
이번 포스팅에서는 Apache Airflow의 기본 개념과 사용에 대해서 정리해보려고 한다.
이전에 AWS의 EventBridge라는 서비스를 사용해서 셍성한 Lambda 함수를 일정 주기의 시간동안 정기적으로 실행되도록 스케줄링해서 실습한 적이 있는데, Task를 좀 더 복잡한 구조로 스케줄링하기 위해서는 Apache Airflow를 활용하는 것이 좀 더 효율적이라고 오프라인 수업에서 배워서, 한 번 Apache Airflow를 사용해서 데이터 파이프라인을 구축해보고자 학습을 하게 되었다. 그리고 지원하고자 하는 기업에서 Apache Airflow를 업무에서 도입을 하여 사용하고 있기 때문에 좀 더 잘 이해하고 사용해보려고 한다.
Apache Airflow를 사용하는 이유
데이터 파이프라인 구축에 있어, 데이터를 추출하는 Extract, 데이터를 적재하는 Load, 데이터를 변환하는 Transform 과정을 거친다. 데이터 추출은 API를 통해서 하기도 하며, Load는 Snowflake와 같은 data warehousing, data lake와 같은 Single platform을 제공하는 SaaS를 활용하기도 한다. 그리고 Transform은 Dbt와 같은 분석을 위한 데이터 웨어하우스에 적재된 데이터를 간단한 SELECT 문 작성을 통해 변환을 할 수도 있다.
만약 Extract, Load, Transform 단계에서 예기치 못한 에러가 발생한다면, 그리고 데이터 파이프라인이 한 개가 아닌 100개 이상이라면 어떨까?
관리하기가 많이 어려워진다. 이러한 이유로 인해 Airflow를 사용해서 종합적인 파이프라인의 관리가 필요하다.
DAG(Directed Acyclic Graph)
DAG는 방향성 비순환 그래프로, Airfow의 주요 컨셉이며, 복수 개의 Task를 모아서 어떻게 실행이 되어야 하는지에 대한 종속성과 관계에 따라 구조화 시키는 것을 말한다.
Operator
Operator는 Task이며, 실행이 되면 Task instance가 생성이 되며, Operator의 예로는 Action operator, Transfer operator, Sensor operator가 있다.
Action operator의 예로는 Python operator, Bash operator가 있는데, Python operator는 Python function을 실행시키며, Bash operator는 Bash command를 실행시키는 역할을 한다. 그리고 Transfer operator의 예로는 MySQL의 데이터를 RedShift로 이전하는 작업이 있으며, Sensor operator의 예로는 특정 이벤트가 발생하면 다음 Step으로 넘어가도록 하는 작업이 있다.
Apache Airflow의 요소
Apache Airflow에는 Webserver, Meta store, Scheduler, Executor, Queue, Worker가 있다.
Executor는 직접적으로 Task를 실행하지 않으며, K8S 클러스터는 K8S Executor를 사용하고, Celery 클러스터는 Celery Executor를 사용한다. 여기서 Celery는 multiple machine에서의 multiple tasks를 실행하기 위한 Python 프레임워크이다.
Queue는 주어진 Task를 보장된 순서로 실행시키기 위해 존재한다.
Worker는 Task가 효과적으로 실행될 수 있도록 하는 역할을 하며, Worker가 없다면, sub processes 혹은 K8S를 사용하는 경우, Path가 주어진다.
