
이번 포스팅에서는 여섯 번째 데이터 파이프라인 구축 오프라인 수업시간에서 배운 내용을 정리하려고 한다.
이번 여섯 번째 수업을 마지막으로 데이터 파이프라인 구축과 관련한 데이터 엔지니어링 수업이 마무리되었다. 이번 수업을 통해 정말 많은 것들을 배울 수 있었다. 특히 이전에는 클라우드 플랫폼을 활용해서 데이터 파이프라인을 구축하는 것이 전부라고 생각했었지만, 이번 수업을 듣고나서 관리 및 운영의 관점에서 클라우드 플랫폼에서 제공하는 서비스들의 근간이 되는 오픈 소스 프로젝트의 세부 동작원리에 대해서 이해하는 것이 더 중요하다는 것을 배웠다. 그리고 클라우드 플랫폼을 활용해서 데이터 파이프라인을 처음 구축했을때 그 다음 스탭으로 어떤 식으로 공부를 이어나갈지 감을 잡지 못했었는데, 이번 총 6번의 수업동안 (6주간 진행)앞으로 어떻게 더 공부를 해야되는지, 그리고 새로운 기술스택이 나왔을때 어떤식으로 학습을 이어나가야 되는지에 대해서 알게 되었다.
이번 마지막 수업을 마무리하며 강사님이 어느 데이터 파이프라인 구축에 있어, 어느 파이프라인 구성이 정답이고 그런 건 없다고 하셨다. 그리고 수업을 들으면서 느낀 것은 정말 하나의 파이프라인을 구성할때에도 많은 것들을 고려해야하며, 파이프라인의 각 구성 요소들의 특징들을 제대로 이해하고 있어야 비로소 효율적인 파이프라인을 구축할 수 있다는 것을 배웠다. 아무튼 이번 수업을 통해 좀 더 데이터 엔지니어의 업무 중 하나인 데이터 파이프라인 구축에 대해서 좀 더 심도있게 배울 수 있었던 것 같다.
매주 한 번 강남역에 가서 세 시간씩 하루도 빠지지 않고 수업에 참여하고, 배운 내용을 블로그에 하나도 빠뜨리지 않고 기록하였다. 이런 나에게 칭찬을 하며, 마지막 수업시간에 배운 내용을 정리해보려고 한다.
ElasticSearch
ES를 NoSQL DB와 같은 저장소로써 사용을 하면서 저장된 데이터를 검색하는 용도로 사용된다. 그리고 주로 모니터링이나 로깅과 같은 용도로 많이 사용된다. 메트릭 같은 것을 JSON에 같이 담아서 Kibana를 통해서 그래프로 그려주면, 프로메테우스와 같은 TS DB와 같은 성능은 내지 못하지만, 대시보드로 충분히 그려서 활용할 수 있다. 데이터가 적은 경우에는 앞에서 설명한 것과 같이 ElasticSearch에 저장된 데이터를 Kibana를 활용해서 시각화를 해줄 수 있지만, 이러한 메트릭 값들이 많아지면, TS(Time Series) 전용으로 담아두는 TS DB를 생성해서 관리한다.
이처럼 ES는 검색엔진이지만, 다양한 용도로 사용이 되고 있다.
메트릭?
메트릭이란 타임스탬프와 보통 한 두 가지 숫자 값을 포함하는 이벤트이다. 이 메트릭은 모든 메트릭의 행이 타임스탬프로 정렬된 메트릭 파일에 순차적으로 추가된다.
로그와는 달리 메트릭은 주기적으로 보내게 되며, 로그는 보통 무언가가 발생했을때 로그 파일에 추가되는 형식으로 동작한다.
메트릭은 종종 리소스 사용 모니터링, 데이터베이스 실행 메트릭 모니터링 등 소프트웨어나 하드웨어의 상태 모니터링 맥락에서 사용되는 것이 일반적이다.Elastic은 솔루션의 모든 계층에서 메트릭 관리와 분석에 대한 사용자 경험을 증진하는 새로운 기능을 제공한다. Matricbeat는 5.0의 새로운 기능 중 하나이며, 사용자가 머신이나 어플리케이션에서 ElasticSearch로 메트릭 데이터를 전달할 수도 있고, Kibana에서 바로 사용 가능한 대시보드를 제공한다. Kibana는 메트릭 같은 숫자 데이터를 다룰 수 있게 설계한 타임라인온 플러그인도 코어에 연동해서 사용할 수 있다.
TSDB(Time Series Database)?
