
이번 포스팅에서는 네 번째 데이터 파이프라인 구축 오프라인 수업시간에서 배운 내용을 정리하려고 한다.
Kafka 실습환경 구축 및 Single consumer 실습
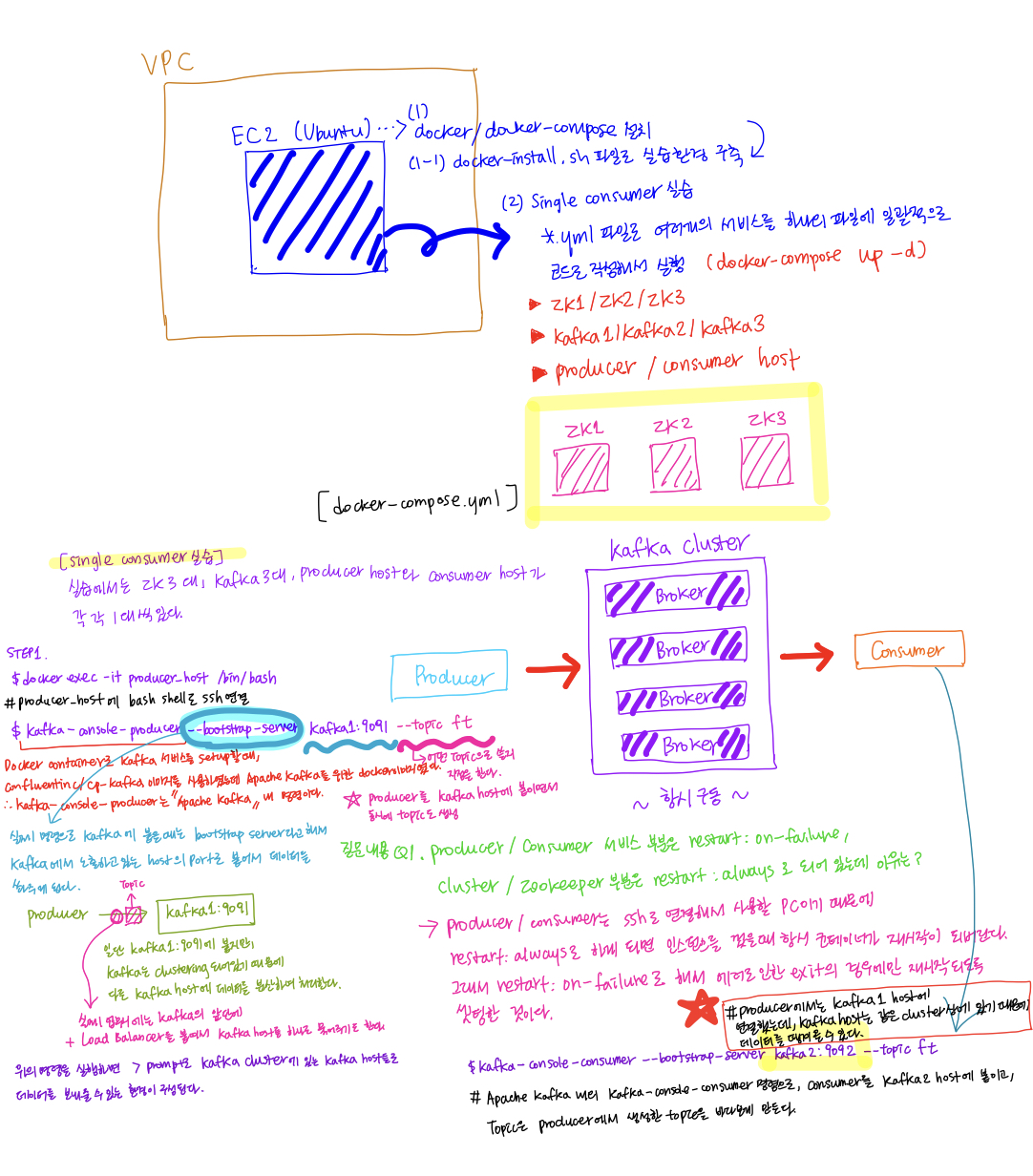
이전에 Kafka를 실습했을때는 생성한 EC2 인스턴스에 apache kafka 압축파일을 다운받고, 압축을 풀고, zookeeper와 kafka server를 시작하고, Topic을 partitions와 replication-factor 옵션의 값을 1로 생성하고 bootstrap-server 옵션은 localhost의 9092번 포트로해서 설정하였다. (kafka server: 9092, zookeeper: 2181) 이때 실습을 했을때는 세부 옵션에서 partitions이 뭔지 replication-factor가 뭔지 구체적으로 알지 못했었는데, 이제는 ISR 그룹이 뭔지 partition과 replication-factor이 뭔지 이해를 한 상태이기 때문에 좀 더 체계적으로 실습을 할 수 있는 것 같다.
