
이번 포스팅에서는 다섯 번째 데이터 파이프라인 구축 오프라인 수업시간에서 배운 내용을 정리하려고 한다.
Flink
우선 실습에 앞서 간단하게 Flink에 대해서 정리를 해보자. Flink는 분산 데이터 처리 프레임워크 (Processing unbounded data)로, Kafka와 같은 MQ에 Flink를 붙여서 처리를 할 수 있다. 이외에도 MQ에 Kinesis Firehose를 붙이고, Lambda를 붙여서 custom한 형태의 데이터로 추출을 할 수도 있고, 데이터를 암호화하거나 특정 format(Parquet, ORC)으로 변환을 해서 추출을 할 수도 있다.
또 Logstash를 붙여서 데이터를 간단하게 처리해서 넘겨줄 수 있다. (whitelist / filter plugin을 통해 처리) 커스텀하게 데이터를 모아주거나 분석을 하는 경우, 예를들어 GPS 신호를 계속 보내서 사용자들이 이 데이터를 1분동안 aggregation해서 어느 지역에 사람이 많은지 분석하는 작업은 logstash로 분석을 하는 것이 불가능하다. 그리고 각 각의 logstash로 나눠서 분산처리를 하는 것은 가능하지만, 각 각의 logstash가 서로 데이터를 공유하지는 못하기 때문에(클러스터 내의 노드로써 존재하지 않기 때문에) 복잡한 스트림 처리나 프로세싱, 분석이 필요할때 Flink를 사용한다.
그리고 Flink, Storm을 개발할때에는 DAG를 많이 사용한다. Kafka에서 받아온 실시간 데이터를 키별로 분류를 하는 작업에서도 사용이 될 수 있는데, 게임 데이터를 분석한다고 가정했을때 각 캐릭터의 직업에 따라 분류를 해서 각 직업별로 행동 패턴을 분석하고자 할때 각 각의 Dataflow를 머릿속으로 구조화시킨 다음에 붙여주는 작업을 해야한다.source operator(Kafka) -> keyBy operator -> aggregation operator -> HDFS sink Flink와 같은 데이터 플로우 프로그래밍이 필요한 어플리케이션은 operator와 같은 요소를 하나 하나 개발을 한 다음에 연결을 해주는 방식으로 개발을 하게 된다.
DB ETL작업을 할때 DB에서 주기적으로 데이터를 select해서 Flink내부에서 처리를 하고자 할 때에도 source operator를 사용한다. (Flink 외부에서 데이터를 긁어오는 부분을 source operator)
중간에서 데이터를 변환해주는 부분을 Transformation Operator라고 한다. 그리고 처리 결과를 밖으로 빼내는 부분을 Sink Operator라고 한다.
Flink parallelism
실제 flink로 어플리케이션을 개발하게 되면, 수십개의 TM가 생성이 된다.
개발을 할때 각 각의 operator의 갯수를 parallism을 통해 정의할 수 있다.
Kafka(3) -> Map(10) -> Sink(3) => 16개의 operator가 TM의 각 각의 노드에 분산이 되어 처리된다. 이와같은 특징으로, Fluentd와 logstash와 같은 agent 기반의 데이터 파이프라인과 비교되어 사용된다.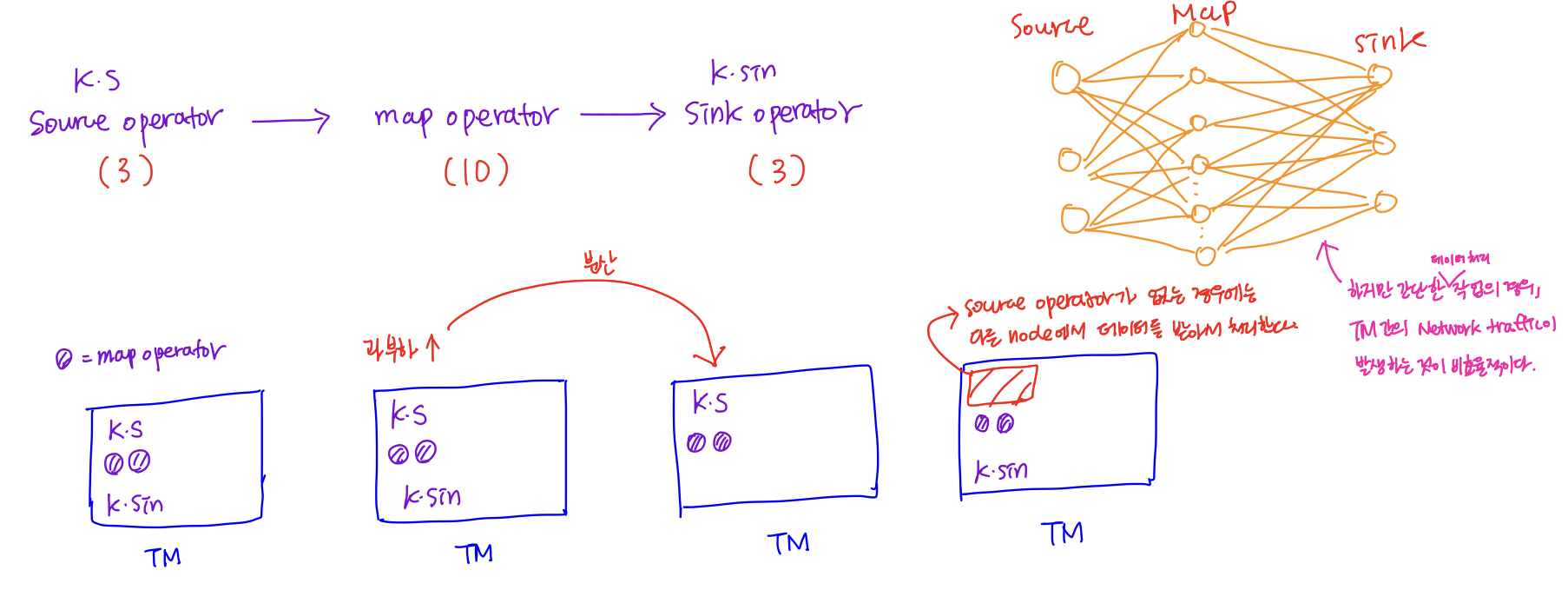
Code 구현
1
2
3
4
5
6
7
8
9
10
11// Source operator 구현
DataStream<String> lines = env.addSource(new FlinkKafkaConsumer<>());
// Transformation operator 구현
DataStream<Log> logs = lines.map((line) -> parse(line));
// Transformation operator 구현 (위의 Transformation 결과 변수를 또 다시 변형)
DataStream<Statistics> stats = logs.keyBy("id")
// 10초마다 데이터를 끊어서 처리
.timeWindow(Time.second(10))
.apply(new MyWindowAggregationFunc());