TSDB는 Time-Stamped Data라고도 불리며, 시간에 따라 저장된 데이터를 의미한다. 시계열 데이터는 동일한 소스로부터 시간이 지남에 따라 만들어진 데이터들로 구성이 되기 때문에 시간 경과에 따른 변화를 추적하는데 용이하다.
ex)어떤 집안의 온도들로부터 경제 지표, 환자의 심작 박동수나 회사의 주가, 서버로부터 기록되는 히스토리성 데이터, 센서 데이터TSDB란 시계열 데이터를 처리하기 위해 최적화된 데이터베이스로, 빠르고 정확하게 실시간으로 쌓이는 대규모 데이터들을 처리할 수 있도록 고안되었다. TSDB는 데이터들과 시간이 함께 저장하는데, 이를 통해 시간의 흐름에 따라 데이터를 분석하기에 매우 용이하다. 오늘날 엄청나게 많은 데이터들이 수집이 되고 있고, 인공지능의 급격한 발달로 필요한 데이터들의 양이 급증하고 있다. 이러한 데이터들을 처리하기에는 관계형 데이터베이스와 NoSQL로는 한계가 있기 때문에 거의 끝없는 데이터들을 처리할 수 있는 TSDB, 시계열 데이터의 중요성이 대두되고 있다.
ref)자율주행과 같은 경우, 약 8시간 운전할 때마다 40TB의 데이터를 만들고 사용한다.
Amazon QuickSight
Amazon QuickSight는 Amazon에서 제공하는 BI툴로, AWS 계정이 별도로 요구되지 않기 때문에 손쉽게 다른 사람들과 구성한 Dashboard를 공유할 수 있다. BI의 영역이 Engineer와 Scientist 간의 중첩 영역(협업 영역)으로 데이터 엔지니어가 데이터를 잘 정제해서 서빙을 해주면, 서빙된 데이터를 DA와 DS들이 붙어서 시각화 및 분석을 하기 때문이다.
이러한 BI 툴은 규모가 점점 커지는 기업의 경우에는 FE개발자가 붙어서 전용 dashboard를 만들기도 한다고 한다. 이러한 FE 작업을 줄여주기 위해서 BI툴을 사용하기도 한다.
그리고 AWS QuickSight의 최고 장점은 다양한 AWS의 여러 데이터 소스를 기반으로 BI툴을 활용할 수 있다.
(1) QuickSight demo : https://democentral.learnquicksight.online/
비 IT 부서에 차트로 시각화해서 정보를 제공할때 사용이 되며, 생성된 dashboard에 접근하기 위한 개별 계정을 부여할 수 있다.
(2) QuickSight workshop : https://catalog.us-east-1.prod.workshops.aws/workshops/ac8dc849-3d95-43e3-b380-aa38f0dc31e4/en-US/author-workshop/1-build-your-first-dashboard
S3의 데이터를 조회할때 자체 성능을 위해서 Partitioning이 필요하지만 엄청난 양의 데이터를 쌓을 수 있다.그리고 Amazon QuickSight는 Third party platform, On-premise DB 등 다양한 데이터 리소스를 연결해서 BI툴을 활용할 수 있다.
이번 실습에서는 간단하게 CloudFormation에서 랜덤한 로그 데이터를 생성해주고, 적재된 데이터를 기준으로 QuickSight에서 시각화를 해주었는데, 실제 업무에서는 데이터가 실시간으로 계속 쌓이고 있기 때문에 신규 스트리밍 데이터의 경우에는 Athena에서 계속 조회를 해서 가져와야한다. 따라서 별도로 배치를 돌려서 일률적으로 데이터를 업데이트해줘야한다.
참고) 실제 hive, Presto에서도 MKCK repair update를 해서 메타 데이터를 업데이트해서 새로운 데이터를 가져오는데, QuickSight에서는 데이터 세트 메뉴에서 가져온 데이터를 조회하는 UI에서 "지금 새로 고침" 또는 "새로 고침 예약"을 통해 기존 데이터를 새로운 데이터로 업데이트해줄 수 있다.
ES의 경우에는 새로운 데이터가 생기는 즉시 ES가 indexing을 통해 데이터를 업데이트해주기 때문에 실시간으로 Kibana를 통해 상시 업데이트된 시각화 정보를 보여줄 수 있다.
하지만 BI 툴의 경우, 비즈니스 용도로 월별, 연도별로 데이터를 분류하여 시각화를 해주기 때문에 이러한 데이터 새로고침이 ES에 비해 좀 떨어지는 편이다.
QuickSight에서 업데이트된 데이터 세트를 refresh해주기 위해서 데이터 세트 메뉴에서 일정 생성을 통해서 scheduling하는 기능을 추가해줘야 한다. (일정 기간 단위 실행)
이러한 QuickSight의 dashboard를 활용하여 CS(Customer Satisfaction)부서 내에 근무하는 직원이 현재 고객응대 현황을 그래프로 확인을 할 수도 있고, 개발자가 현재 고객들이 어떠한 문제로 연락을 하고 있는지 현황을 파악하는 용도로도 활용될 수 있다. 그리고 QuickSight는 외부 서비스로써, 따로 조회만 가능한 계정을 발급해 줄 수도 있다.