그리고 이번 실습에서는 zookeeper와 kafka server를 하나의 터미널에서 명령어로 일일이 실행시키지 않고, zookeeper와 kafka host server, producer, consumer를 각각의 container로 구동을 시키기 때문에 구조적으로 좀 더 확장성 있는 것 같다. (docker image를 이용해서 컨테이너 서비스로 구동시키기 때문에 좀 더 빠르게 환경 구성을 할 수 있는 것 같다. 이래서 컨테이너로 서버를 띄우고 관리하는 것 같다.)
[실습전 Setting]
이번 docker-compose.yml 파일 안에 zk1zk3, kafka1kafka3, producer와 consumer에 대한 service를 미리 지정해서 docker image로부터 지정한 환경변수를 setting해서 구성하였다.
(Kafka와 Zookeeper는 각 각 3대이상 설치가 되어있어야 한다.)Q1. Producer와 Consumer 서비스 부분은
docker-compose.yml 파일을 보던 중 이 restart policy에 대해서 의문이 생겼었다. 이전에 docker에 대해서 학습을 했었기 때문에 어떤 역할을 하는지는 알았지만, 왜 두 개를 다르게 설정을 했지? 라는 궁금증이 생겨서 오프라인 수업때 강사님께 여쭤보았다. 어떻게 보면, 좀 이상할 수 있는 질문이긴 했지만, 모르니깐 배우는 거고, 질문하는 거라고 생각한다.restart: on-failure, cluster / zookeeper 부분은restart: always로 설정되어있는데 그 이유는?비싼 돈을 내고 듣는 수업이니 많이 배워야한다.A(Q1)
producer와 consumer는 ssh로 연결해서 사용할 PC의 개념이기 때문에 restart:always로 설정하게 되면, 인스턴스를 껐을때 항시 컨테이너가 재시작이 되버린다. 그래서restart: on-failure로 해서 에러로 인한 exit이 발생하였을 경우에만 재시작되도록 설정한 것이다. 그리고 Kafka cluster는 항시 구동이 된 상태에서 에러로 인해 중지가 되면, 다시 자동으로 구동시켜야되기 때문에restart: always정책으로 restart를 설정해줘야 한다.
이렇게 설명을 듣고 보니, 깔끔하게 이해가 되었다.
- ### **[Single consumer 실습]**
실습을 위한 환경 구성에 대해 준비가 끝나고 이제 Single consumer에 대한 실습을 하였다. 현재 실습 환경에 대해서 간단하게 살펴보면, ZK 3대, Kafka 3대, Producer와 Consumer host가 각 각 1대로 구성이 되어있다.
1
2
3
4
5
6
7
# producer_host에 bash shell로 ssh 연결
$docker exec -it producer_host /bin/bash
# docker container로 kafka 서비스를 setup할때, confluentinc/cp-kafka 이미지를 사용하였는데, Apache kafka를 위한 docker이미지이다.
# kafka-console-producer는 Apache Kafka 내 명령이다.
$kafka-console-producer --bootstrap-server kafka1:9091 --topic ft
# --bootstrap-server 옵션은 실제 명령으로 Kafka에 붙을때는 bootstrap server라고 해서, Kafka에서 노출하고 있는 host의 port로 붙어서 데이터를 쏴주게 된다.
# kafka host로 producer를 붙여줌과 동시에 topic을 생성해줄 수 있다.(--topic 옵션)
위에서는 producer에서 생성된 데이터를 ft topic에 전송하고, kafka1:9091에 전달해서 처리를 하고 있지만, kafka1 host는 클러스터 내의 host들 중에서 하나로 클러스터링 되어있기 때문에 다른 Kafka host들에 데이터를 분산하여 처리한다.
위의 명령을 하면, > prompt로 Kafka cluster에 있는 Kafka host들로 데이터를 쏴줄 수 있는 환경이 Setting된 것이다.
1
2
3
4
5
6
7
# 생성된 kafka topic의 리스트를 확인 (모든 kafka host에서 확인 가능)
$kafka-topics --bootstrap-server kafka1:9091 --list
#
$kafka-topics --bootstrap-server kafka1:9091 --topic ft --describe
# Topic: ft PartitionCount: 1 ReplicationFactor: 1 Configs:
# Topic: ft Partition: 0 Leader: 1 Replicas: 1 Isr: 1
위에서 Kafka cluster의 구성을 자세하게 살펴보기 위해 명령으로 확인을 할 수 있는데, 내용을 자세히 살펴보면 별도로 kafka-topic에 대해 `partition`이나 `replication-factor`을 설정하지 않았기 때문에 default로, PartitionCount: 1로, partition은 하나(partition 0), ReplicationFactor도 하나(리더만), replicas값이 1인 것은 리더만 1번째 브로커에 할당이 되었기 때문이다. (producer관점에서 acks=1과 동일한 결과(`프로듀서가 리더 파티션에 메시지를 전송하고, 리더로부터 ack를 기다린다. 단, 리더로부터 데이터를 복제해서 갖고 있는 팔로워들에게 까지의 전달은 확인하지 않는다`))그리고 마지막으로 Isr은 1개로, partition이 하나이기 때문에 ISR 그룹도 하나 존재한다.
