venv 명령어
1 | $python -m venv venv # venv이름으로 가상환경 생성 |
pip 명령어
pip는 Python의 패키지 매니저로, 외부 패키지나 라이브러리, 프레임워크를 설치하고 관리할 수 있도록 도와준다.
1 | $pip install pip --upgrade # pip upgrade |
설치된 페키지를 text로 보내고 설치하기(협업)
1 | $pip freeze > requirements.txt # requirements.txt 파일에 설치된 패키지 리스트를 파일로 뽑아내기 |
1 | # python version: 3.8.1 |
CPU 바운드, I/O 바운드, Blocking
바운드
바운드란 장애물에 막혀서 실행이 되지 않는 상태를 말한다.
CPU 바운드
프로그램이 실행될 때 실행속도가 CPU 속도에 의해 제한되는 것을 말하며, 복잡한 수학 수식을 계산하는 경우, CPU의 연산 작업에 의해 프로그램이 실행될때 실행속도가 느려지거나 멈춰있는 되는 현상이 발생하게 되는데, 이를 CPU 바운드라고 한다.
I/O 바운드
프로그램이 실행될 때 실행속도가 I/O에 의해 제한되는 것을 말하며, 프로그램에서 사용자의 입력을 기다리기 위해 프로그램이 멈춰있는 경우가 발생하는데, 이를 I/0 바운드라고 한다.
Network I/O 바운드
사용자로부터 입력을 기다리기 위해 프로그램이 멈추는 것이 아닌, 외부 서버에 요청을 하여 응답을 기다리는 경우에도 프롤그램이 멈춰있는 현상이 발생하는데, 이를 Network I/O 바운드라고 한다.
Blocking
바운드에 의해 코드가 멈추게 되는 현상이 일어나는 것을 블로킹이라고 한다.
동기 및 비동기
동기(Sync)
코드가 동기적으로 동작한다는 의미는, 코드가 작성된 순서대로 실행된다는 것을 의미한다.
비동기(Async)
코드가 비동기적으로 동작한다는 의미는, 코드가 반드시 작성된 순서 그대로 실행되지 않는 것을 의미한다.
파이썬 코루틴과 비동기 함수
루틴
루틴이란 일련의 명령으로, 코드의 흐름을 말한다.
메인 루틴
메인 루틴이란 프로그램의 메인 코드의 흐름을 말한다.
서브 루틴
서브 루틴은 하나의 진입점과 하나의 탈출점이 있는 루틴을 말한다.
메인 루틴을 보조하는 역할로, 함수나 메소드가 대표적이며, 별도의 스코프에 모여있다가 호출이 되었을 경우에 해당 스코프로 이동을 한 후에 return을 통해 원 호출 시점인 메인 루틴으로 돌아오게 된다.
코루틴
코루틴은 다양한 진입점과 다양한 탈출점이 있는 루틴을 말한다. 코루틴은 서브루틴과는 다르게 해당 로직들이 진행되는 중간에 멈춰서 특정위치로 돌아 갔다가 다시 코루틴 함수에서 진행되었던 원 위치로 돌아와서 나머지 로직을 수행한다. 아래의 비동기 처리코드를 보면, meeting 함수에서 진입점이 두 개(함수 인자, await 구문), 탈출점이 두 개(await 구문, return 구문)이 있음을 확인할 수 있다.
동기 코드에서는 코드가 순차적으로 실행되어야 되기 때문에 각 각의 meeting 함수의 처리가 모두 완료된 후에 순차적으로 함수가 실행되지만, 비동기 코드에서는 meeting 함수의 await 구문 실행에서 기다리지 않고, 바로 다음 함수 실행을 함으로써 실행시간이 단축된다. 1초 후 A 실행, A 실행 후 1초 후에 B 실행, B 실행 후 1 초후에 C 실행
1 | import asyncio |
활용
코루틴의 사용에 있어, asyncio 라이브러리를 사용할 수 있는데, async 키워드로 작성된 코루틴 함수를 아래와 같이 main 함수에서 asyncio.run(x) 메소드를 통해 실행할 수 있다.