실제 현업에서는 ES가 많이 사용되지만, QuickSight도 ES를 대체해서 사용할 수 있다.
그리고 대용량 데이터의 경우에는 Lambda로 데이터 변환작업을 하기 어려운 경우도 있기 때문에 Lambda를 Athena를 호출하는 용도로만 해서 작업을 할 수도 있고, Redshift에 데이터를 담아서 쿼리를 날리는 형태로 처리할 수도 있다.
추가적으로 단일 파이프라인이 아닌, job들이 복잡해지는 경우에는 데이터가 쌓인 후에 특정 파이프라인을 실행하고, 해당 파이프라인의 처리가 성공한 경우에는 A 파이프라인으로, 실패한 경우에는 B 파이프라인으로 처리할 수 있도록 dependencies를 처리해야되는 경우도 생긴다.
이러한 복잡한 job에 대한 처리는 EventBridge로는 부족할 수 있기 때문에 Airflow나 아르고 플로우와 같은 스케쥴링 엔진을 적용해서 스케줄링 작업을 해줘야한다.
(참고) SQS와 같은 큐 서비스를 사용해서 job을 분류해서 처리할 수도 있다.
[실습] Amazon QuickSight
우선 Amazon QuickSight에 sample csv 파일을 import하여 x-axis, y-axis의 기준 칼럼을 변경해가면서 데이터를 그래프로 시각화해보았다.
Amazon QuickSight에서는이상 감지(Anormaly Insight)를 지원하여, 그래프상에서 값이 갑자기 튀는 경우에 해당 부분에 대해 ML이 이를 분석하여 글로써 서술해준다. 그 외에 추가적으로Add forecast를 사용하여 앞으로의 값 전망에 대해서 그래프상에서 확인할 수 있다.
마무리 통합 파이프라인 구축
이번 통합 파이프라인 구축 실습에서는 여지까지 실습했을때 활용되었던 Amazon CloudFormation, Kinesis data stream, Kinesis data firehose, S3, Lambda를 종합해서 실습하였다.
Kinesis data stream 부분을 직접 Kafka를 구축하거나, AWS에서 제공해주는 MSK를 사용하면 데이터 스트림 부분을 대체해서 구성할 수 있다. Kinesis client library를 이용해서 변환하는 로직을 추가해서 처리하거나 plugin을 활용해서 데이터를 변환할때에는 logstash를 연결해서 구성을 할 수도 있다.그리고 Firehose를 거치지 않고, 바로 ES쪽으로 데이터를 바로 적재하는 것이 가능하다.
우선 전체적인 데이터 파이프라인의 flow는 우선 AWS의 CloudFormation을 통해 랜덤한 dummy data를 생성해주고, 생성된 데이터를 Kinesis data stream -> Kinesis data firehose를 통해 S3 bucket에 데이터를 최종적으로 적재를 해준다. 적재된 데이터는 Athena를 통해서 쿼리를 사용해서 데이터를 필터하는 작업을 진행하도록 했다. (firehose에서 data transformation 옵션을 enable해서 생성해준 Lambda 함수를 넣어서 한 번 필터된 데이터를 S3에 저장할 수 있도록 구성하였다.(Lambda에서 제공해주는 blueprint template code활용 - 커스텀해서 작성해보기))
참고 : Lambda 함수를 설정할때 timeout에러가 발생하는 이유는 Firehose와 Lambda 함수의 time interval sync가 맞지 않아서이다. Lambda function에서 time setup에 대한 configuration을 수정해줘야한다.
S3에 적재된 데이터를 Athena를 통해서 테이블을 생성해서 쿼리로 분석을 하고, 분석 결과 데이터를 QuickSight를 통해서 시각화 할 수 있다. S3에 적재된 데이터를 direct로 QuickSight와 연동하는 작업도 해보기.
Q&A 관련 내용 정리
Q1. 데이터 엔지니어의 업무와 협업 방식
회사 규모가 커질 수록 데이터 엔지니어나 데이터 플랫폼 엔지니어로 직무를 구분하기도 한다.
데이터 플랫폼 엔지니어의 경우에는 Presto나 AWS 사용하는 것을 좀 더 손쉽게 인프라를 구축해주는 작업을 하기도 하고, Presto나 Hive와 같은 인프라들을 관리해주는 플랫폼 개발자/엔지니어로 근무를 하기도 한다.그리고 데이터 엔지니어의 경우에는 SQL을 Presto나 Hive에서 돌려서 데이터를 뽑아내는 작업만을 하는 경우도 있다.Spark job을 말아서 Airflow를 통해 스케줄링 작업을 해주고, CI/CD 배포하듯이 구축을 해주는 업무도 있다.