Apache Airflow의 Architecture
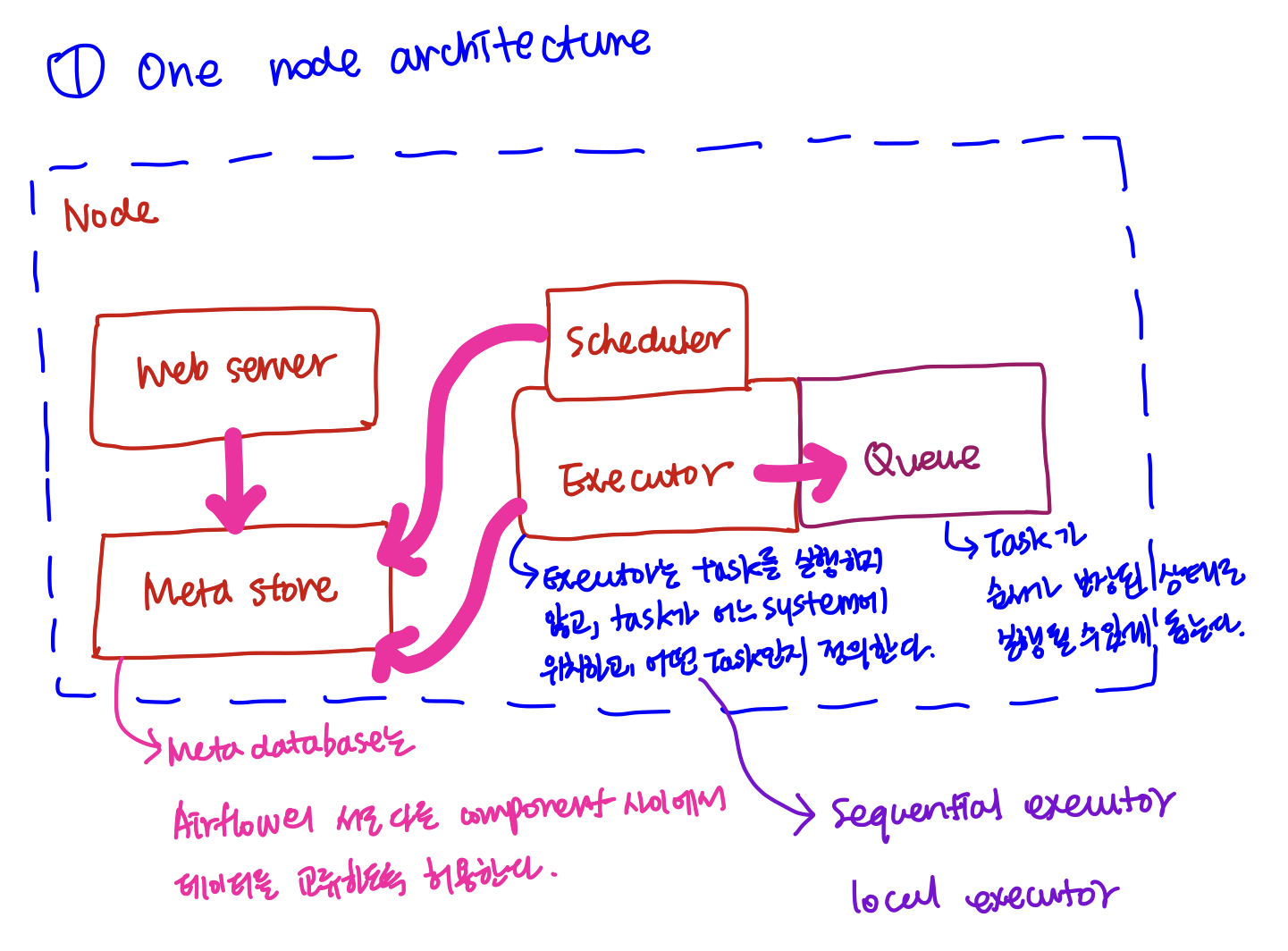
Apache Airflow의 Architecture로는 단일 노드로 구성된 One Node Architecture, 그리고 복수 개의 노드들로 구성된 Multi Node Architecture가 있다.