1 | import asyncio |
Fetcher 작성
requests 라이브러리만을 사용하게 되면, URL에 요청을 보내고 요청에 대한 결과를 받은 후에 연결이 끊기기 때문에 지속적으로 연결상태를 유지하면서 response로부터 원하는 데이터를 얻기 위해 Session을 사용한다.
Session을 연결한 후에는 반드시 session 연결을 끊어주는 처리를 해줘야 하는데, with 구문내에서 처리를 함으로써 session 연결을 끊어주는 별도의 처리를 하지 않아도 된다.
1 | # 일반 fetcher 코드 |
코루틴으로 작성한 fetcher에서는 requests.Session()으로 작성된 session 호출을 aiohttp.ClientSession()으로 대체한다.
1 | # 코루틴 fetcher 코드 |
컴퓨터 구조와 OS
컴퓨터의 구성 요소
컴퓨터의 구성요소로는 명령어를 해석하여 실행하는 장치로 CPU가 있으며, 작업에 필요한 프로그램과 데이터를 저장하는 장소로써의 주메모리와 데이터를 일시적으로 혹은 영구적으로 저장하는 보조 메모리가 있다.
이 외에 키보드와 마우스와 같은 입출력장치가 있으며, CPU, 메모리, 입출력장치 사이를 연결하고 데이터를 주고 받는 역할을 해주는 시스템 버스가 있다.
프로세싱
프로그램이 저장(HDD, SSD 저장장치(보조 메모리))되고, 사용자는 프로그램을 실행시키기 위해서 아이콘을 클릭해서 실행을 하게 되는데, 이 프로그램이 실행된다는 의미는 해당 프로그램의 작성 코드들이 주메모리로 올라와서 작업이 진행되는 것을 의미한다.
프로세스가 생성되면, CPU는 프로세스가 해야할 작업을 수행한다.
다시 정리하면, 프로세스란 실행을 위해 주메모리에 올라온 동적인 상태를 의미하며, 프로그램이란 저장장치에 저장된 정적인 상태를 의미한다.
스레드
CPU가 처리하는 작업의 단위가 스레드인데, 스레드란 프로세스 내에서 실행되는 여러 작업의 단위를 말한다.
스레드가 한 개로 동작하면 싱글 스레드, 여러 개의 스레드가 동작하면 멀티 스레딩이라고 하며, 복수 개의 스레드를 사용하는 멀티 스레딩에서 스레드는 다수의 스레드끼리 메모리 공유와 통신이 가능하다. 이는 자원의 낭비를 막고 효율성을 향상시키기 위함이며,
한 스레드에 문제가 생기면 전체 프로세스에 영향을 미친다.
스레드의 종류로는 사용자 수준 스레드와 커널 수준의 스레드로 나뉘는데, 파이썬에서는 사용자 수준 스레드 선에서 스레드를 다룬다.
파이썬 멀티 스레딩과 멀티 프로세싱
동시성 vs 병렬성
소프트웨어 공학에서 동시성(병행성)이란 Concurrency에 대한 번역이다. 그리고 병렬성이란 Parallelism의 의미를 가진다.
앞서 살펴본 코루틴으로 작성한 코드는 동시성(병행성)을 구현한 것이며, 그 차이에 대해서 살펴보자.
동시성(Concurrency)?
동시성이란 한 번에 여러 작업을 동시에 다루는 것(switching을 하면서 작업을 다루는 것)을 의미한다.
동시성은 논리적 개념인데, 멀티 스레딩에서 사용이 되기도 하고, 싱글 스레드에서 사용이 되기도 한다. 또한 싱글 코어 뿐 아니라 멀티 코어에서도 각각의 코어가 동시성을 사용할 수 있다.
싱글 스레드에서 사용한 동시성이 바로 asyncio를 사용한 프로그래밍이다.그리고 코루틴 함수를 사용하지 않고, 스레드 자체가 함수들을 맡게 된다면, 멀티 스레딩에서 동시성을 지킬 수 있게 된다.
병렬성(Parallelism)?
한 번에 여러 작업을 병렬적으로 처리하는 것을 의미한다. (at the same time)그리고 이는 멀티 프로세싱과 멀티 스레딩을 가능하게 한다.