협업의 경우, 데이터 플랫폼 개발자의 경우에는 데이터 엔지니어들이 쓸 수 있는 플랫폼/툴을 개발하는 업무를 주로 하기 때문에 SW engineer와 DE가 서로 협업을 하는 경우도 있다. 그리고 다른 경우에는 DE가 DA나 DS와 같이 협업을 하는 경우도 있는데, DA/DS 분들이 특정 데이터들이 필요하다고 했을때, 분산되어있는 요구된 여러 데이터들을 spark를 사용해서 join 작업을 해주기도 한다.
사이드 프로젝트
활용할 수 있는 데이터 : 공공 데이터, Uber 데이터 활용하기(미국 정부에서 관리해주는 사이트 참고)
-> 배웠던 것 복습한다는 의미로 여지까지 공부했던 파이프라인 구성요소들을 활용해서 직접 나만의 파이프라인을 만들어 보고, 구축한 후에는 데이터를 분석해보는 사이드 프로젝트 진행해보면 좋다.
파이프라인을 구축했을때 왜 A라는 기술을 사용했는지와 왜 이런식으로 구성했는지에 대한 이유를 설명해주는 것도 좋다.분석 단계의 전처리와 데이터 엔지니어링 단계에서의 전처리의 차이
분석 단계의 전처리에서는 데이터가 잘못 들어가 있는 경우나, 널 값이 들어가 있는 경우에 대한 데이터 전처리 작업을 한다. 데이터 엔지니어링 단계의 전처리의 경우에도 분석가가 특정 데이터 전처리 요구를 하는 경우에는 파이프라인 상에 로직을 심어서 처리를 추가해줄 수도 있다. (
DA와의 협업)
일반적으로 데이터 엔지니어링 단계에서의 전처리는 format이나 schema와 같은 변환작업을 주로 해주고, JSON, TEXT 데이터를 Parquet, ORC 포멧으로 변경하여 데이터 엔지니어링 관점에서 효율(속도/성능)을 위한 작업을 많이 해주게 된다.DM는 언제 구축해야되는지와 DW는 어느정도 규모일때 구축을 하는지
만약에 인사팀 데이터들은 타 부서 사람들이 조회하면 안되기 때문에 이러한 경우에 별도의 DM을 구축해서 관리를 하기도 한다.
보통은 효율성을 위해서 빠르게 데이터를 조회하기 위해서 DW에 쌓인 데이터를 각 각의 개별 SCHEMA를 가진 DM으로 쌓아서 관리를 한다. (조직의 정책에 따라)많은 경우에는 DW만 구축을 해주고, 새롭게 테이블만 구축해서 접근 권한만 다르게 부여해서 활용되는 경우도 많다.
VPC 활용 및 나누는 방법
VPC는 네트워크나 보안 정책에 따라 구분된다. 이 부분은 데이터 엔지니어의 영역이 아닌, Cloud Architecture나 네트워크 엔지니어의 영역이다.
글로벌 기업의 경우에는 해외 각국에 지사가 나뉘어져 있기 때문에 국가별로 VPC로 나눠서 각 VPC를 peering해주기도 한다. (회사 정책별로 상이)