stats.addSink(new CustomSink(path));Operator Chaining
각 각의 노드들에 분산되서 처리되서 처리되는 것 보다는 서로 연관있는 operator나 데이터를 주고 받지 않고 바로 바로 처리해도 되는 요소의 경우에는 operator chain을 해서 효율성을 높일 수 있다.
https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/operators/overview/
[실습] Flink cluster
이번 Flink 실습에서는 EC2 instance에서 Flink를 설치하고, 웹 상에서 Flink cluster를 관리할 수 있다. 따라서 default로 설정이 되어있는 SSH(21) 포트 외에 추가적으로 8081 port를 열어줘야한다. (Inbound rule 수정)
Flink 설치
https://www.apache.org/dyn/closer.lua/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.12.tgz
1
2
3
4
5
6
7$wget https://dlcdn.apache.org/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.12.tgz
$tar -zxvf flink-1.14.5-bin-scala_2.12.tgz
$cd flink-1.14.5-bin-scala_2.12
$sudo apt install openjdk-11-jdk실습에서는 하나의 EC2 instance 내에 JM, TM을 각 각 하나씩 두지만, 실제로는 (
EC2, Kubernetes, YARN과 같은 컨테이너 환경에서 개별로 존재)JM가 따로, TM도 서로 다른 컨테이너안에서 개별 노드로 존재한다.1
2# 설치한 flink 디렉토리 안의 bin 폴더
$./bin/start-cluster.shFlink에 실행할 Application import
Java로 코드를 작성한 다음에 *.jar 파일로 추출을 해서 브라우저 UI 상에서 Job을 제출하거나 터미널상에서 실행을 할 수도 있다.
Browser UI상에서 Job submit1
2
3Entry Class : org.apache.flink.streaming.examples.multiple.SocketMultiple
Parallelism: 1 #TM를 1개
Program Arguments: --hostname localhost --port 9090Terminal 상에서 Job submit1
2
3$./flink-1.14.5/bin/flink run [실행할 job의 *.jar 파일] --hostname localhost --port 9090
# 또는 원격지 (PC)에서 생성한 EC2 인스턴스의 주소를 통해 Flink로 코드를 실행할 수도 있다.EC2 Instance에서는 flink에서 Listen할 data source operator의 역할을 해주기 위해서 9090 포트를 열어서 데이터를 입력해줘야 한다.
1
$nc -l 9090
EC2 instance에서 9090 포트를 열어준 다음에 문자를 입력해주게 되면, 처리결과를 아래와 같이 터미널상에서 log 파일을 직접 확인하거나, Apache Flink Dashboard의 TM의 항목을 통해 처리 결과를 확인해줄 수 있다. (
Stdout)다시 Flink에서의 데이터 처리 흐름을 살펴보면, Socket에 붙어서 텍스트를 입력을 해주게 되면 Flink Application에 source로 데이터가 들어가게 되고, Transformation operator(Map function)을 통해 데이터가 정제되서 최종적으로 Sink operator(Stdout)을 통해 출력을 해주게 된다.
Apache Flink Dashboard
Apache Flink Dashboard에서 Overview 메뉴를 통해 현재 실행중인 Job이 몇 개인지 확인할 수 있고, JM, TM의 상세 정보(Total Process Memory/Total Flink Memory/TM의 heap 메모리 영역)를 확인할 수 있다.