파티션의 갯수는 브로커의 갯수만큼 나눠줘야 안정적으로 처리가 가능하다.
<br/>
그 다음으로 producer에서 topic을 통해 kafka cluster의 kafka host(broker)로 데이터를 전달을 하고, 전달한 데이터를 consumer에서 뽑아내기 위한 setting이 필요하다.
1
2
3
4
# Apache kafka 내의 kafka-console-consumer 명령으로, consumer를 kafka host에 붙인다.
# 여기서 producer에서 데이터를 쏠때 지정했던 kafka host와 다른 host를 지정해도 데이터를 정상적으로 받아올 수 있다. 그 이유는 kafka host1, 2, 3이 클러스터링 되어있기 때문이다.
# topic은 producer에서 생성한 topic을 바라보게 만든다.
$kafka-console-consumer --bootstrap-server kafka2:9092 --topic ft
위의 구성이 끝나면 producer에서 전송한 텍스트 메시지를 consumer에서 받아서 화면에 출력하게 된다. 지금은 간단하게 consumer console 명령으로 붙여서 실습을 했지만, `Logstash나 Flink와 같은 오픈 소스 툴들을 양단에 붙여서 데이터 스트리밍 실시간 처리를 할 수 있다.`
- #### **[실무 팁]**
실제 업무시에는 Kafka의 앞단에 Load balancer를 붙여서 Kafka host를 하나로 묶어주기도 한다.
<br/>
[Multi consumer 실습]
이번 실습에서는 위의 Single consumer 실습과 전반적인 구성은 같지만, consumer_host가 2개 존재한다. 실습은 consumer_host를 각기 다른 consumer group으로 지정해서 데이터가 어떤식으로 받아오는지에 대해 자세히 살펴본다.
우선 topic을 커스텀해서 생성할 것이기 때문에 아래와 같이--replication-factor와--partitions옵션을 지정해서 커스텀해준다.partition이 하나인데, consumer가 2개이면, consumer 한 대는 놀기 때문에 파티션을 2개로 주는 것이 좋다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 이번 multi consumer 실습에서는 topic을 자동생성하지 않을 것이기 때문에 우선적으로 topic을 생성해준다.
# topic은 --replication-factor와 --partitions 옵션으로 각 각 2를 준다.
# replication-factor를 2를 주었기 때문에 리더 하나와 팔로우 하나로 ISR 그룹이 구성이 된다.
# 그리고 partition은 2개로 구성되도록 설정하고 생성한다.
$kafka-topics --bootstrap-server kafka1:9091 --replication-factor 2 --partitions 2 --topic st --create