기업사례
AWS를 활용하여 Lambda Architecture 구축
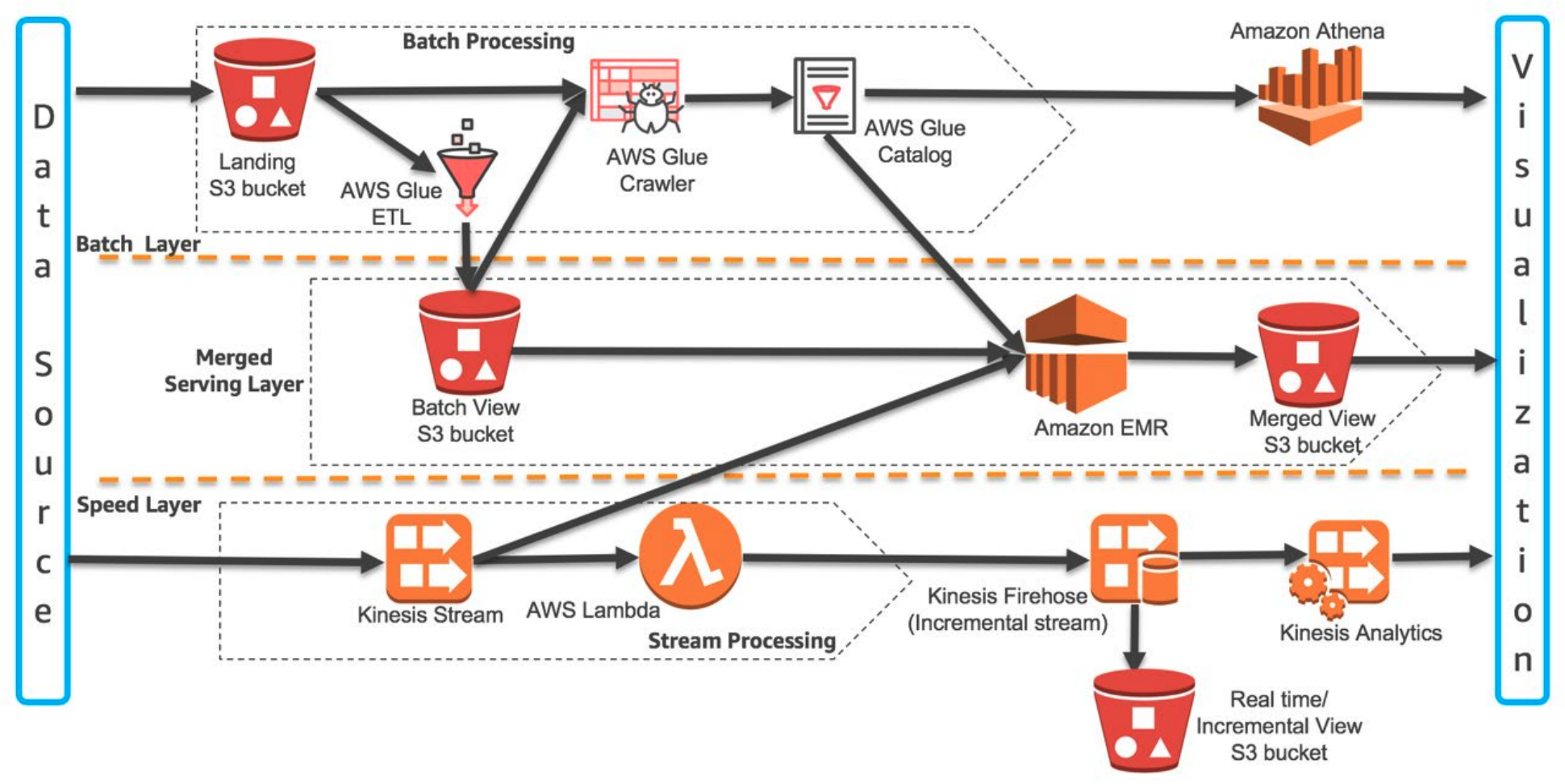
이 Lambda Architecture는 오프라인 수업 초반에 배웠듯이 Batch 데이터 처리와 Streaming 데이터 처리의 장/단점을 서로 보완해주기 위해 등장한 모델이다.
위의 그림에서 보면, Batch 처리에서 S3에 데이터를 적재해주고, S3에 적재된 데이터를 metadata를 저장하고 있는 AWS Glue를 통해 Athena에서 데이터를 분석하고 있다. 또한 처음에 S3 bucket에 데이터가 적재되었을때, ETL 작업을 통해 또 다른 Batch View S3 Bucket에 데이터를 다시 저장하고 있다.
Streaming data의 경우에는 Kinesis Stream을 통해서 데이터를 넘겨주고 있고, 넘겨진 데이터를 AWS Lambda를 통해 데이터 변환을 한 다음에 Kinesis Firehose를 통해 Kinesis Analytics로 이동해서 분석 환경을 구축하기도 하고 S3에 데이터를 적재해주기도 한다.
중단부를 보면, Batch 처리를 통해 적재된 Batch View S3 bucket과 Kinesis stream을 통해 바로 넘겨진 데이터를 Amazon EMR을 통해 데이터를 통합해서 통합된 데이터를 Merged View S3 bucket에 저장을 하고 있다.
AWS Glue
Athena를 사용해서 테이블을 만들게 되면, 필드를 일일이 지정을 해줘야 했지만, Glue Crawler를 이용하면 데이터를 자동으로 parsing해서 테이블로 만들어준다. 그리고 AWS Glue에는 AWS Glue Catalog 기능이라고 해서 내가 가지고 있는 데이터가 어떤 field나 schema를 가지고 있는지, 전체 메타 정보를 가지고 있다.
AWS Glue Catalog에서 직접적으로 pySpark를 통해서 분석을 할 수도 있다.HDFS vs S3 사용
S3는 모든 AWS의 각종 서비스들을 연결시켜주는 anchor point의 역할을 해주기도 한다. 그리고 데이터 governance를 S3에 걸 수 있기 때문에 데이터의 저장용도로 S3를 주로 활용한다. (
S3는 AWS의 Killer App이다)
REDSHIFT에 데이터를 쌓아도 되는데, S3에 쌓아놓고 REDSHIFT SPECTRUM에 저장을 할 수 있기 때문에 이러한 S3의 확장 가능성때문에 주로 사용이 된다.