JM의 Running job 항목을 클릭해보면, operator에 대한 정보를 확인할 수 있는데, 클릭하면BackPressure/Idle/Busy정보(%)를 확인할 수 있는데 이 부분에 대한 확인이 중요하다.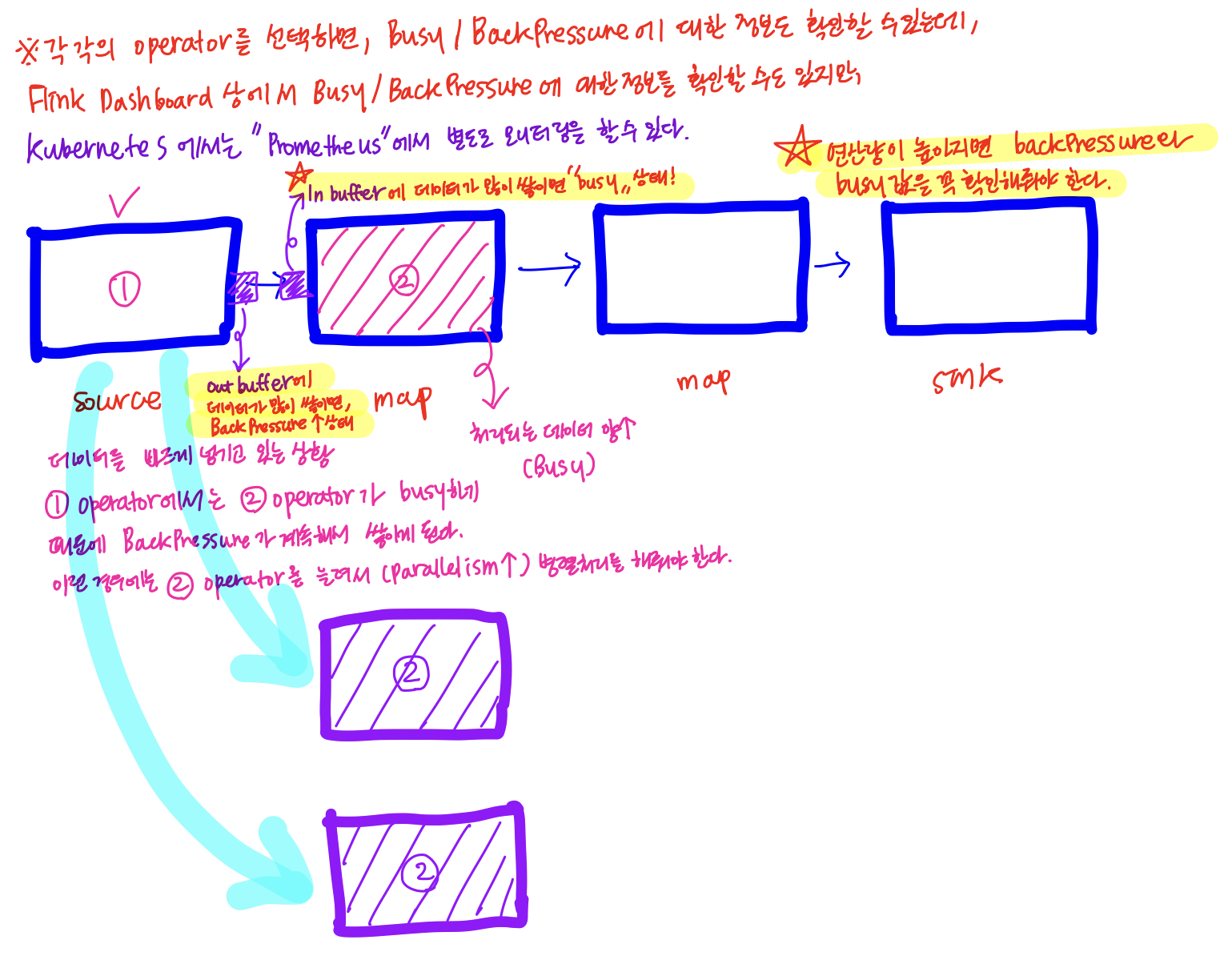
- Flink와 관련된 서비스를 제공하는 third party 서비스사에서 제공하는 샘플 코드도 한 번 보기(코드 참고해서 직접 커스텀 어플리케이션 만들어보기)
시각화 및 분석 툴
이번 파트는 많이 유용할 것 같다. 지금 프로젝트로 정리하고 있는 데이터 파이프라인 중에 Amazon EMR로 데이터를 정제하고, DW, DM까지만 데이터를 적재하는 부분까지만 했었는데, 이번 5주차 수업을 통해서 그 다음 파이프라인에서는 어떤식으로 데이터를 분석하고 시각화할지에 대해서 아이디어를 얻을 수 있었던 것 같다.
Elasticsearch
Apache Lucene를 기반으로 한 오픈소스 분산 검색 엔진이다.
루씬(Lucene)
Lucene이란 자바로 만들어진 고성능 정보 검색(IR: Information Retrieval)라이브러리로, 여기서 IR이란 문서를 검색하거나, 문서의 내용을 검색하거나 문서와 관련된 메타 정보를 검색하는 과정을 의미한다.
