서 좀 더 구체적으로 정리를 해보고자 한다.
지도학습(Supervised Learning) 학습과정 3단계
1단계 데이터 수집 및 특징 추출하기
머신러닝의 지도학습 유형에서는 (X,Y)에서 output에 해당하는 Y(labeling data)가 필요하다. 이 labeling data는 CrowdSourcing을 통하여 labeling 작업이 되고 있다. input에 해당하는 X의 경우에는 feature의 표현으로, 주어진 X가 어떤식으로 표현이 될 것인가에 대해 결정을 되는 중요한 부분이다.
2단계 ML Model 선택하기
ML Model의 종류로는 아래와 같다. (1) Logistic regression, SVM : 분류모델 (2) Decision Tree, Random forest : 트리기반, 회귀모델 (3) Nearest neighbor : 비선형 모델 (근처 데이터를 통해 데이터 결정) (4) Neural Network, MLP : 딥러닝의 모체가 되는 모델
[ML Model 선택 가이드라인]
주어진 뎅티터의 특성에 따라 특정 ML Model이 더 낫다는 판단이 있을 수 있다.
많은 데이터 분석의 경험을 통해서 상대적으로 데이터가 많다면, Parameter가 많은 모델들이 Parameter가 적은 모델보다는 더 효과적으로 동작할 수 있다.
3단계 파라미터 값 최적화하기
주어진 모델하에서 모델이 가지고 있는 학습하고자하는 Parameter의 값을 결정하는 단계이다.
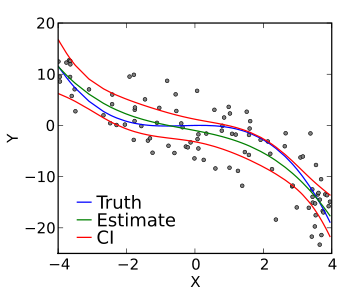
아래와 같이 회귀(regression)그래프가 주어져있고, 실제 우리가 학습하고자하는 Parameter값들이 아래와 같이 분포되어있다고 가정하자.
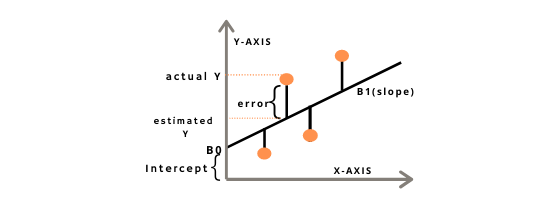
f(x; w1, w2, w3)에서 각 각의 가중치 w1, w2, w3 값을 조정해서 우리가 학습하고자 하는 Parameter값들을 좀 더 잘 표현 할 수 있는 모델을 결정지을 수 있도록 조정할 수 있다. 하지만 첨부한 사진에서 보듯이 정성적 판단(사람의 눈으로 판단)으로만 본다면 명확히 어느 가중치의 값이 가장 최적의 값인지 알 수 없다. 따라서 이 경우에는 정량적 판단(지표를 통한 판단)이 중요하다. f(x)와 y간의 관계에서 error를 최소화 함으로써 우리가 학습하고자 하는 Parameter와 실제 데이터 간의 오차범위가 작음을 확인하는 것이다.
아래의 공식은 에러의 정도를 정량적으로 판단하기위한 것으로, 위의 그래프에서 선형함수(예측값)와 Parameter(실제값) 사이의 차이값(actual Y - estimated Y)의 제곱된 값을 모든 데이터 (x,y)에 대해 모두 시행하여 합한 것을 의미한다. 여기서 W는 Error를 최소화하기 위한 값인데, 이 에러를 최소화시켜줄 값 W를 통해서 최고의 모델을 찾을 수 있다.
주어진 데이터를 표현하는 최고의 Parameter를 찾는 문제는 f(x)와 y사이에서 에러를 최소화 시키는 것이다 이것이 최적화 문제이며, 문제해결에는 아래의 두 가지 방법이 있다.
(1) Analytic solution : 방정식 풀이를 통해 최적의 해 구하기
(2) Numerical solution : 주어진 함수를 통해 해를 구하지 못하는 경우, 수치를 통해 해와 가장 가깡툰 근사치를 구한다
이렇게 학습된 Model을 사용해서 새로운 input x를 통해 output y를 예측하거나 추론한다.
이번 포스팅에서는 이전 포스팅에서 개괄적으로 분류해보았던 Reinforcement Learning에 대해서 좀 더 구체적으로 정리를 해보고자 한다.