Uber data architecture
[참고] : https://eng.uber.com/uber-big-data-platform/
우버에서 데이터 아키텍처 구조의 변천사에 대해서 살펴볼 수 있다. 각 아키텍처의 구조를 변경했을때 한계점에 대해서도 위의 페이지에서 명기를하고 있으며, 2015-2016년에 들어서 하둡 에코 시스템을 도입한 내용도 유익하기 때문에 한 번 읽어보기를 권장한다.
2017-현재까지 Kafka를 사용해서 데이터를 처리함으로써 이전 하둡 시스템을 사용했을때와 비교했을때 데이터 처리의 민첩성을 향상시켰다.(
이전 24h(end to end)에서 30min 미만 raw data, 1시간 미만으로 modeling되도록 개선)
주로 Batch 처리를 하지 않고 Streaming 처리를 하는 이유는 latency를 개선하기 위해서이다.
Twitter
초기 old lambda architecture 도입부터 Twitter는 GCP를 많이 사용하기 때문에 GCP의 kinesis와 같은 서비스를 (Pub/Sub 구조) 활용해서 변경까지의 내용을 담고 있다.
아키텍처 구성의 변화를 통해 Latency가 많이 개선되었음을 확인할 수 있다.
(Kinesis로 데이터를 받아서 S3에 저장한 다음에 Athena로 데이터를 조회하는 구조가 Twitter에서 GCP를 사용해서 새롭게 도입한 데이터 아키텍처 구성으로 볼 수 있다.(유사))
쏘카
국내에서 데이터 엔지니어링으로 유명한 기업
차량용 단말을 위한 IoT 파이프라인 구축
AWS IoT Core, Amazon MSK, Amazon S3
- AWS IoT Core로의 전환
쏘카에서는 기존에 Telemetrics Server가 차량 단말기로 HTTPS 호출을 통해 필요한 데이터들을 수집하는 구조로 되어있었지만, MQTT 프로토콜을 지원하는 브로커와 AWS IoT Core의 사용으로 대체를 하면서 좀 더 효율적인 데이터 파이프라인을 구성할 수 있었다.
Kinesis 사용
(아래 문제상황과 시도 그리고 해결과 관련된 내용은 쏘카 기술블로그에서 참고한 내용입니다)
Kinesis는 좋고 편리한 서비스이지만 consumer가 많아질수로 기하급수적으로 서비스 사용하는 비용이 올라간다.
또한 Kinesis stream을 사용하는 프로젝트가 늘어날수록(Kinesis stream에서 받아서 처리하는 consumer가 늘어날수록) 파이프라인이 복잡해지고,
파이프라인을 관리하는 주체가 없는 상태에서 불 필요하게 많은 Consumer가 연결이 되면서 Kinesis stream에 많은 수의 Lambda 함수, 많은 Process들이 붙게 되고, 이로인해 결과적으로 Kinesis stream에 병목이 생기는 경우가 생겼다.(문제상황인지)
(시도) 더 많은 처리량을 위해 샤드(샤드 당 1초에 최대 2MB의 데이터 처리)를 늘리기도 하고, 향상된 팬 아웃 기능을 사용하여 상황 극복이 가능하다. 하지만 이는 서비스 사용 비용 증가와 직결되어 근본적인 문제 해결을 위한 해결책이 되지 못했다.
이러한 문제상황과 시도를 통해 MSK로 변경을 하여 좀 더 안정적인 새로운 파이프라인을 구성하였다.(해결)
실제로 EC2에 Kafka를 구축하여 운영할 수도 있지만 운영 비용을 줄이면서 Kafka를 사용하고자 MSK를 사용한다.Kinesis Stream 병목
[참고] https://tech.socarcorp.kr/mobility/2022/01/06/socar-iot-pipeline-1.html
쏘카에서는 AWS IoT Core 서비스를 활용해서 데이터 아키텍처를 개선하였다. 쏘카 서비스 구조상 차량에서 서버쪽으로 계속 차량에서 수집한 정보를 넘겨주고, 서버쪽에서는 차량을 제어하기 위한 명령을 내려주는 구조로 되어있다. (단말과 서비스)
MQTT 프로토콜에서 지원하는 브로커를 사용해서 단말과 서버와의 통신을 하도록 구성을 하였다.
[배운점]
쏘카의 Kinesis stream 병목에 대한 글을 통해 많은 것을 배울 수 있었다. 나는 AWS에서 제공해주는 서비스에는 streaming 데이터 처리에 있어 별다른 문제가 없을 것이라고 생각을 했는데, 실제 shard 수와 각 shard마다 감당할 수 있는 데이터의 양이 한정되어 있기 때문에 설정해준 shard 수와 실시간으로 전송되는 데이터의 수에 따라 병목현상이 일어날 수도 있다는 것을 배웠다.
이러한 병목현상을 해결하기 위해 기존 Kinesis를 KMS(Kafka의 완전 관리형 서비스)로 전환을 하여 별도의 모니터링을 통한 shard 수 변경없이, Kafka의 완전 관리형 서비스인 Amazon MSK를 사용해서 문제 상황을 해결할 수 있다는 점도 배울 수 있었다.