그리고 Lucene은 파일 검색이나 웹 문서 수집, 웹 검색 등에 바로 사용할 수 있는 어플리케이션이 아닌,검색 기능을 갖고 있는 어플리케이션을 개발할 때 사용할 수 있는 라이브러리이다.JSON 기반의 문서를 저장하고 검색할 수 있다. (
이러한 이유로 로그와 같은 JSON형태의 데이터를 쉽게 저장할 수 있는 데이터베이스, NoSQL와 같이 사용이 되고 있다)로그를 수집하고 조회하는 용도(로깅 & 모니터링)/ 통합 로그 분석 및 보안관련 이벤트 분석에 사용되고 있다.
실시간 집계 및 데이터 분석 용도로도 사용되고 있다.
ML 기능도 추가가 되어, ML 엔진으로도 활용되고 있다.
Elasticsearch는 온프레미스 환경에서 로컬로 서버를 구축할 수도 있고, AWS상에서만 효율적으로 활용할때에는 QuickSight를 사용하기도 한다.
그리고 Elasticsearch는 데이터 검색 엔진으로 나왔지만, 최근에는 short term 데이터 저장소로도 활용이 되고 있다. 시각화 툴로써도 기능이 좋지만, 전문 BI 툴에 비하면 부족한 면이 있지만, 엔지니어에게 있어서 기능적인 면은 충분하다.(분석가, 데이터 사이언티스트에게 있어서는 부족한 부분이 있다)
그 이유는 엔지니어에게 있어서는 로그 데이터를 뽑아서 관련된 정보를 보거나, 그래프로 그리는 툴정도로만 활용이 되기 때문이다.
그리고 ElasticSearch는 Server side 어플리케이션으로, UI가 없기 때문에 Kibana가 붙어서 시각화 처리를 해준다.데이터 베이스에서 Query를 통한 처리와 Elasticsearch에서의 처리의 차이
실제 DB에 일일이 Query를 작성해서 원하는 데이터를 추출 할 수는 있지만, 그에 대한 한계점이 명확하기 때문에 ES를 사용한다. 대표적인 한계점으로는 데이터베이스의 query 연산은 느리고 부하가 높으며, 공백이나 띄어쓰기를 포함한 exact 연산을 기반으로 한다는 단점이 있다.
ES의 특징
- 준실시간 검색 엔진(Full text Search)
- 클러스터링을 통한 안정성 강화와 부하 분산
- 다양한 형태의 문서도 동적으로 인데싱되어 검색이 가능하다.(Schemaless)
-> JSON 기반으로 문서를 제공하기 때문에 NoSQL로 분류를 하기도 한다. - REST API로 검색을 할 수 있기 때문에 별도의 드라이버나 라이브러리 없이 연동이 가능하다.
- 역색인(Inverted Index) : 검색어가 포함된 모든 문서를 조회하는 것이 아닌,
해당 검색어가 포함된 모든 문서의 위치를 알 수 있다.미리 검색을 통한 indexing을 해주기 때문에 검색에 대한 성능이 좋다. - 확장성과 가용성이 좋다.
RDBMS와 Elasticsearch의 차이점
Elasticsearch는 단기 저장소로도 사용이 된다고 했는데, RDBMS와는 아래와같은 차이점이 있다. 아래의 도표에서 Elasticsearch의 Type은 최신 버전에서 개념적으로 사라지고 있다.
Index는데이터 저장 공간으로, 검색의 범위가 될 수 있다.(Query에서 테이블과 같은 역할,server-log-2022.06.27또는server.log-2022.06.27로 날짜 또는 앞의 데이터 타입에 따라 데이터를 구분하여 읽을 수 있게 해준다)그리고Shard는primary와 replica로 구분이 되는데, 문서를 저장하는 단위 중 하나로, 하나의 인덱스가 여러 물리적인 단위인 샤드로 나뉘어서 분산되어 저장이 된다. 그리고 이 Shard 단위로 replica가 된다.Document는 데이터의 최소 단위(row)로, 다수의 필드로 구성이 되어 있으며, 기본적으로 JSON format으로 제공된다.Field는 문서를 구성하는 column으로, 동적 데이터 타입이다. (성능을 높이기 위해서는 타입을 static하게 assign해주는 것이 좋다)
하나의 Document는 특정 Index의 특정 Shard에 속한 데이터 조각으로, JSON의 Key-value 형태로 Mapping이 되어있다.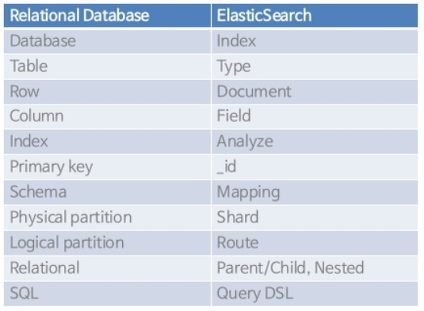
ES node의 역할
Elasticsearch에는 여러 종류의 노드들이 존재한다.