각 각의 작업이 분리된 CPU 코어에서 각 각 작업을 하게 되면, 멀티 코어 환경에서 병렬성 프로그래밍이 가능한 것이고, CPU 단위가 아닌, 하나의 프로세스 단위에서 생각해보면, 스레드가 여러 개 있어야지만 병렬성 프로그래밍이 가능한 것이다.
따라서 병렬성은 물리적 개념으로, 복수 개의 작업이 병렬로 수행되는 것을 의미한다.
또한 병렬성과 동시성은 동시에 공존할 수 있는데, 예를들어 100개의 요청이 있고 CPU 코어가 3개 있다고 가정하면, CPU 3개에서 병렬적으로 처리하는 병렬성을 유지하면서 다른 요청에 대한 처리를 switching하면서 처리하는, 동시성 또한 가질 수 있는 것이다.
하지만, 파이썬에서는 스레드로 병렬성을 구현할 수 없다. GIL Global Interpreter Lock이라는 개념이 있는데, 이로인해 구현될 수 없는 것이다. 따라서 파이썬에서는 멀티 스레드가 동시성으로 수행되어야 한다.
파이썬 멀티 스레딩
우선 Single thread에서의 작업처리에 대해 살펴보면, 아래의 urls의 각 각의 작업에 대해서 같은 thread에서 처리되고 있음을 확인할 수 있다.
1 | import requests |
코루틴으로 작성한 fetcher 코드를 실행시켜보면, 같은 스레드에서 처리되고 있지만, 5초 정도 처리되는 시간이 단축됨을 확인할 수 있습니다.
1 | import aiohttp |
만약에 aiohttp에서 제공하는 코루틴 함수가 없고, 이 상황에서 동기적 코드를 사용해서 동시성 프로그래밍을 하려면 어떻게 해야될까?
바로 이 상황에서는 멀티 스레딩을 사용하면 된다.
1 | import requests |
스레드를 사용하는 것보다는 코루틴을 사용하는 것을 권장한다. 그 이유는 스레드를 늘려서 작업을 처리하는 것에는 많은 연산과정이 추가되기 때문에 메모리 점유율이 많이 들어가기 때문이다.
파이썬 멀티 프로세싱, GIL
다른 프로그래밍 언어에서는 멀티 스레딩을 사용해서 병렬성 프로그래밍이 가능하고, 멀티 스레딩의 장점이자 단점은 메모리를 공유한다는 것이다. 그 이유는 멀티 스레딩에서는 스레드를 하나의 프로세스에서 여러 개로 만들어서 진행을 하게 되는데, 메모리를 공유하기 때문에 하나의 스레드에서 에러가 발생하면 다른 스레드에서도 에러가 발생하기 때문이다.
반면에 멀티 프로세싱에서는 각 각의 프로세스를 자식 프로세스로써 복제해서 진행을 하게 된다.
위의 이유로 인해 파이썬을 만든 개발자가 파이썬을 만들었을 때 GIL(Global Interpreter Lock)을 도입하게 되었는데, 이는 한 번에 1개의 스레드만 유지하는 락을 의미한다. GIL은 본질적으로 한 스레드가 다른 스레드를 차단해서 제어를 얻는 것을 막아준다.
이는 앞서 언급한 멀티 스레딩의 위험으로부터 보호하기 위함이다. 이러한 이유로 파이썬에서는 스레드로 병렬성 연산을 수행하지 못한다.
하지만, 파이썬의 멀티 스레딩은 동시성(Concurrency)를 사용해서 Network I/O bound 코드에서 유용하게 사용할 수 있지만, CPU bound에서는 GIL에 의해서 원하는 결과를 얻을 수 없다.
이 경우에 사용되는 것이 멀티 프로세싱인데, 프로세스를 여러 개 복제하고, 각 각의 프로세스들이 메모리 공유를 하지 않기 때문에 서로 소통을 하기 위해서 직렬화와 역직렬화 작업이 필요한데, 이런 비용이 멀티 스레딩을 사용했을때보다 크다.
만약에 이러한 단점을 감수해서라도 속도를 높이고 싶다면, 멀티 프로세싱을 사용한다.