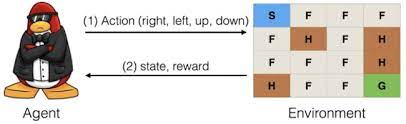
강화학습(Reinforcement Learning)?
강화학습이란 다른 머신러닝(지도학습, 비지도학습)과는 달리 agent라는 개념이 도입된다. 이 agent는 environment(환경)에서 행동을 하는 주체이며, 행동에 의해 새로운 action을 갖으며, 이에 따라 새로운 state(상태)를 갖는다. 이 상대적인 action에 따라 environment(환경)은 새로운 state(상태)와 함께 보상(rewards)을 행동의 주체인 agent에게 부여한다.
예시) 미로에서 치즈를 찾는 생쥐 - 환경(미로) / action(쥐의 미로 속 이동) / rewards(치즈) / state(미로 내 쥐의 위치)
Supervisor가 없고, 환경(Environment)에 의해서 보상을 받고 최상의 rewards를 얻기 위한 action을 선택하도록 한다.
Feedback이 delay될 수 있다.
Action이 순차적으로 미래에 주어지는 보상에 영향을 줄 수 있다.
환경이 어떤 새로운 상태를 반환할지 예측할 수 없기 때문에 Black box 상태로, 어떤식으로 rewards, state를 나타내는지 알지 못한다.
The key challenge is to learn to make good decisions under uncertainty. (핵심 과제는 불확실성에서 최고의 결정을 도출해내는 것을 배우는 것이다.)
왼쪽, 오른쪽, 총 쏘기와 같은 액션(동작)이 주어지고, 이 액션에 따라 보상(점수)가 주어진다. agent인 player의 상태(state)는 지속적으로 업데이트를 해주며, 이러한 학습을 통해 갤러그와 같은 총 쏘기 게임을 머신러닝의 강화학습 형태로 학습할 수 있다.
강화학습 예시3) 벽돌깨기 게임
사람만이 할 수 있는 전략도 컴퓨털가 학습하여 게임에 적용할 수 있다.
강화학습 예시4) 알파고
강화학습 예시5) 자율주행
Artificial Neural networks
딥러닝(Deep Learning)은 머신러닝의 여러 방법 중 중요한 방법론이며, 인공 신경망(Artificial Neural Network)의 한 종류이다. 즉, 인공지능 ⊃ 머신러닝 ⊃ 인공신경망 ⊃ 딥러닝 관계가 성립한다. 우선 딥러닝에 대해서 학습을 할 것이기 때문에 뉴럴 네트워크의 역사적 배경에 대해서는 상식적으로 알아두어야 한다. 그래서 큼직큼직한 사건은 알아두도록 하기 위해 정리하고 암기해둬야겠다.
Neural network, 한국말로하면, 신경 네트워크이다. 이 Neural network라는 말은 요즘 들어 각광을 받고 있지만, 이 말은 1940년대부터 쓰였던 말이었다. 이 시기부터 사람들은 사람의 뇌 신경 구조를 전자기적 형태(인공 신경망)로 구현하고자 했다. 그래서 1940년대에는 Electronic brain라고 해서 X AND YX OR Y와 같은 형태로 구조화 시키려고 했다. 하지만 현실적으로 AND, OR로 신경 구조를 만드는 것은 불가능했다.
1957년 Perceptron이라는 개념이 등장을 했는데, 이때부터 사람의 뇌 신경구조를 모방한 인공 신경망을 구현할 수 있었다.
1960년부터 1970년까지 Neural network의 황금기였다가 1970년대에 XOR 문제가 발견이 되면서 Neural network의 암흑기로 돌아간다.
1986년 조페리 힌튼(Geoffrey Hinton)이 Multi-layered Perceptron(Back Propagation)으로 XOR문제를 해결할 수 있다고 증명하였으나, 그 과정이 너무 복잡하고 긴 학습시간으로 주목받지 못하였다.
이후에 1995년 SVM(Support Vector Machine)을 활용해서 XOR문제와 같은 비선형 관계를 학습할 수 있는 모델이 등장하였고, 조페리 힌튼이 제시한 BackPropagation보다 간단하고 효과적이었다.
2006년 Deep Neural Network(Pretraining)모델이 등장을 하게 되고, 1986년 Multi-layered Perceptron(Back Propagation)을 제시했던 조페리 힌튼이 어떻게 학습하는지에 대한 제안을 하게된다.
cf) 심층 신경망(Deep neural networks) (1) 입력 변수들 간의 비선형 조합이 가능하다. (2) 특징 표현(Feature representation)이 학습 과정에서 함께 수행될 수 있다. (3) 데이터가 증가함에 따라 성능이 개선될 수 있다.