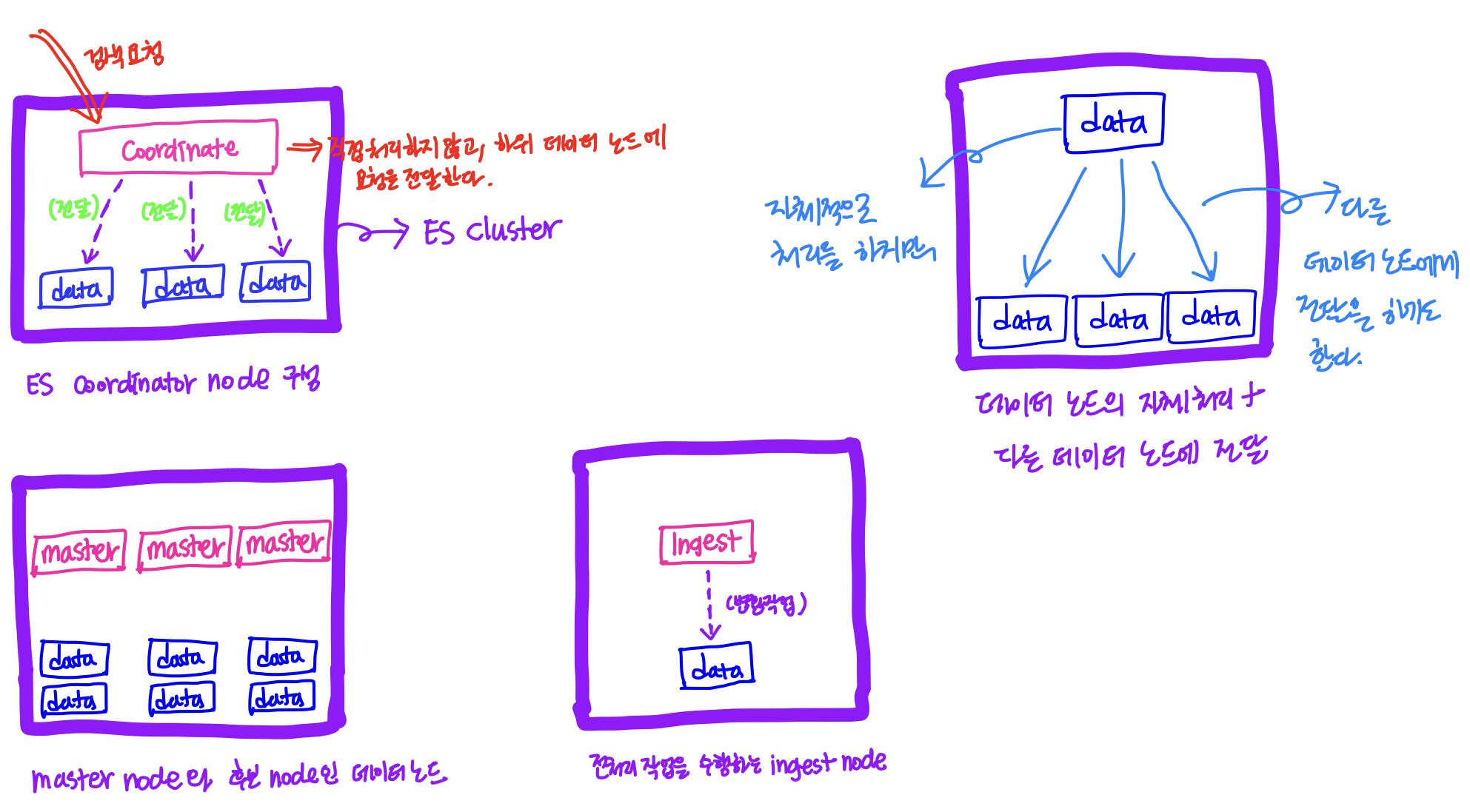
[Master node]
마스터 노드는 클러스터의 상태와 각종 메타데이터를 관리하는 역할을 한다.
- **[Data node]**Document를 저장하고 조회하는 역할을 한다. 이 Data 노드에 여러가지 role을 적용할 수 있다. (
한 노드가 다양한 노드의 역할을 수행할 수도 있다.)
데이터 저장
[Ingest node]
실제로는 Master node와 Data node만 존재해도 되지만, Document에 저장이 되기 전에 전처리 작업이 필요한 경우에는 Ingest node가 필요하다. (
Data node에 Ingest node의 역할을 부여)
[Coordinate node]
요청을 데이터 노드로 전달하고, 다시 데이터 노드로부터 결과를 취합하는 역할을 하는 노드이다.
[이외의 다양한 노드의 roles]
data_hot, data_warm, data_cold, ml(
GPU가 붙어있는 노드), etc…
[이외의 다양한 노드의 roles]
Elasticsearch를 운영/관리할때에는 JVM의 heap을 얼마나 설정하느냐와 Shard 수 및 Shard 당 용량 그리고 Replica 수, 클러스터 노드 수, OS 메모리 용량 등 고려되어야할 부분이 많다. 구체적인 내용은 아래의 노트 필기를 확인해보고, Elasticsearch를 직접 서버에 올려서 구성할때 아래의 조건들을 직접 적용시켜가면서 운영해봐야겠다.