우선 첫 번째로 단일 노드 아키텍처를 살펴보면, 하나의 노드에 Web server와 Meta store, Scheduler, Executor, Queue가 존재한다. 여기서 Meta store는 Airflow에 존재하는 서로 다른 component 사이에서 데이터를 교환할 수 있도록 한다. 또 다른 섹션에서 전체적인 흐름을 정리하겠지만, Scheduler는 사용자가 작성한 Dag 파일을 정기적으로 정해진 시간 간격으로 파싱해서 새로운 Dag Run Object를 Meta store에 생성되고, Task의 수에 따라 Task Instance가 이어서 생성이 된다. 그리고 Dag Run Object와 Task Instance는 상태 정보와 함께 관리된다.
앞서 언급한 객체와 인스턴스의 상태 정보들이 Meta store에 업데이트가 되면서 Apach Airflow의 UI가 업데이트되고, 이로써 사용자가 UI를 통해 Task의 상태 정보를 Tracking할 수 있게 되는 것이다.
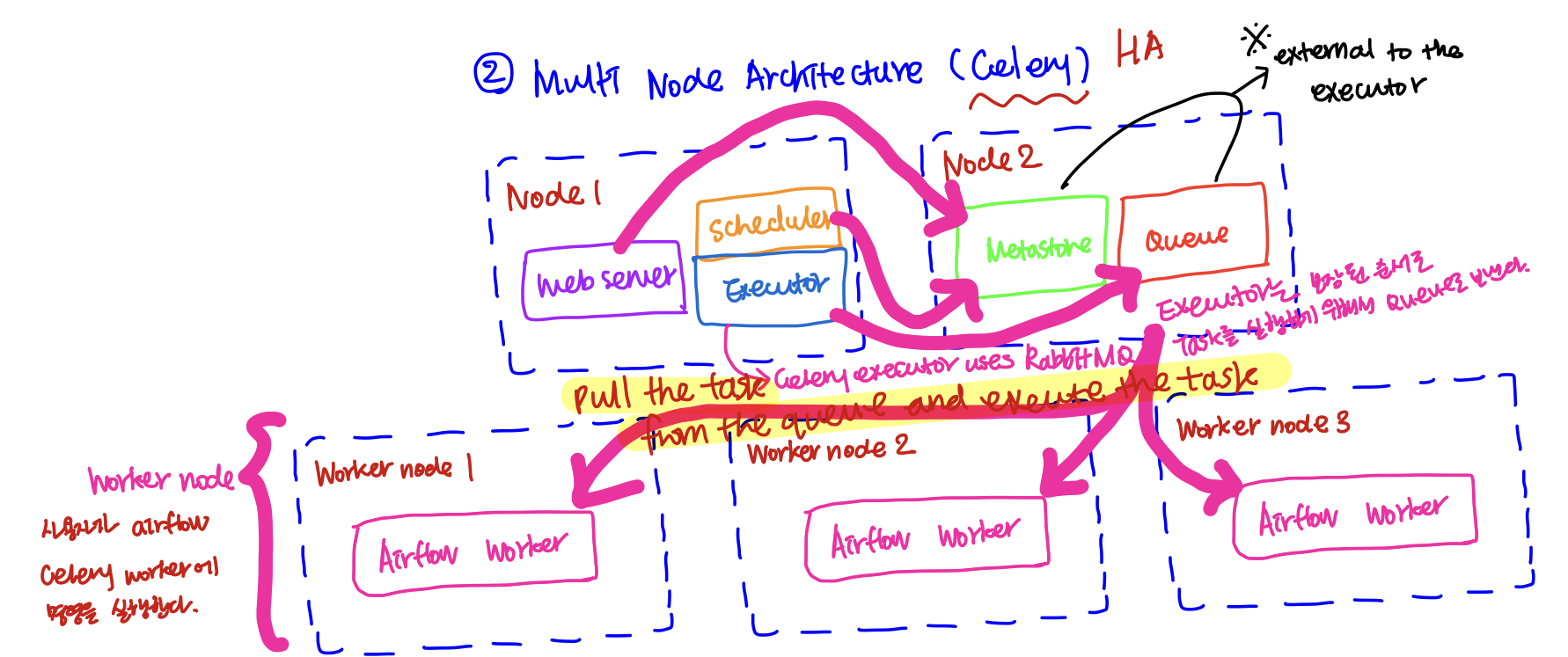
두 번째로 multi-node Architecture를 살펴보면, 위에서 살펴보았던 단일 노드 아키텍처와 달리 Meta store와 Queue를 별도의 노드로 분리하고, Queue에 쌓인 Task를 실행할 Worker node들이 복수 개 존재하고 있음을 알 수 있다. 이러한 복수 개의 노드로 구성하는 이유는 고가용성(HA)을 위함인데, Single point failure 이슈를 사전에 예방하고자 구성한다.
