이번 포스팅에서는 하둡의 생태계에 대한 전반적인 구성에 대해서 정리해보려고 한다. 하둡은 다양한 기술들의 집합체로, 총 3개의 세션으로 구분할 수 있다.
우선 첫 번째 Query Engine 5개의 기술스택, 두 번째 Core Hadoop Ecosystem으로 16개의 기술스택, 세 번째 External Data Storage로 3개의 기술스택, 도 합 24개의 기술들로 구성이 되어있다.
아직 막 하둡의 개념정도만 공부하고 있는 이 시점에 이렇게 방대한 하둡의 생태계에 대해서 정리하는 이유는 하둡의 전체적인 생태계를 이해하고 숲을 그려놓은 상태에서 부분 기술들을 학습하게 되면, 나중에 해당 기술스택이 왜 쓰이는지, 어떤 기술스택이 어떤 기술 스택의 대체로 사용이 될 수 있고 어떤 상황에서 어떤 기술스택 간의 조합이 적절한지에 대한 판단을 할 수 있기 때문이다.
아직은 다 알지도 알 수도 없지만, 지금은 하둡의 생김새에 대해서 알아보자.
우선, 하둡의 가장 핵심적인 부분부터 살펴볼겠다.
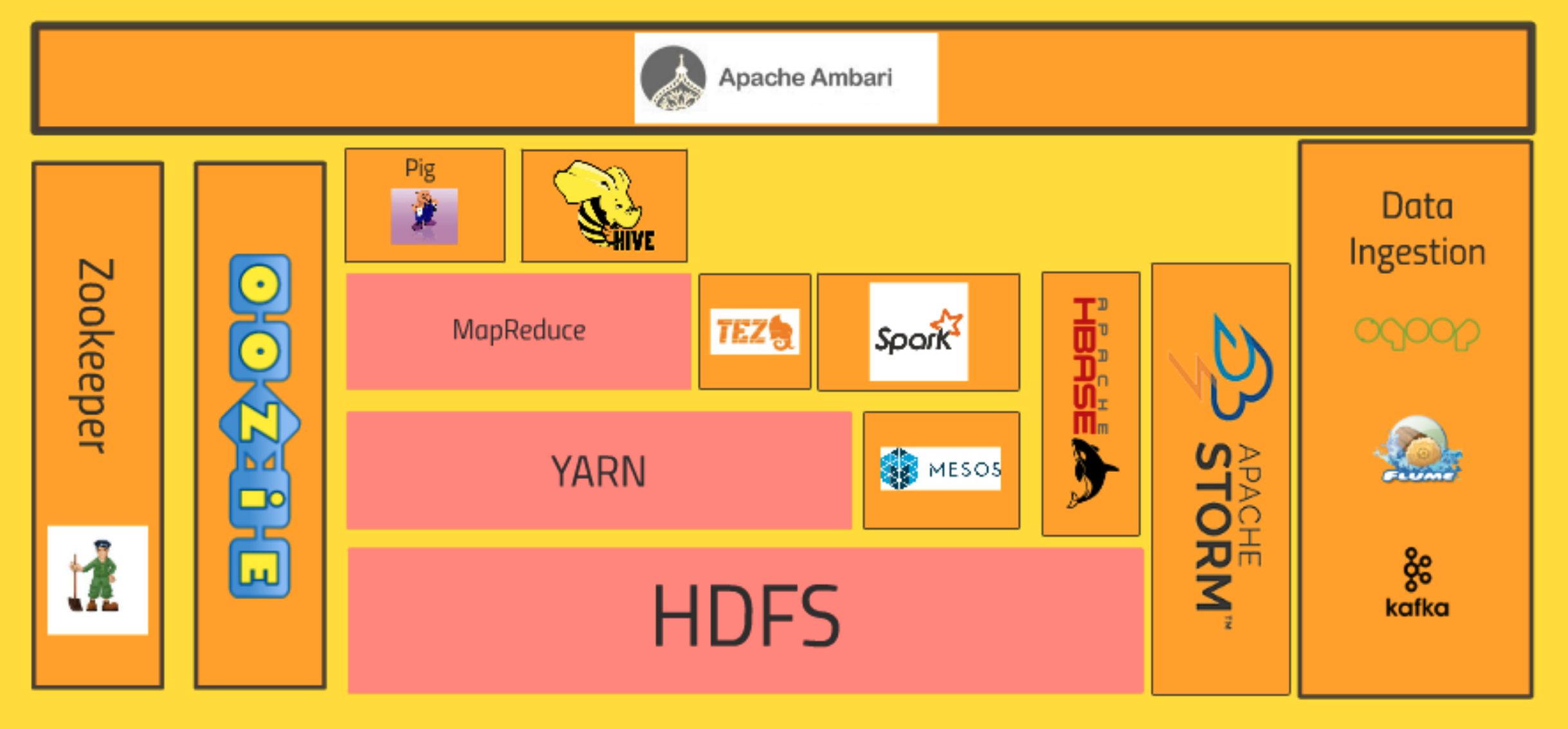
Core Hadoop Ecosystem
![[STEP1 - STEP10]](/images/post_images/220402_first_complete.png)
[STEP 1]
하둡의 가장 핵심적인 생태계의 구성을 살펴보면, 가장 바닥에 HDFS(Hadoop Distribution File System)이 기반을 잡고 있다. 이 부분은 이전에 하둡의 역사에 대해서 알아봤듯이, 구글이 만든 GFS(Google File System)이라는 기술을 기반으로 만든 하둡의 버전의 기술이다.
HDFS는 빅데이터를 클러스터의 컴퓨터들에 분산 저장하는 시스템이다. 클러스터의 하드 드라이브들이 하나의 거대한 파일 시스템을 사용하고, 그 데이터의 여분 복사본까지 만들어서 혹여나 컴퓨터가 불에 타서 녹아버리면, 백업 복사본을 사용해서 자동으로 손실을 회복하도록 한다.(HDFS = 분산 데이터 저장소 역할)