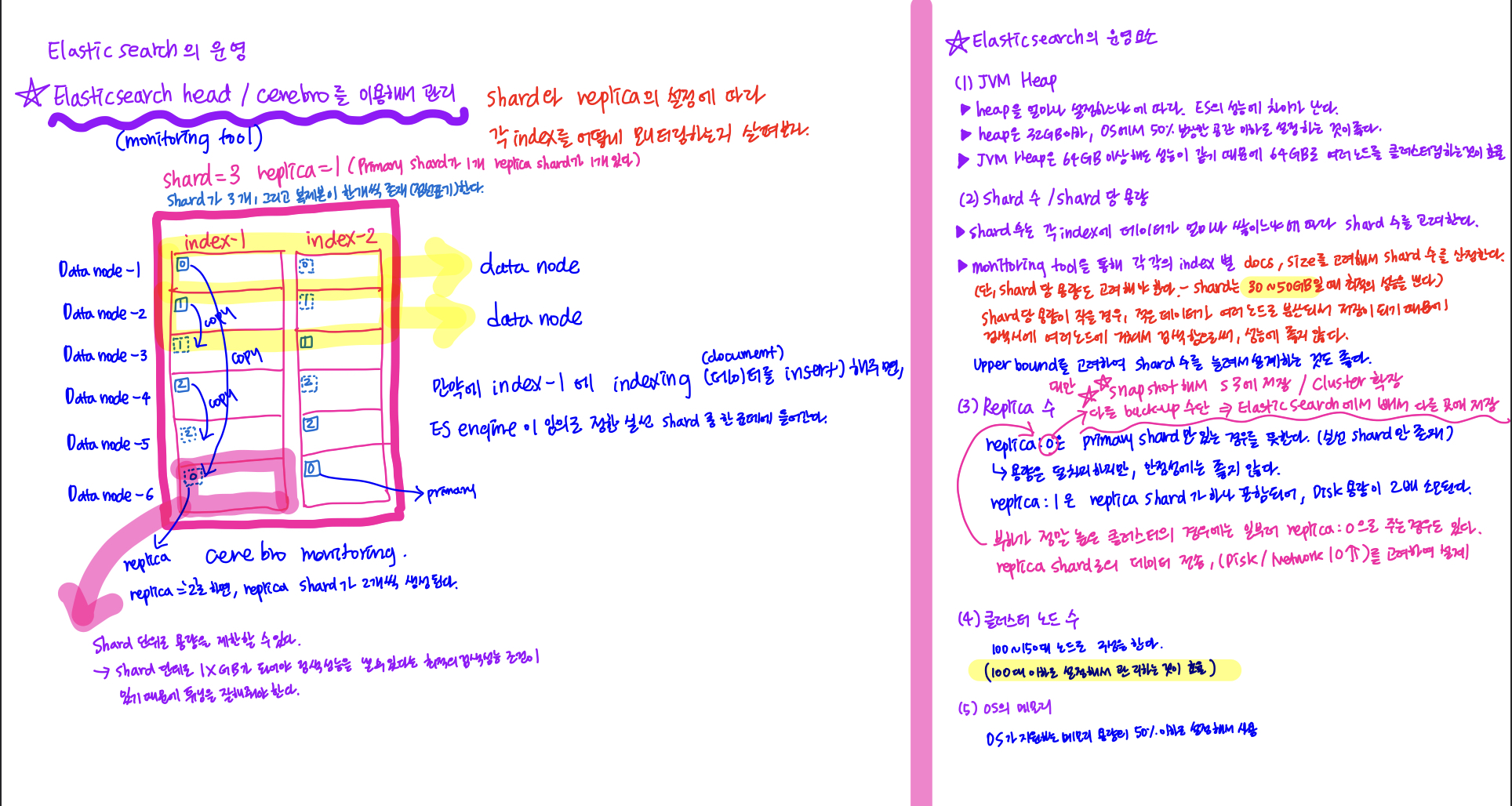
- **[상황예시]**데이터 노드를 구성할때에는 데이터 노드의 종류인 hot, warm, cold 중에서 최신/조회 수가 많은 데이터들을 담아두는 hot node를 구성한다.(
SSD) 1주일내에 들어온 데이터가 조회 수가 많은 데이터라면, hot node에 담아두고, 1주일이 지나면 자동으로 warm data node(HDD)로 migration할 수 있도록 해줄 수 있다.
이와같이 장비와의 호환성을 맞춰서 각 각의 데이터 노드를 구성할 수 있다.
ELK Stack
ELK stack은 Elasticsearch(데이터 저장 및 검색 엔진 / Short term 데이터 저장소로도 활용), Logstash(데이터 수집 및 전처리), Kibana(데이터 시각화)로 컴포넌트들이 구성이 되어있다. 그리고 ELK를 구성하는 각 컴포넌트들은 Elastic 기업에서 진행하고 있는 In-house 프로젝트들로써 각 컴포넌트들 간의 호환성이 좋다.
ref.EFK(Elasticsearch Fluentd Kibana) 스택을 사용할 수도 있다.Kibana
Kibana는 Elasticsearch에 붙여서 데이터를 검색하고, 시각화해주는 UI dashboard이다.