그리고 RaspberryPi를 활용해서 실제 센서의 데이터를 MQTT라는 메시지 프로토콜에서 지원하는 브로커(mosquitto)를 사용해서 AWS IoT Core 서비스(관리형 메시지 브로커 서비스)로 보내도록 구성을 해봤었는데, MQTT 프로토콜에서 지원해주는 브로커를 거치지 않고도 AWS IoT Core를 통해 직통으로 IoT 단말기로부터 데이터를 받아서 처리할 수 있다니, 한 번 방법을 찾아보고 변경된 구조로 데이터 파이프라인 구조를 재구성해봐야겠다.
그리고 나는 IoT 기기로부터 센서 데이터를 받아서 처리하는 실습을 개인적으로 했기 때문에 안정성까지 고려하여 클러스터링을 지원하는 브로커인지 고려하지 않았지만, 찾아보니 내가 사용한 mosquitto 브로커의 경우에는 클러스터링을 지원하지 않고, HiveMQ와 같은 브로커만 클러스터링을 지원한다고 한다.
또 HiveMQ의 경우에는 AWS나 Azure와 같은 Cloud provider에서 동작을 잘 하고, auto-discovery, distributed masterless architecture를 지원하기 때문에 다음에 좀 더 안정성을 요구하는 상황에서 데이터 파이프라인을 구축할때에는 HiveMQ를 활용해봐야겠다.
(좀 더 찾아보기 - mosquitto가 clustering을 지원하는지에 대해 좀 더 찾아보자)
- AWS IoT Core로의 전환
넷마블
아키텍처보다 공부할만한 내용이 많기 때문에 읽어보면 도움이 된다. (
데이터 파이프라인의 기본 원리와 원칙 및 분산환경에 대한 내용)카카오
데이터 엔지니어링 ?
https://tech.kakao.com/2020/11/30/kakao-data-engineering/대량의 스트림 데이터를 실시간으로 분류하기 (Elasticsearch percolator)
https://tv.kakao.com/channel/3693125/cliplink/423590245(자료)
https://t1.kakaocdn.net/service_if_kakao_prod/file/file-1636524938152- 분류할 데이터나 필터가 많은데 빠르게 분류하고 싶은 경우
- 데이터 기반 실시간 알람(문자열 매칭)
- 특정 조건에 만족하는 중고 제품이 올라오면 알람
Druid@Kakao
https://tv.kakao.com/channel/3693125/cliplink/423590646(자료)
https://t1.kakaocdn.net/service_if_kakao_prod/file/file-1636526360840- Druid 도입 사례 및 Multi-Tenant 클러스터 소개
- 데이터 실시간 처리 관련 문제를 해결하고 싶은 경우
카카오 공용 하둡 운영 사례
https://tv.kakao.com/channel/3693125/cliplink/423590637(자료)
https://t1.kakaocdn.net/service_if_kakao_prod/file/file-1636526054873카카오의 전사 리소스 모니터링 시스템카카오의 전사 리소스 모니터링 시스템은 크게 숫자 데이터를 모니터링하는 STAT(
KEMI-STATS), 로그 문자 데이터를 모니터링하는 LOG(KEMI-LOG)로 분류하여 구성이 되어있으며,STAT METRIC 데이터의 경우에는여러 데이터 리소스들을 카프카를 통해서 받아서SAMZA(Metric Calculator)와 같은 실시간 처리 엔진을 붙여서 전처리를 해주고, OPEN TSDB라는 곳에 적재를 한 다음에 분석을 하고 있다.LOG 데이터의 경우에는fluentd로 수집을 하고, fluentd로 다시 모아서 Lambda Architecture로 구성을 한 파이프라인에 로그 데이터를 흘려서 보내주고 있다. 실시간으로 카프카로 넘겨지는 데이터를 알람과 전처리를 위해서 스톰을 배치하고 있고, 최근에는 Flink로 대체해서 구성을 하고 있다고 한다.
네이버
네이버 플레이스(장소 검색
ex.맛집)에서는 플레이스 데이터 플랫폼을 구축하고 있다.
(어뷰즈 검출 사례)데이터 명세에 대한 내용 포함(format, schema)
protobuf는 GRPC 바이트 인코딩해서 속도가 매우 빠르고, GRPC가 사용하고 있는 직렬화 방식을 사용하고 있기 때문에 참고해보기
https://medium.com/naver-place-dev/%ED%94%8C%EB%A0%88%EC%9D%B4%EC%8A%A4-%EB%8D%B0%EC%9D%B4%ED%84%B0-%ED%94%8C%EB%9E%AB%ED%8F%BC-%EA%B5%AC%EC%B6%95%EA%B8%B0-%EC%96%B4%EB%B7%B0%EC%A6%88-%EA%B2%80%EC%B6%9C-%EC%82%AC%EB%A1%80-e9caa31511dcCDC(
Change Data Capture)툴이 DBMS에서 적재된 데이터에서 변경된 데이터만 캡처해서 Kafka와 같은 실시간 데이터 스트림 처리하는 곳으로 넘겨서 데이터를 추출해서 처리해주는 역할을 해준다.