이에따라 2010년 후반에는 CNN기반의 이미지 분류 모델인 AlexNet을 통해 Neural Network 모델이 복잡한 문제를 해결할 수 있음을 증명
AI vs ML vs DL 상관관계
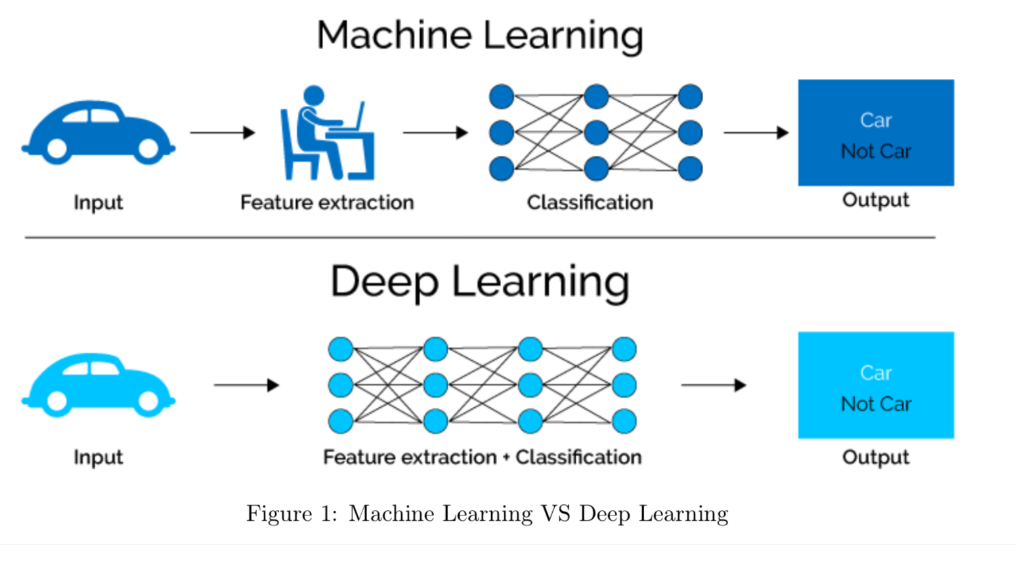
AI(Artificial Intelligence)는 ML(Machine Learning)과 DL(Deep Learning)을 아우르는 개념이다. AI는 1990년대 전후로 나눠서 살펴 볼 수 있는데, 1990년대 전에는 명시적 룰(rule)만을 적용해서 기계가 판단하는 식이 전부였다. 하지만 1990년대 이후부터는 명시적 룰(rule)이 아닌 통계를 기반으로 기계가 판단을 하였다. DL(Deep Learning)은 수많은 parameter들을 가진 복잡한 모델을 어떻게 학습 할 것인지에 대해서 학습기법이다.
전통적인 머신러닝과 딥러닝의 가장 큰 차이는 feature extraction 과정과 classification 과정의 분리/통합 유/무 상태이다. 전통적인 머신러닝은 두 과정이 서로 분리되어있으며, feature extraction을 통해 나온 출력결과와 Output의 결과가 서로 비교되어 관계학습을 하게 된다. 하지만 딥러닝에서는 feature extraction 단계가 전통적인 머신러닝에서는 필수 단계로 간주되었던 것과 달리, feature extraction(=learned feature) + classification가 통합되어 학습으로 관여된다. 사용하는 측면에서 end to end learning이기 때문에 쉽지만, 이해하는 측면에서는 Black box 형태로 가려져있기 때문에 어렵다.