$kafka-topics --bootstrap-server kafka1:9091 --list # 생성된 topic 리스트 확인
$kafka-topics --bootstrap-server kafka1:9091 --topic st --describe
# topic의 파티션은 위에서 지정해준 것 같이 총 2개 (partition 2, 3) 생성되었다.
# 그리고 t-0, t-1 각 각의 파티션 Leader는 2번째와 3번째 브로커에 각 각 할당이 되었고,
# 리더가 2번 브로커에 할당된 친구(t-0)는 Replicas 값이 2(리더가 2번 브로커), 3(팔로워가 3번 브로커)
# 리더가 3번 브로커에 할당된 친구(t-1)는 Replicas 값이 3(리더가 3번 브로커), 1(팔로워가 1번 브로커)에 배치었다.
# Isr 그룹은 리더와 팔로워가 배치된 브로커의 위치를 (리더, 팔로워)순으로 표기한 것이다.
Topic: st PartitionCount: 2 ReplicationFactor: 2 Configs:
Topic: st Partition: 0 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: st Partition: 1 Leader: 3 Replicas: 3,1 Isr: 3,1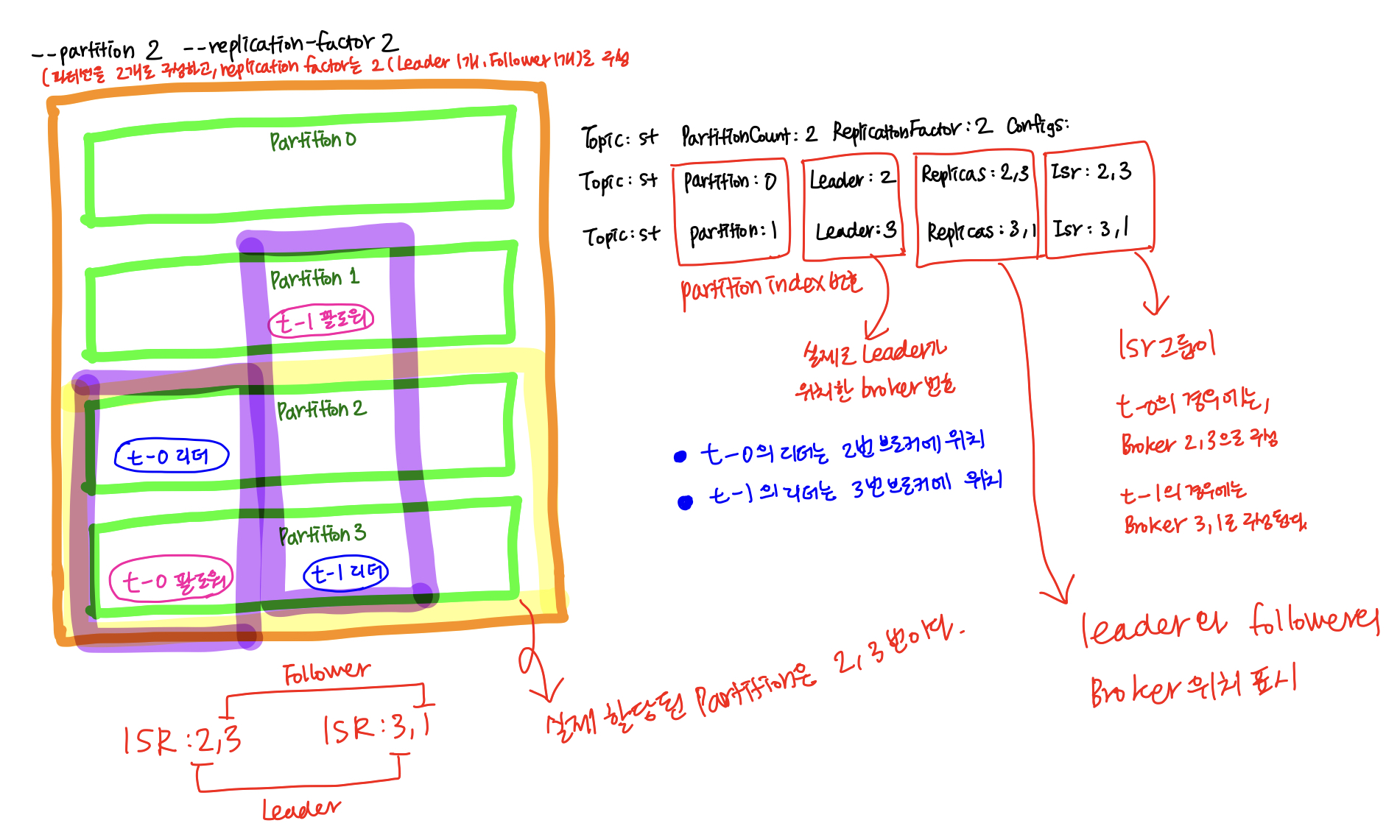
위와같이 하나의 파티션은 replication-factor의 수 만큼 복제되어 분산되어있는 것을 확인할 수 있다.
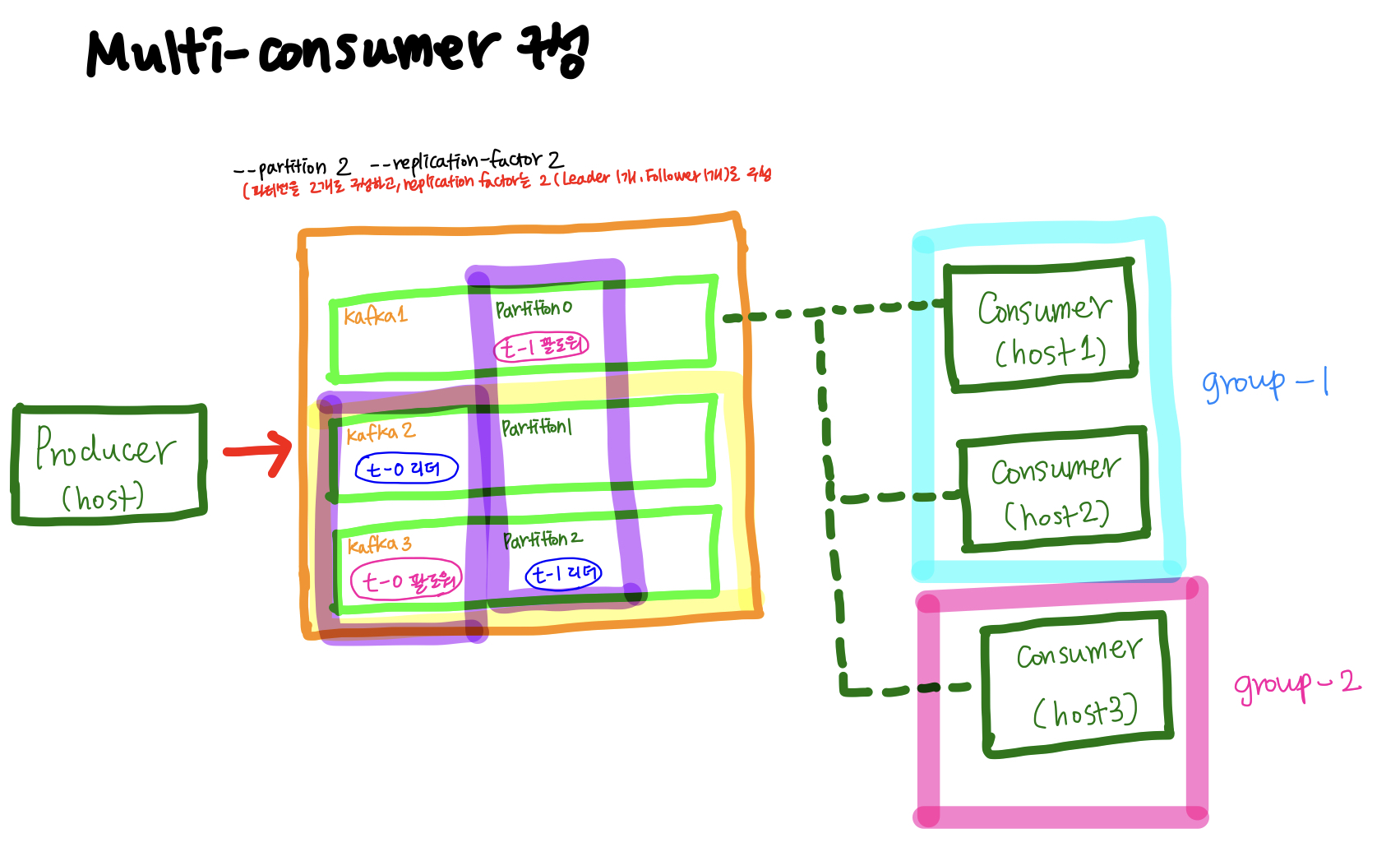
Consumer group은
group-1이름으로 두 개의 consumer_host를 묶어서 구성하고, group별로 offset을 달리해서 데이터를 뽑아내는 것을 확인하기 위해 별도의 consumer_host를 하나 더 생성해서 별도의group-2customer group을 생성하도록 한다.1