만약에 Load balancer를 사용해서 요청을 분산해서 처리하고자 한다면, 최소 두 개의 Web Server와 Scheduler가 필요하다.
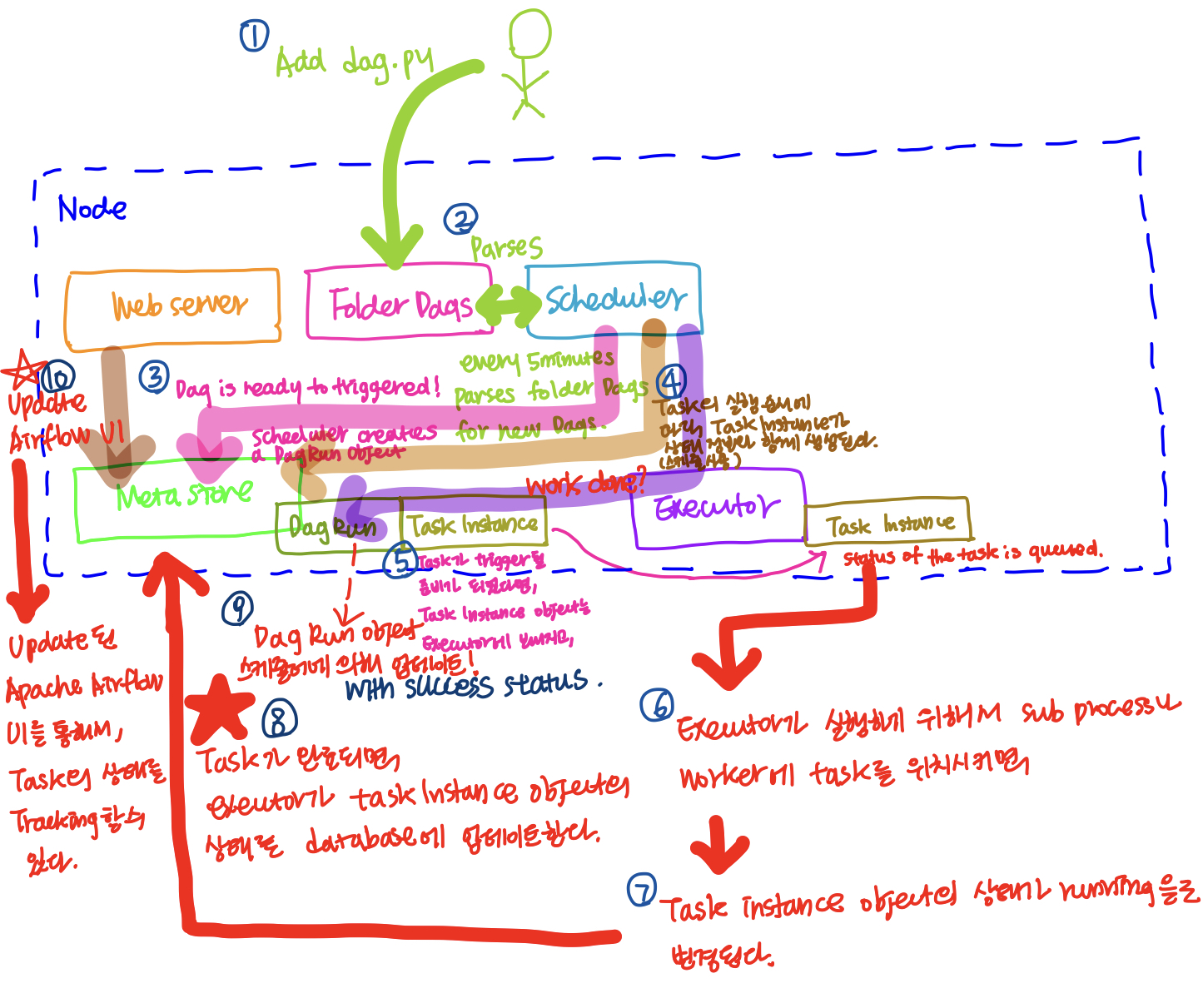
Apache Airflow의 전체 흐름
Apache Airflow의 Task와 데이터 파이프라인을 debug하기 위해서는 Task가 어떻게 실행되는지에 대한 전반적인 이해가 필요하다.