딥러닝 모델의 예시
Convolutional Neural Network(CNN) : 합성곱 신경망
Recurrent Neural Network(RNN) : 순환 신경망 → 순차적 관계를 가진 시계열 데이터 처리에 가장 적합한 심층 신경망 기법
Graph Neural Network(GNN) : 그래프 신경망
Image Classification
SVN 25% ERROR RATE
AlexNet 16% ERROR RATE
Speech Recognition : 2010년 초 RNN model 적용
Machine Translation : 2010년 speech to speech model 적용, 2018 - 2019년 Transformer 적용 (Google translator/Naver Papago)
#Series.head(n): 위에서부터 n개 출력 my_series.head(2) #최 상단에서 2개까지 출력
#Series.tail(n): 아래에서부터 n개 출력 my_series.tail(2) #최 하단에서 2개까지 출력
#Series.memory_usage(): Pandas series가 사용하고 있는 용량 확인(bytes) my_series.memory_usage() #example:168(bytes)
Pandas 활용해서 CSV 파일 읽기
1 2 3 4 5 6 7 8 9 10 11 12
#Pandas의 read_csv method를 활용해서 csv파일을 읽기 위해서는 squeeze=True option은 필수이다. #squeeze=True : One dimentional table data를 읽기 위한 옵션 sp500 = pd.read_csv('S&P500_Prices.csv', squeeze=True) type(sp500) #pandas.core.series.Series
#squeeze=False : Multi dimentional(다차원) table data를 읽기 위한 옵션이다. sp500 = pd.read_csv('S&P500_Prices.csv', squeeze=False) #squeeze=False or default type(sp500) #pandas.core.frame.DataFrame
위의 각 결과를 보면 알 수 있듯이, Pandas series의 경우에는 formatting 없이 단순하게 (1차원의)하나의 열로 테이블화 된 형태로 데이터가 출력이 되고, DataFrame의 경우에는 각 셀에 스타일이 적용되어 테이블이 formatting되어 데이터가 출력된다. 데이터 프레임(DataFrame)이란 1개의 열이 아닌, 여러 행과 열을 가진 다차원 데이터 테이블이다.
# 주어진 Pandas series type의 데이터(리스트)에서 모든 양의 값은 음의 값으로 Python의 built-in function을 활용하여 구하시오. # 주어진 Pandas series의 값에서 중복되지 않은 Unique한 값을 Python의 built-in function을 활용하여 구하시오. my_series = pd.Series(data = [-10, 100, -30, 50, 100])
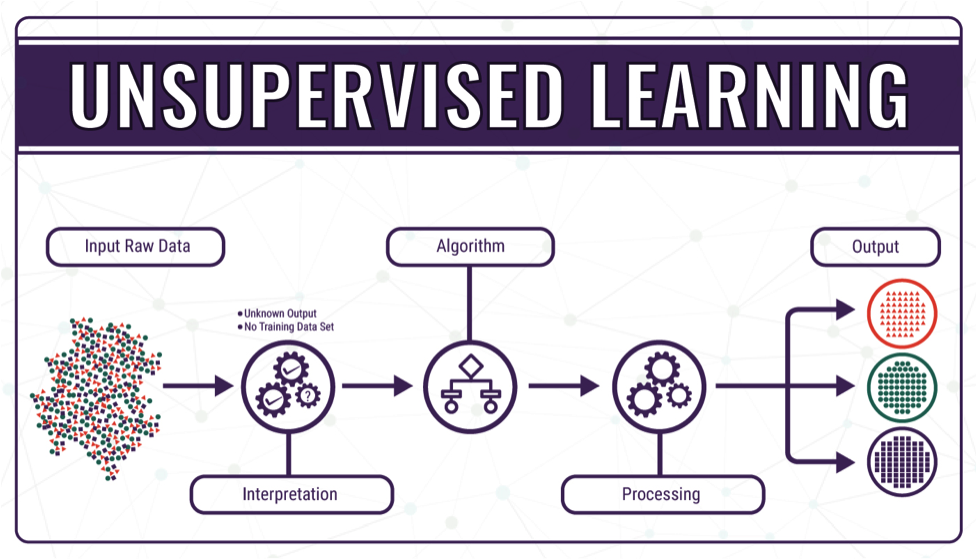
이번 포스팅에서는 이전 포스팅에서 개괄적으로 분류해보았던 Unsupervised Learning에 대해서 좀 더 구체적으로 정리를 해보고자 한다.
Unsupervised Learning ?
Supervised Learning이란 (X(input), Y(output))에서 Y(output) 값에 대한 레이블이 제공되지 않은 상태로, 최소한의 사람의 개입을 통해 데이터를 해석해서 숨겨진 데이터의 패턴을 찾아낸다.
그 예시로 각기 다른 모양과 색상을 가진 사과와 바나나가 나열되어있다고 가정해보자. 어떤 기준으로 나열을 할 것인가? 앞서 이미 언급을 했듯이 Y라는 label이 주어지지 않은 상태에서 기계는 주어진 데이터들을 분류해야한다. 기계는 사람과 같이 직관력이 없기 때문에 모양이 동그란지 혹은 길죽한지에 따라서 분류를 하기도 하고, 색상이 알록달록한지 아닌지에 따라 분류하기도 한다.
Unsupervised Learning 예시
그렇다면 비지도 학습의 예시로는 어떤것들이 있을까?