2
3
4
5
6
7
8$docker exec -it consumer_host1 /bin/bash
$kafka-console-consumer --bootstrap-server kafka1:9091 --topic st --group group-1
$docker exec -it consumer_host2 /bin/bash
$kafka-console-consumer --bootstrap-server kafka1:9091 --topic st --group group-1
$docker exec -it consumer_host3 /bin/bash
$kafka-console-consumer --bootstrap-server kafka1:9091 --topic st --group group-2기존 컨테이너 서비스가 유지된 상태에서 새로운 컨테이너 서비스 추가하기
원래 이전 docker-compose.yml에는 consumer_host3가 없었는데, 추가하려고 한다. 현재 docker container 서비스들이 실행되는 것은 유지된 상태에서 변경된 docker container를 추가해서 적용하려고 하는데, 어떻게 해야할까?
1
2
3$docker-compose up --build --force-recreate -d
# --build : 컨테이너를 시작하기 전에 이미지를 빌드한다.
# --force-recreate : 컨테이널르 재생성한다. docker-compose up을 하면, 변경된 사항을 적용하여 컨테이너를 재생성하지만, up을 했을때에도 변경이 적용이 안되는 경우, 이 옵션을 적용시킨다.우선 docker-compose.yml 파일을 수정하고, 위의 명령을 하면, 아래와 같이 새롭게 추가된 consumer_host3가 새롭게 생성되는 것을 확인할 수 있다.

새롭게 consumer_host3을 추가해서 group-2의 consumer_host로 배정했다.