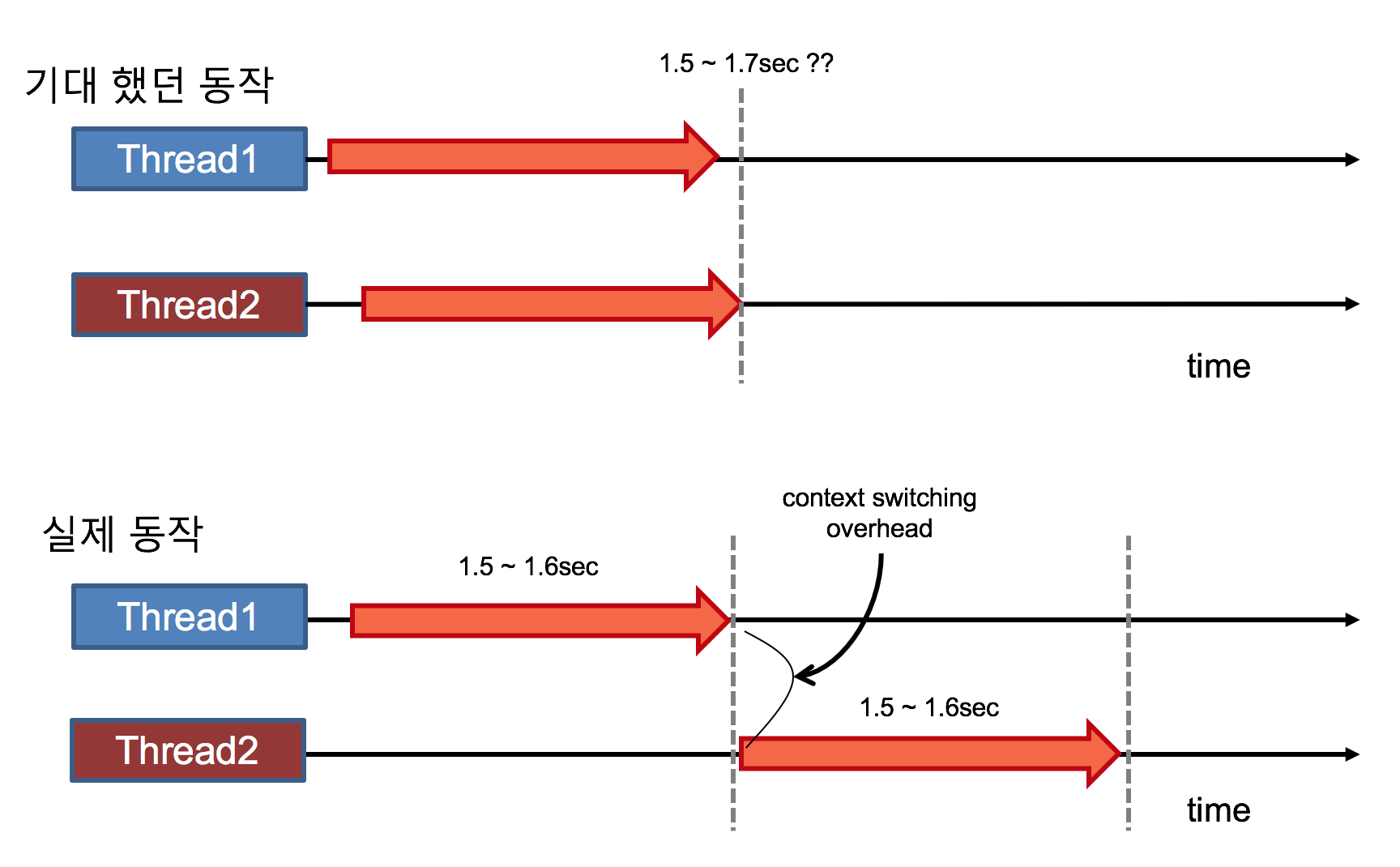
CPU 연산 작업에 있어서 파이썬으로 멀티 스레딩으로 처리를 한다면, 이는 일반적으로 처리한 코드와 걸리는 시간은 별 차이가 없다. (동시성 프로그래밍이 불필요한 케이스)
이 경우에는 함수 하나 하나를 별도의 프로세싱으로 분리해서 병렬로 처리하는 것이 시간단축에 도움이 된다.
이는 기존의 ThreadPoolExecutor를 ProcessPoolExecutor로 수정해서 실행하면 되는데, 많은 시간을 단축할 수 있다.