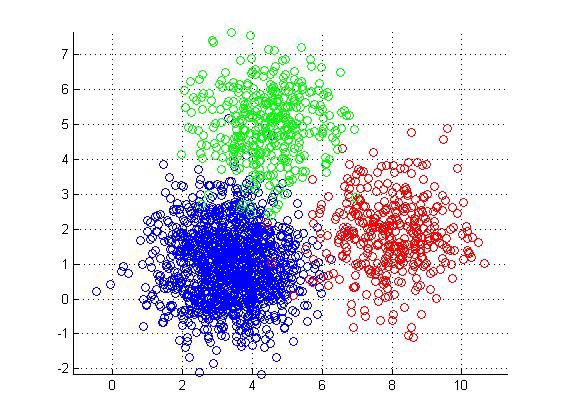
우선 첫 번째, 클러스터링(lustering)이 있다. Clustering은 Classification과 비슷하지만 Y labeling data가 주어지지 않는다는 점이 다르다. Clustering은 말 그대로 data duples을 clusters로 grouping하는 것을 말한다.Similar/Dissimilar를 정의함에 있어서는 사람이 개입을 하게 되는데, 이 부분에 있어서만 최소한으로 사람이 개입하게 된다.
두 번째, 차원축소(Dimensionality reduction)가 있다. 대표적인 예시로 PCA(Principal Component Analysis)가 있으며, 2차원의 데이터를 1차원 데이터로, 3차원 데이터를 2차원 데이터로 축소를 하게 된다. 이렇게 차원을 축소하게 되면 어떤 효과가 있을까? 우선 첫 번째 고차원에서는 알 수 없었던 correlation(상관관계)를 효과적으로 알 수 있고, 불필요한 noise를 제거할 수 있으며, 저장공간을 효율적으로 사용 할 수 있다. 그리고 마지막으로 시각화와 해석능력이 좋아진다.
세 번째, 밀집도 판단(Density estimation) : sample 모양이 규칙적이지 않고, 복잡한 모양인 경우가 많다. 이러한 복잡하고 규칙적이지 않은 모양의 영역에서 실제 데이터 영역을 추출해내야되는 경우가 많은데, 우리는 Manifold Hypothesis라는 용어에 집중해야 한다. 이 용어는 고차원 데이터라 할지라도 실질적으로 해당 데이터를 나타내주는 저차원 공간인 manifold 존재한다는 것을 의미한다. (sparse한 고차원 데이터를 간추려서 보다 저차원 공간으로 나타낼 수 있다는 의미)
manifold란, 다차원 데이터에서 실질적으로 의미를 가지는 특징을 모아둔 조밀한 특성 공간을 뜻하며, 실제 데이터를 통해 스스로 학습하는 딥러닝 비지도 학습이 이러한 manifold를 스스로 찾아낸다.
이러한 Manifold Hypothesis를 통해 가능한 가능해진 기술이 바로 GAN(Generative Adversarial Network)로, 실제로 존재하지 않는 사람을 예상으로 생성해내는 기술이다. 최근에는 사람 이외에도 자연 이미지도 예상/예측해서 생성해내고 있다. 이외에도 style-based GAN, video-to-video synthesis, source to tareget GAN 등이 있다.
이번 포스팅에서는 이전 포스팅에서 개괄적으로 분류해보았던 Supervised Learning과 Unsupervised Learning에 대해서 좀 더 구체적으로 정리를 해보고자 한다.
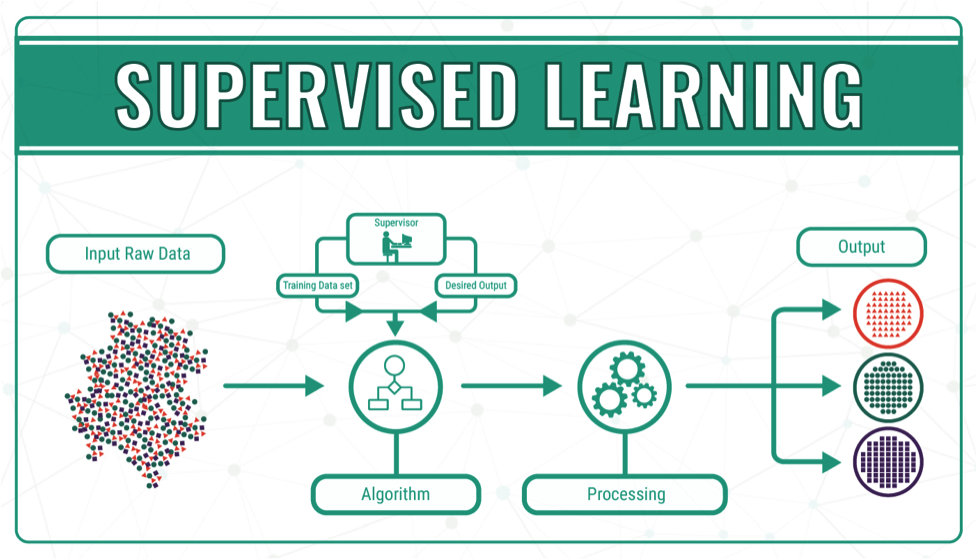
Supervised Learning ?