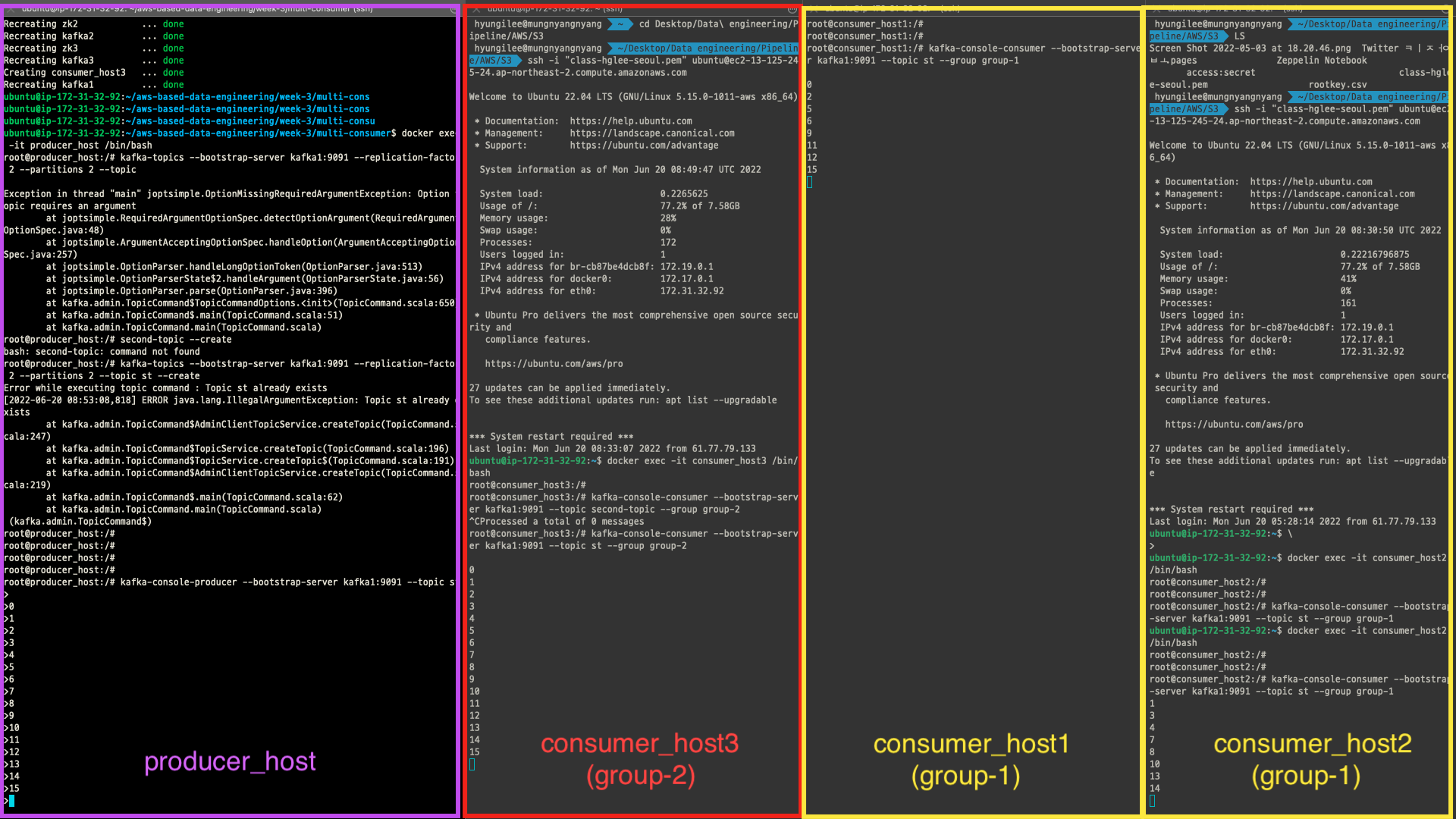
실습한 결과, 같은 group 내의 consumer_host는 producer로부터 전송되는 메시지 데이터를 분산해서 처리하고 있음을 알 수 있었고, 새롭게 추가한 group-2의 consumer_host는 단일 호스트이기 때문에 producer로부터 전송되는 데이터가 전부 단일 호스트로 들어오고 있음을 확인할 수 있었다.
[Q&A(1)]
partition이 2개인 상태에서 consumer를 한 개 더 늘려서 총 3대가 되면, consumer에서 나눠서 처리하는가에 대한 질문이 있었는데, partition이 2개이기 때문에 consumer host 2대에서 나눠갖고 한 대는 놀게 되는 구조가 된다.
따라서 partition의 수가 충분하다면 consumer를 늘려서 나눠갖는 것이 좋다.[Q&A(2)]
순서를 보장해야되는 특별한 경우에는 단일 broker 내에서는 순서가 보장이 되기 때문에 partition을 하나로 사용하는 경우도 있다. 하지만 데이터의 처리상의 안전성을 위해서는 기본적으로 partition 2개 이상을 사용하는 것이 좋다.
(실무 팁)
Broker를 두면 좋은 이유는 A부서가 기존에 Broker로부터 데이터를 받아서 전처리를 하고 있었는데, 신규 사업때문에 B부서가 생겨난 경우, 새롭게 데이터를 받아올 필요가 있을때 이 Broker에 Consumer_host를 붙여서 새로운 데이터셋을 받아오면 되기 때문에 매우 유용하다.