토스
- 토스 데이터의 흐름과 활용
https://toss.im/slash-21/sessions/2-1
- Sqoop(SQL to Hadoop): Hadoop과 RDB간 데이터를 전송할 수 있는 오픈소스로, RDB의 특정 테이블 또는 쿼리 결과를 HDFS로 쉽게 옮길 수 있다.
- 토스 데이터의 흐름과 활용
우아한 형제들
데이터 분석 플랫폼, AWS 이관기
https://www.youtube.com/watch?v=rH_xJBoRuZE- AWS EMR에서 온프레미스로 전환
- AWS Athena, Trino 비교 및 Trino 사용기
- Graviton2 (ARM 기반의 EC2 인스턴스) 사용기
- Zeppelin 사용기 (대화형 분석/시각화 도구)
로그 데이터로 유저 이해하기
https://techblog.woowahan.com/2536/실시간 인덱싱을 위한 Elasticsearch 구조를 찾아서
https://techblog.woowahan.com/7425/
쿠팡
Big Data Platform: Evolving from start-up to big tech company
https://medium.com/coupang-engineering/evolving-the-coupang-data-platform-308e305a9c45왓차
단일 클라우드 플랫폼이 아닌 다양한 클라우드 플랫폼을 같이 사용해서 데이터 파이프라인을 구성
https://medium.com/watcha/%EB%A9%80%ED%8B%B0%ED%81%B4%EB%9D%BC%EC%9A%B0%EB%93%9C%EB%A5%BC-%EC%9D%B4%EC%9A%A9%ED%95%9C-%EB%A1%9C%EA%B7%B8-%EB%B6%84%EC%84%9D-%ED%94%8C%EB%9E%AB%ED%8F%BC-%EA%B0%9C%EB%B0%9C%ED%95%98%EA%B8%B0-8c5f671df559줌 인터넷
검색 데이터 서빙 플랫폼 구축
file:///Users/hyungilee/Desktop/Data%20engineering/Pipeline/Learning%20spoons/220703_Day6.pdf
AWS IoT Core
- 관리형 서비스
- MQTT, HTTPS, LoRaWAN등의 프로토콜을 지원
- 기기간 메시지를 AWS 서비스에 라우팅
- IoT 전용 데이터 스트림 역할을 해준다.
Q&A Section
Queue 서비스(MQ/SQS)와 스트리밍 서비스(Kinesis/Kafka)의 선택시 주요 포인트
-> SQS를 사용하는 경우는 확장성을 고려해야한다. SQS는 단순 큐로써, 스케줄링을 하거나 작업을 순차적으로 처리해야되는 경우와 같이 간단한 경우에는 SQS를 사용해도 괜찮다.(
초당 3천개 정도는 커버 가능) 하지만 빅데이터를 처리해줘야되는 경우에는 Kinesis를 고려해야하고, 더 확장성 있는 구조를 고려해야된다면, Kafka를 고려해줘야 될 수도 있다. Kafka + lambda 구조로 사용하는 경우는 괜찮지만, 더 많은 consumer가 붙어서 처리되는 경우에는 요금부하가 생기기 때문에 이 경우에는 lambda 대신에 Kafka connector, Kafka streams를 사용해서 DocumentDB로 넣어주는 것이 권장된다고 한다.스트리밍 데이터를 여러 컨슈머 그룹으로 묶여서 처리를 해야되는 경우와 데이터가 일정기간동안 저장 가능해서 replayable하다는 장점을 가져와야 되는 경우에는 Queue 서비스 보다는 스트리밍 서비스를 선택해서 사용하는 것이 권장된다. 그리고 들어온 데이터가 순서를 보장해야되는 경우에는 Queue 서비스인 SQS를 사용해서 처리해주는 것이 좋다. (
Kafka를 사용해서 단일 브로커로 구성해서 데이터 순서를 보장해서 처리를 해줄 수도 있다) 그리고 로그 데이터는 SQS를 사용할 필요는 없다고 한다.초당 3000개 이상의 사용자의 API 호출 로그를 Kinesis로 보내고, Lambda를 이용해서 DocumentDB(NoSQL)로 넣는 구조를 하고 있는데, Kinesis의 write 성능 제한으로 peak hour에 reject 되는 경우가 있어서 On-failure destination SQS(
실패한 경우에 SQS로 넣어주는 것을 고려)를 지정해서 사용하는 것을 고려중.