이전 포스팅에서 알아보았듯이 Supervised Learning이란 (X(input), Y(output))에서 Y(output)에 대한 값이 labeling을 통해 주어지고, 이를 통해 X(input)값이 유추되는 형태이다. Y의 값이 direct feedback으로 주어지고, Y 데이터의 형태에 따라 두 가지 형태로 분류된다.
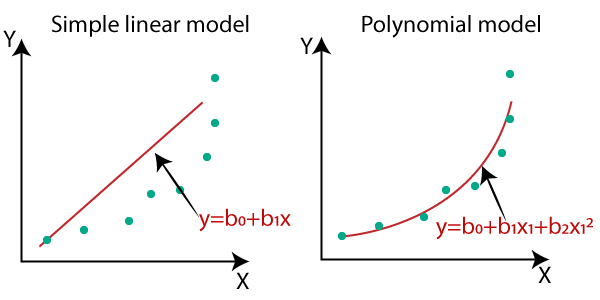
Y labels are continuous = Regression Regression은 크게 Linear Regression과 Polynomial regression으로 분류된다.
Polynomial regression은 레이블이 다항식 관계에 있는 경우이며, 2차 3차 함수의 계수 형태로 존재한다.
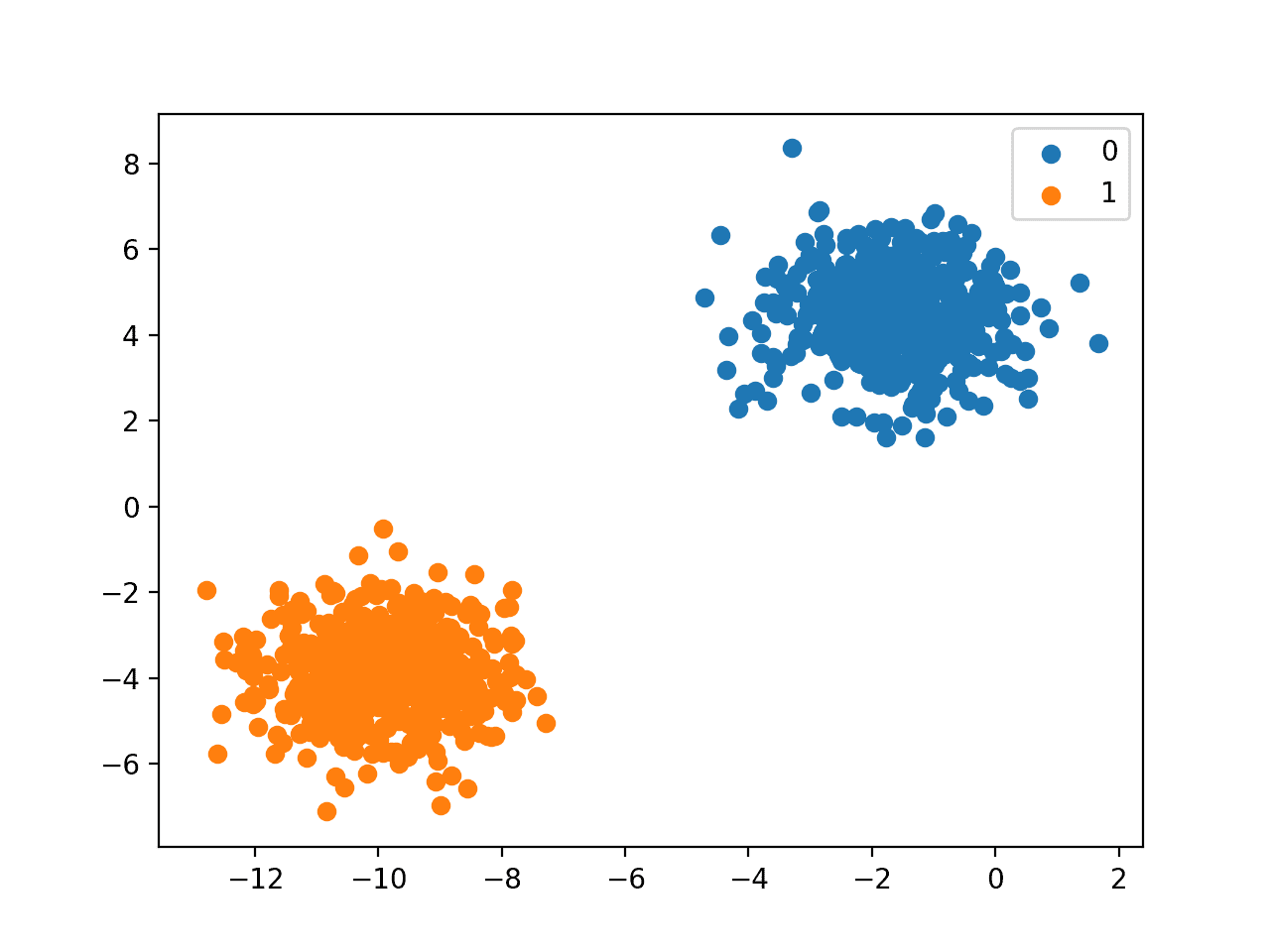
Y labels are discrete = Classification
Y 데이터가 아래와 같이 discrete형태로 분류된다면 이는 supervised learning의 classification로 분류된다.