그리고 A부서에서 broker에 물리고 있는 consumer group의 consumer_host가 producer로부터 오는 데이터를 감당할 수 없다면, partition과 consumer_host를 늘려서 빠르게 병렬처리해서 처리하도록 하면 된다. 단, Kafka에서는 partition을 늘릴 수는 있어도 줄일 수는 없다. 따라서 partition을 늘리는 경우에는 신중하게 생각하고 늘리도록 해야한다. Partition을 늘리는 경우는 브로커 한 대에서 얼마나 처리할 수 있는가에 대한 고려가 필요하다.
MSK를 사용하면 통계된 데이터가 나오는데, 통계된 데이터를 기반으로 의사결정을 하면 된다.
만약에 데이터를 기존 consumer에서 처리를 못하는 경우에 우선 partition을 늘리고, consumer를 늘리도록 하는 것이 맞다. 그리고 좀 드문 경우인데 producer가 생성하는 데이터의 양 만큼 Partition을 늘리는 경우이다. (현재 producer로부터 오는 데이터를 Partition(Broker)에서 견디지 못하는 경우)
Amazon Kinesis
Amazon에서 만든 Kafka와 비슷한 서비스이다. Amazon kinesis 서비스는 내부적으로 Amazon Kinesis Data Analytics, Amazon Kinesis Data Streams, Amazon Kinesis Firehose, video stream이 있다.
카프카를 대체할 수 있으며, 저지연 스트리밍을 위한 서비스이다. EC2, Client, Agent, 사용자가 개발한 코드에서 생산된 데이터를 받고, 이를 다른 서비스에서 소비할 수 있도록 처리해준다.
Kafka의 Partition과 같은 것이 Kinesis의 shard이다. 그리고 Data retention은 24시간에서 1년까지 가능하고, 데이터 보존기간이 길어질수록 가격이 비싸진다.
Kafka는 partition을 늘리면 다시 줄일 수 없지만, Kinesis는 reshard가 가능하다.(split & merge)
- Data Stream: 데이터 스트림을 캡처, 처리 및 저장(
Kafka와 대응) - Data Firehose: 데이터 스트림을 AWS 데이터 스토어로 저장(
S3, Redshift에 저장, Fluentd, Logstash와 대체가능) - Data Analytics: SQL 또는 Apache Flink로 데이터 스트림 분석
- Video Stream: 비디오 스트림을 캡처, 처리 및 저장
실시간으로 비디오 및 데이터 스트림을 손쉽게 수집, 처리 및 분석할 수 있는 완전 관리형 서비스이다. (별도로 spec에 대한 설정이 필요가 없다)
구조
(STEP1) Input (Producer와 동일 레벨) Kinesis producer SDK, Kinesis producer Library(KPL), Kinesis agent
(STEP2)Amazon Kinesis Data Streams
(STEP3) Amazon Kinesis Data Analytics, Spark on EMR, Amazon EC2, AWS LambdaOutput- (Consumer와 동일 레벨) Kinesis consumer SDK, Kinesis Client Library(KCL), Kinesis Connector Library,Third party(Spark, Flume, Kafka connect, Flink), Kinesis Firehose, AWS Lambda 등으로 전달을 할 수 있으며, Kinesis Data Stream으로부터 받은 데이터를 AWS Lambda에서 특정 시간 주기로 함수를 실행시켜서 데이터가 처리될 수 있게 할 수 있다.
(STEP4) 최종적으로 BI툴을 활용해서 consumer로부터 받은 데이터를 시각화시켜서 처리할 수 있다.Amazon Kinesis Data Firehose
Data Firehose를 사용해서 데이터를 transformation하는 것이 가능하다. (Format conversion(Parquet, ORC), Encryption)
만약에 데이터를 custom하고자 할때는 Lambda를 붙여서 DataStream으로부터 넘어온 데이터를 Lambda로 밀어넣고 처리된 데이터를 Data Firehose로 넘겨주도록 처리하면 된다.Amazon Kinesis Data Analytics
input과 output 사이에 붙여서 SQL과 Flink를 붙일 수 있도록 해주는 Amazon의 서비스이다.
(Input -> Amazon Kinesis Data Streams ->Amazon Kinesis Data Analytics-> Amazon Lambda -> Amazon DynamoDB -> Output의 구성과 같이 Data Stream으로부터 들어온 데이터를 Data Analytics로 붙여서 실시간으로 들어온 데이터를 분석할 수 있다)
실시간으로 데이터를 처리하기 때문에 대용량의 로그 데이터를 처리(분석)하는데 매우 빠른 시간내에 처리할 수 있으며, 문제를 실시간으로 발견 및 대응을 할 수 있기 때문에 고가용성은 물론 우수한 고객 경험을 줄 수 있다. (Netflix 사용 사례)
Amazon Kinesis 실습
실습 구조
STEP1. Amazon Kinesis Data Generator (
랜덤 로그 데이터 생성)
STEP2. Kinesis Data Stream
STEP3. Kinesis Firehose
STEP4. S3CloudFormation
CloudFormation을 활용하면 Data Generator환경을 생성할 수 있다.그리고 IaC(Infrastructure as Code)의 일환이다.