일일이 사용자가 API 요청을 Elasticsearch의 데이터 노드들에 날려서 데이터를 검색할 수 없기 때문에 Kibana가 이러한 번거로움을 개선하여,ES와 사용자 간의 인터페이스 역할을 해준다.
시각화는 다양한 시각화 도구를 제공(막대, 원형, 표, 히스토그램, 히트맵 등)해준다.
Amazon OpenSearch Service
Amazon OpenSearch Service는 AWS의 Elasticsearch 관리형 서비스로, 오픈소스 라이센스의 문제로 인해 AWS 측에서는 Elasticsearch를 fork하여 별도의 프로젝트로 관리 및 서비스하고 있다고 한다.
v7.10까지는 기능이 모두 동일하고, OpenSearch 초기 버전은 Elasticsearch와 거의 동일하다.
Elasticsearch & Kibana 설치/운영
Window, mac, Linux 로컬 환경에서 설치를 하고 테스트를 할 수도 있지만, docker container 기반으로 Elasticsearch와 Kibana를 설치해서 테스트를 할 수도 있다.
[Elasticsearch 설치 in local]
https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html
[Elasticsearch와 Kibana를 docker에 설치]
https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html
[실습] Amazon Opensearch 서비스
[Create domain]으로 새로운 도메인을 생성해준다. 배포 유형은 실습이기 때문에 개발 및 테스트 유형을 선택해준다. 그리고 버전은 Elasticsearch와 Kibana의 환경을 실습하기 위해서 Elasticsearch 7.10 버전을 선택하도록 한다.
가용영역에 대한 설정은 가용성을 높여서 사용할 필요가 없기 때문에 1-AZ로 설정하고, 인스턴스 유형은 t3.small.search, 노드 수는 3, EBS/SSD/10GB로 선택을 한다. 또한 추가적으로 네트워크는 public access, Advanced cluster settings에서는 Max clause count의 값을 default로 1024로 설정해준다.
(Master user에 대해서도 IAM 옵션이 아닌 사용자 계정을 만들고, 접근 정책도 Only use fine-grained access control로 설정하도록 한다)
Elasticsearch
Elasticsearch의 장점인 JDBC나 ODBC 별도의 client library 상관없이 Kibana 자체적으로 제공하는 기능을 사용해서 web 상에서 직접 query를 보내서 API 테스트해 볼 수 있다.
인덱스 생성
데이터 베이스 생성과 같이 분산된 document를 쌓을 공간을 만드는 것을 말한다. (
앞에서는 쌓을 공간을 만드는 것을 index, 데이터를 ES에 넣는 행위를 indexing이라고 한다)[실습]
Kibana link를 통해 Elasticsearch에 들어가서 sample로 제공해주는 로그와 eCommerce 데이터를 선택해주면 생성한 Elasticsearch로 데이터를 밀어넣어준다. Dashboard 메뉴에서는 밀어넣은 데이터에 대한 dashboard 하위 메뉴가 생성이 되고, 클릭하면 미리 생성되어있는 dashboard graph를 볼 수 있다.
이러한 시각화 그래프는 Discovery에서 해당 그래프의 데이터가 json 형태로 쌓여있기 때문에 이 데이터를 기반으로 그래프를 그려준다.그리고 이 Discovery 메뉴에서는 column 이름을 기준으로 해서 데이터를 필터할 수도 있다.
추가적으로 그래프를 그릴때는Visualize메뉴를 통해 시각화하고자하는 데이터 dashboard를 선택해서 x-axis, y-axis를 선택해서 그리면 된다.
좌측 메뉴중에 Management 하위의 Dev Tool을 활용하면, query를 보내서 데이터를 검색할 수 있다.Index 생성
Index를 생성한다는 것은 앞서 배웠듯이 데이터를 검색하는 범위를 새롭게 생성한다는 의미이다.
개발자의 Kibana 활용
개발자들은 주로 Pi chart나 추세를 보여주는 라인 그래프를 주로 활용한다.
API 테스트
Dev Tools에서 RestAPI를 지원하기 때문에 다른 서비스와 연계시켜서 검색하는 서비스를 만들어낼 수 있다.
사용자 정의 인덱스 생성
Dev Tools에서 아래와 같이 인덱스를 생성 할 수 있다.