ex)
(1) SVM (Support Vector Machine) : 기계학습의 분야 중 하나로 패턴 인식, 자료 분석을 위한 지도학습 모델이며, 주로 분류와 회귀 분석을 위해 사용된다.
(2) 신경망(Neural Network) : 신경망은 인간의 뇌 행동을 반영한다. 인간의 뇌 행동에 있어, 컴퓨터 프로그램은 특정 패턴을 인지하고 AI, 머신러닝, 딥러닝 분야에서의 일반적인 문제들을 해결하는 것 또한 허용한다. 신경망은 Artificial Neural Networks(ANNs) 또는 Simulated Neural Networks(SNNs)로 알려져있다. 이 신경망 개념은 머신러닝의 부분집합 개념이자, 딥러닝 알고리즘의 핵심적인 부분이다.
이 신경망이라는 이름과 구조는 인간의 뇌로부터 영감을 받았으며, 생물학적인 뉴런들의 시그널을 주고받는 방식을 모방하였다.
- 퍼셉트론(Perceptron)
인공 신경망은 수많은 머신 러닝 방법 중 하나로, 딥 러닝을 이해하기 위해서는 우선 인공 신경망에 대한 이해가 필요하기 때문에 초기 인공 신경망인 퍼셉트론(Perceptron)에 대한 이해가 필요하다.
(3) 의사결정 나무(Decision tree) : 의사결정나무는 DTs라고도 하며 여러가지 규칙을 순차적으로 적용하며서 독립 변수 공간을 분할하는 분류 모형이다. 분류(Classification)와 회귀 분석(Regression)에 모두 사용될 수 있기 때문에 CART(Classification And Regression Tree)라고도 한다.
(4) 나이브 베이즈 분류(Naive Bayes classification) : 스팸메일 필터, 텍스트 분류, 감정 분석, ㅊ투천 시스템 등에서 광범위하게 활용되는 분류기법이다. 나이브 베이즈 모델인 용어에서 알 수 있듯이, Naive(단순한, 순진한, 전문성이 없는)한 모델임을 알 수 있다. 나이브 베이즈 모델은 모든 feature(속성)가 동등하게중요하고 독립적이라고 가정한다. 하지만 실생활에서 각 feature(속성)들 간에 독립성을 보장하기는 쉽지 않기 때문에 실생활에 바로 적용하기에는 어려움이 있다.
(5) K-nearest neighbors(K-NN) : 지도 학습 기반에 한 종류로 거리기반 분류분석 모델이라고 할 수 있다. 기존 관측지의 Y값(Class)가 존재한다는 점에서 비지도학습인 클러스터링(Clustering)과 차이가 있다.
유유상종이라는 말이 있다. 같은 날개를 가진 새들끼리 함께 모인다는 말인데, K-NN 알고리즘을 설명하기 적합한 속담이다. 머신러닝에서 데이터를 가장 가까운 유사 속성에 따라 분류하여 데이터를 분류하는 기법이 바로 K-NN 알고리즘 기법이기 때문이다.
Classification model 예시
분류 모델의 예시로는 대표적으로 문서 분류 Sports, Politics, science … topic 별로 분류하는 것과 e-mail 중 ham vs spam SNS 내용중에 sentiment: negative, confidence: 99%, trend: boring 과 같은 감성적인 내용으로의 분류의 예시가 있다.
