이번 포스팅에서는 1일차에 학습했던 데이터 파이프라인과 관련된 학습내용을 정리하면서 간단하게 회고 내용을 작성해보려고 한다.
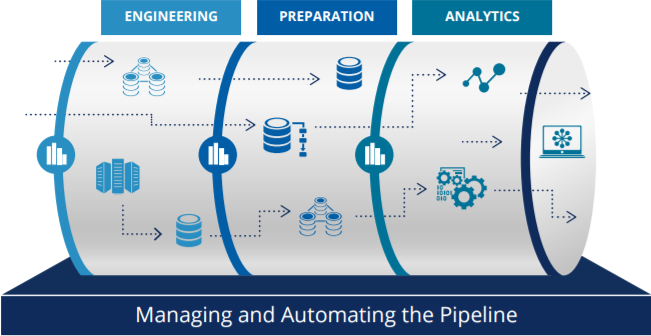
1일차 학습했던 학습내용을 개괄적으로 정리하자면, 우선 데이터 파이프라인의 흐름을 각 STEP별로 나눠서 이해하고, 데이터 파이프라인에 필요한 AWS서비스에 대해서 이해 그리고 데이터 파이프라인 구성시에 고려해야될 고려사항에 대해서 학습했다.
학습을 하면서, 모르는 용어가 많이 나왔기 때문에 실제 실무에서 일을 할때 같은 엔지니어들과 소통을 하기 위해서는 이 용어가 매우 중요하기 때문에 용어 공부를 위해 별도의 포스팅에 모르는 용어가 나올때마다 추가를 해가면서 학습을 이어가고 있다.
1일차 학습하면서 느낀점은 생각보다 어렵지만, 이전에 파이프라인이라는 말만 듣고 “뭐지?” 했을때의 막연함은 많이 사라진 것 같아서 기분은 좋다. 무언가 새로운 기술을 배울때 마냥 쉽기만 하면, 다른 사람들에게도 진입장벽이 낮다는 것을 의미하는 것이기 때문에 경쟁력을 갖추기 위해서는 어려운 기술적인 부분도 커버할 수 있는 엔지니어가 되려면 열심히 배워야겠다고 느꼈다.
아무튼 각설하고, 이전에 데이터 엔지니어 채용공고를 많이 찾아보았는데, 공고에서 AWS 클라우드 환경에서의 개발/운영 경험에 대한 요구사항이 많았다. 왜 인가 생각을 하면서 학습을 해보았는데 이 궁금증이 해결이 되었다.
간단히 말하면, 온프레미스(On-premise)방식과 클라우드 환경(Off-premise)에서의 데이터 처리가 차이가 있는데, 요구사항이 많다는 것은 온프레미스 방식보다는 클라우드 환경에서의 데이터 처리가 훨씬 더 효율적이고 좋다는 것을 의미한다. 어떤 부분이 좋은지에 대해서는 자세히 포스팅의 내용에서 다뤄보도록 하겠다.