우선 단일 노드의 관점에서 살펴보면, 아래 그림과 같이 Web server, Meta store, Scheduler, Executor, Folder Dags가 존재한다.
(1) 개발자가 dag.py파일을 작성해서 Folder Dags에 추가한다.
(2) Scheduler는 정해진 시간동안 정기적으로 새로운 Dags 객체 생성을 위해 Folder Dags를 파싱한다.
(3) Dag가 Trigger될 준비가 되었다면, Scheduler는 Dag Run Object를 Meta store에 생성한다.
(4) Task의 갯수에 따라 Task Instance가 상태 정보와 함께 생성이 된다.
(5) Task가 Trigger될 준비가 되었다면, Task Instance Object를 Executor로 보내게 되고, Task Instance의 상태는 queued상태로 변경된다.
(6) Executor가 실행을 위해 Task instance를 Sub process나 Worker에 Task를 위치시키면,
(7) Task Instance의 상태가 queued에서 running으로 변경된다.
(8) Task가 완료되면, executor가 Task Instance Object의 상태를 databaser에 업데이트한다.
(9) Scheduler가 Dag Run Object에 작업이 완료되었는지 확인을 하고, 작업이 완료되었다면, 상태가 success로 업데이트된다.
(10) Web server는 Meta store를 참고해서 Apache Airflow의 UI를 업데이트하게 되고, Apache Airflow의 UI를 통해서 Task의 상태를 Tracking할 수 있게 된다.
Apache Airflow 설치
(꼭 알아야 할 중요한 내용) Apache
(1) Airflow is an orchestrator, not a processing framework, process your gigabytes of data outside of Airflow (i.e. You have a Spark cluster, you use an operator to execute a Spark job, the data is processed in Spark).
(2) A DAG is a data pipeline, an Operator is a task.
(3) An Executor defines how your tasks are execute whereas a worker is a process executing your task
(4) The scheduler schedules your tasks, the web server serves the UI, the database stores the metadata of Airflow.
(5) airflow db init is the first command to execute to initialise Airflow
(6) If a task fails, check the logs by clicking on the task from the UI and “Logs”
(7) The Gantt view is super useful to sport bottlenecks and tasks are too long to execute
Postgres Database와 연결하기
Operator가 Postgres, MySQL, AWS, dbt 등의 외부 툴과 함께 상호작용을 해야 될 때에는 Apache Airflow의 [Admin]-[Connections]에서 새로운 Connection을 생성해줘야 한다.
Task 생성하기
(1) Import the operator
(2) Define the task id
Task ID는 같은 DAG 내에서 반드시 유일해야한다.
1 | from airflow.providers.postgres.operators.postgres import PostgresOperator |
DAG에 Task를 추가한 후 확인하기
Airflow의 DAG에 Task를 추가한 후에는 반드시 확인해야 한다.