이외에도 아래의 분류 관련 예시들이 있다. (1) Image Classification : ImageNet Competetion (2) Video Classification : 영상의 frame을 쪼개서 분석 (3) Object Detection (4) Video Summarization : 범죄 현장에서 수사에 활용되는 기법으로 다른 시간대의 물체가 동시간대에 시간만 다르게 labeling 되어 표시된다. (5) Image Captioning : 이미지에 대한 설명 label X와 Y의 관계를 규명 (Image caption) (6) Speech Recognition : X(Speech data), Y(대응 텍스트 - 영상에 대한 설명)
이러한 머신러닝의 기법 중에 하나인 Supervised learning 기법은 우리의 실생활은 물론 현업에서도 많이 활용되고 있다.
이번 포스팅에서는 인공지능 모델을 개발할 때 필요한 필수 요소인 데이터를 준비하고 정제(전처리 및 결합)하는데 필요한 Pandas에 대한 학습을 하기 전에 데이터의 중요성과 왜 내가 지금 이 공부를 해야되는지에 대한 이유에 대해서 정리를 해보고자 한다.
데이터의 중요성
방대한 데이터를 유의미한 데이터로 가공해서 그 데이터를 통해서 가치있는 insight를 얻어서 매출 증가와 생산력을 증가시키는 기업들이 많다. 우리가 요즘 많이 시청하는 넷플릭스 또한 영화 추천 시스템을 제공하는데 이 또한 고객의 데이터를 활용해서 끊임없이 고객에게 고객이 선호하는 콘텐츠를 추천하고 제공한다.
내가 데이터 준비 및 정제에 대한 공부가 필요한 이유?
인공지능 모델을 개발 할 때 DATA + MODEL + COMPUTE 이 세 가지는 필수적인 요소이다. 이 세가지 요소는 인공지능 모델을 개발 할 때 충족해야되는 요소들로, 여기서 DATA란 어떻게 정제하고 합치고 시각화하는지가 중요시되며, MODEL은 DATA를 이용해서 인공지능을 만들 수 있는 마치 수학식과 같은 개념이라고 할 수 있다. 그리고 DATA를 사용해서 MODEL을 학습시키기 위해서는 COMPUTE의 과정이 필요하다.
앞으로의 공부계획
앞으로 데이터의 정제 및 시각화를 어떻게 하는지에 대해 학습 (수치계산에 특화된 numpy, 데이터 분석에 필요한 pandas, 데이터 시각화에 필요한 matplot, seaborn 활용)
머신러닝, 데이터 사이언스에서 사용되는 대용량 데이터 세트를 다루는 방법에 대해서 학습
대용량 데이터의 샘플로는 KAGGLE, UCI, ImageNet에서 제공하는 dataset을 활용해 볼 것이다.
Pandas는 데이터 조작 및 분석 툴로써, Numpy를 기반으로 한다. (Numpy는 파이썬을 통해서 데이터 분석을 할 때 기본적으로 사용되는 라이브러리로, C언어로 구현이 되어있는 파이썬 라이브러리이다. 고성능의 수치계산을 위해서 제작이 되었으며, Numerical Python의 줄임말이다. Numpy는 백터 및 행렬 연산에 있어서 매우 편리한 기능을 제공한다는 장점을 가지고 있으며, 데이터 분석을 사용 할 때 사용되는 라이브러리인 Pandas와 Matplotlib의 기반으로 사용되기도 한다.)
Pandas는 DataFrame으로 알려져있는 데이터 구조(MS Office excel의 Python 버전이라고 생각하면 된다)를 사용하며, DataFramems은 프로그래머로 하여금 표로 정리된 행과 열과 열 데이터의 저장과 조작을 용이하게 해준다.
(Series는 DataFrame 데이터 구조에서 단일 칼럼(Single column)으로 간주한다)
Data source는 image, audio/sound, time series/signals 등 다양한 형태로 존재한다. 이러한 뎅니터 리소스를 얻는 것은 어려운데, 데이터를 얻기 위해서는 데이터 스크래핑 과정을 거쳐서 스크래핑한 데이터를 구조화시키고, 이를 분석해서 마케팅이나 기획에서 활용된다. Data scientist가 실무에서 80% 정도의 시간을 소요하는 부분이 바로 데이터 준비 및 정제 / 데이터 전처리 및 결합이다.
데이터의 타입에는 크게 labeled data와 unlabeled data로 나뉘게 되는데, 별도로 supervisor가 시간과 비용을 들여서 labeling 과정을 거쳐 raw data에 labeling을 하는 경우에 labeled data가 만들어지게 된다.