1
2
3PUT /my-index-1
PUT /my-index-2
PUT /my-index-3Stack Management / Index pattern / Create index pattern을 통해 새롭게 생성한 인덱스(
Document가 쌓이는 저장 공간)를 확인할 수 있다. 이 인덱스를 my-index*와 같은 패턴을 정의해서 생성할 수 있다
서비스별로 로그를 분류할때에도 위의 방법이 활용되는데, service-2022.07.01과 같이 날짜별로 인덱스를 만들어서 데이터를 쌓을 수 있다. 각 각의 날짜별로 분류된 서비스의 로그 데이터는service-*와 같은 특정 패턴으로 정의를 해서 생성을 할 수 있으며, 이렇게 정의된 패턴을 통해 Discover 메뉴에서 전체 서비스 로그에 대해 조건 검색을 할 수도 있다.
schemaless이기 때문에 좀 더 유연하게 데이터를 검색할 수 있다.Logstash / Flink —> ES
Flink나 Logstash를 활용해서 ES에 데이터를 넣어주면, 데이터가 계속해서 쌓이게 되고, 쌓인 데이터로 ES에서 데이터 분석을 하거나 시각화를 할 수 있다.
BI tool
Amazon Quicksight는 일종의 BI(Business Intelligence) 툴로서, Kibana보다는 좀 더 계산된 기능을 지원하고, 서버 분석을 해서 데이터를 긁어오는 서버와 UI가 합쳐진 형태를 BI툴이라고 한다.
BI 툴은 Data-Driven 형태로 비즈니스 관점에서 시간대별로 데이터를 보여주고, 다양한 관점의 자료를 시각화하여 더 나은 비즈니스 의사 결정을 내릴 수 있도록 도와주는 tool이다.
Kibana는 BI 툴이라고 하지 않으며, 단지 데이터를 시각화해주는 기능적인 면에서는 비슷하다고 볼 수 있다. 대표적인 BI 솔루션으로는 Tableau, MS Power BI, MicroStrategy, Redash 등이 있다.
Kibana를 들어가보면, Opensearch에서 샘플로 제공해주는 데이터들을 넣어서 dashboard를 생성해볼 수 있다.
사용예로는 보고서, 온라인 분석 처리, 데이터 마이닝, 시각화등에 사용되며, SQL, Hadoop, Hive를 통해서 SQL로 쿼리를 해보는 것과 달리 쉽게 UI상에서의 조작을 통해 데이터를 손쉽게 분석할 수 있게 도와준다.
Ref. Data mining : 통계적으로 전처리를 하여 데이터 간의 아직 알려지지 않은 관련성이나 경향 등을 분석하는 방법이다. 서로다른 데이터 소스의 데이터를 결합해서 새로운 경향을 도출해내는 방법으로 이해할 수 있다.
Amazon Quicksight
Cloud native serverless BI 서비스이다.
데이터를 기반으로 시각화 dashboard를 생성하고 공유할 수 있다. (AWS 계정 불필요)
별도의 인프라 관리 없이 S3에 있는 페타바이트 규모의 데이터에 쿼리를 하고 시각화 할 수 있다.
다양한 데이터 소스(AWS/Third party cloud/On-premise 데이터)를 연결할 수 있다.
AWS 계정없이 사용할 수 있기 때문에 데이터 분석/시각화를 하는 타 부서에서 별도의 서비스로써 활용을 할 수 있다.
SPICE(Super-fast, Parallel, In-memory, Calculation, Engine)을 이용한 캐시로 조회 성능이 향상 되었다.
ML Insight 자체를 제공하기 때문에 ML 기반의 이상 탐지와 ML 기반의 예측을 할 수도 있다. 또한 자동 서술 기능으로 dashboard의 결과를 텍스트로 작성해준다고 한다.
Amazon SageMaker 통합을 통해서 복잡한 데이터 파이프라인 없이 ML 모델을 통합할 수 있다.
다양한 암호화 기능을 제공한다.(다양한 데이터 표준에 대한 Compliance / HIPAA, HITRUST CSF, GDPR, SOC, PCI, ISO 27001, FedRAMP(High))
다양한 데이터 소스 제공
Quicksight에서는 아래의 다양한 서비스로부터 데이터 소스를 받아서 활용을 할 수도 있다.
- File
- S3
- Athena
- Redshift
- RDS
- Aurora
- MySQL
- PostgreSQL
- ORACLE
- Salesforce
- Presto
- Snowflake
5주차 수업 후기
이번 5주차 수업에서는 Flink에 대한 실습과 Elasticsearch의 운용과 관리에 대한 내용을 포함한 전반적인 내용들에 대해서 학습을 하였다. 사실 이전에 온라인 강의로 데이터 파이프라인 구축에 대한 수업을 들었을때에는 각 각의 비슷 비슷한 기능을 하는 구성요소가 왜 존재를 하는지, 그리고 단순히 AWS OpenSearch 서비스를 띄워서 Elasticsearch의 기능을 사용만 했었기 때문에 만약에 ElasticSearch를 별도의 서버에 구축해서 운영 및 관리를 할때에는 어떤식으로 해야되는지에 대해서는 전혀 알지 못했었다. 그런데 이번 수업을 통해서 Elasticsearch 클러스터 내의 각 노드들은 어떤식으로 구성이 되는지 구체적으로 알 수 있었다.(내용에 대해 반복학습이 필요할 것 같다)
6주차 수업 내용
- Amazon QuickSight에 대한 이론 및 실습
- 마무리 통합 파이프라인 구축
- 기업사례에 대한 공유