1 | # Airflow의 scheduler Name 확인 |
Sensor operator
Sensor는 Airflow의 Context로, 내가 원하는 무언가를 위해 기다려준다. 예를들어, 특정 위치에 파일이 생성되거나 SQL 테이블의 속성에 파일 정보가 기입되는 등의 작업들이 그 예시가 되며, Airflow에서는 수 많은 Sensor operator를 제공해준다.
기억해야 될 것은 두 가지 parameter, poke_interval(default: 60s)과 timeout(default: 7days)이 있다. poke_interval이 default 값으로 설정이 되어있으면, sensor는 다음 Task를 실행하기 전에 조건이 참이지 거짓인지 매 60초마다 확인을 한다. timeout은 무기한으로 poking하는 것을 허용하지 않기 위해 default 값으로 설정하는 경우, 최대 7일이라는 poking을 멈추고 종료하는 최대 시간을 갖습니다. (sensor operator는 FAILED나 SKIPPED로 표기됩니다.)
주어진 API가 유효한지에 대해 검사를 하기 위해 HttpSensor operator를 사용하며, 이외에 파일의 생성에 대해 감지하고 싶다면, FileSensor를, S3 bucket에 대한 감지가 필요하다면, S3KeySensor를 사용하면 된다.
Hook
Airflow에서는 다양한 외부 툴과 손쉽게 상호작용 할 수 있도록 Hook이라는 개념이 존재한다. 예를들어 PostgresSQL 데이터베이스에 sql 쿼리를 처리할때, PostgresHook이라는 것이 PostgresOperator와 PostgresSQL 데이터베이스 사이에 존재하기 때문에 툴이나 서비스와 상호작용하기 위한 복잡한 부분이 추상화되어 개발자가 손쉽게 작업을 할 수 있도록 도와준다.
PostgresHook
PostgresSQL 데이터베이스의 테이블에 데이터를 저장하기 위해서는 PostgresHook이 필요하다.
Dependency 추가
각 각의 개별 Task를 생성한 후에는 개별 Task에 대해 파일의 마지막에 dependencies를 정의해서 연결해줘야 한다. 아래 코드를 정의한 다음에 Apache Airflow의 DAG의 Graph 메뉴를 보면, 이전에 개별로 표시된 Task들이 화살표로 엮여서 표시된 것을 확인할 수 있다.
1 | create_table >> is_api_available >> extract_user >> process_user >> store_user |
DAG 실행
DAG 파일의 작성이 끝나면, DAG를 실행해서 모든 Task들이 정상적으로 실행이 되고, 완료되는지 확인하고, 아래 명령으로 Airflow worker container에 접속해서 테스트로 작성한 DAG에서 외부 API 호출을 통해 데이터를 긁어와서 CSV파일로 추출한 데이터 파일을 확인한다.
1 | $docker exec -it materials_airflow-worker_1 /bin/bash |
이제 PostgresSQL 데이터베이스에 csv 데이터가 잘 적재되었는지 아래의 명령을 통해 확인한다.
1 | $docker exec -it materials_postgres_1 /bin/bash |
DAG 스케줄링
우리가 DAG 객체를 정의할때, start_date와 schedule_interval을 정의해주는데, 아래의 규칙으로 DAG가 실행을 한다. (end_date는 생략 가능)
DAG는 start_date/last_run + the schedule_interval 이후에 트리거된다. 주의해야 될 것은 start_date에는 아무 것도 발생하지 않는다는 것이다.
예를들어, start_date가 10:00AM 이고, schedule interval이 매 10분이라고 정의가 되었다면, 최초 10:00AM에는 아무 것도 발생하지 않고, 최초 10분 이후인 10:10AM에 DAG가 실행되어, data_interval_end가 10:10AM이 된다. 이후에는 data_interval_start이 10:10AM이 되고, data_interval_end가 10:20AM이 된다.