CloudFormation으로 랜덤한 로그 데이터를 생성하는 producer를 구성하기 위해서는 Template이 필요하다.Amazon Congnito
Amazon Cognito는 웹 및 모바일 앱을 위한 Authentication, User management의 기능을 제공한다. 사용자는 thrid party 웹 페이지를 통하거나 직접적으로 사용자 이름과 비밀번호를 입력해서 로그인을 할 수 있다.
cognito는 user pools과 identity pools 두 가지 메인 컴포넌트가 있다. user pools는 사용자 디렉토리로, 앱에서의 회원가입과 로그인에 대한 옵션을 사용자에게 제공한다.
identity pools는 다른 AWS 서비스들에 접근하는 권한을 사용자들에게 부여할 수 있도록 허용을 해주며, user pools와 identity pools를 같이 혹은 나눠서 사용할 수 있다.
실습을 위해 주어진 congnito-setup.json의 내용을 보니, 해당 json파일은 인증된 사용자에게 cognito의 identity pool에서의 역할을 할당하고, 사용자가 Kinesis Data Generator tool을 사용할 수 있도록 해주는 설정들이 담겨져있는 파일이다. (
+Lambda 함수와 Cognito를 붙여주는 작업)
해당 파일을 template으로써 지정해서 stack을 생성하면 된다.생성을 해주게 되면, Output 탭에서 링크가 생성된 것을 볼 수 있는데,
template으로부터 생성된 Kinesis Data Generator tools를 사용할 수 있는 링크이다.이제 username과 password를 입력해서 들어가면, UI상으로 Region, Stream/Delivery stream을 선택해서 생성된 랜덤한 로그 데이터를 쏴줄 수 있다.
Kinesis stream 서비스 생성
이제 Kinesis Data Generator를 통해 생성된 랜덤 sensor 데이털르 쏴 줄 target인 Kinesis data streams와 Kinesis data firehose 생성을 한다.
Kinesis streams
샤드 계산기를 통해서 적정 샤드의 수를 계산해서 프로비저닝된 샤드의 갯수를 설정하고 Kinesis streams를 생성해주면 된다. (
기본 데이터 retention 시간은 24시간이다)Kinesis delivery stream
source는 생성한 data streams으로 하고, destination은 S3를 선택하고 생성해주면 된다. 추가적으로 firehose에서는 생성한 lambda function을 붙여서 데이터를 transformation할 수 있다. 이외에 옵션으로 버퍼 사이즈나 버퍼 인터벌 시간을 조절 할 수 있는데, 버퍼 인터벌 사이즈를 줄여서 반응시간을 빠르게 할 수 있다.
Kappa Architecture : The concentration in stream processing(스트림 프로세싱 심화)
Kappa Architecture에서는 배치와 스트림 프로세스를 모두 실시간으로
처리된다. (Lambda Architecture에서 배치 레이어가 없어진 형태 - 파이프라인의 구조 단순화)
현대에 와서는 컴퓨터 리소스와 컴퓨팅 기술, 스트림처리 엔진에 대한 기술의 발달로 모든 처리(배치, 스트림 프로세스)를 실시간 스트림으로 처리하는 것이 가능해졌다.
이에 따라 개발/운영 이중화에 대한 부하가 줄어들게 되고, 이는 Kafka를 개발한 Jay Kreps에 의해 제안되었다.
디즈니(Disney)
디즈니라고 하면 애니메이션만 만드는 회사라고만 알고 있었는데, 데이터를 많이 사용해서 앞서나가는 아키텍처를 구축하고 있는 기업이라고 한다.
수업에서는 Lambda Architecture에 대한 Disney의 생각이라는 section으로 설명을 해주셨는데, 아래와 같이 디즈니에서는 Lambda Architecture에 대한 생각을 가지고 있다고 한다.
Duplicate Code
Deplicated code, Lambda Architecture는 구조상 보면, 스트림 처리와 배치 처리하는 구간이 나눠져 있기 때문에
서로 다른 두 코드에 대한 관리를 위한 개발팀과 유닛 테스트가 필요하다. 따라서 처리상 하나만 바뀌어도 모두 전파해야하고, 릴리즈 또한 연동이 되어야한다.Data Quality
Batch와 Speed layer 간의 알고리즘이 일치하는지에 대한 확인과 입증이 필요하다.
Added Complexity
추가적인 복잡도에 대한 고려가 필요하다. 두 파이프라인에서의 데이터 중 어떤 데이터를 언제 읽을지에 대해 고려해야되며, 배치 잡의 딜레이되는 경우에 대해서도 고려해야한다.
Two Distributed System
하나의 데이터 처리에 대해서 두 개의 파이프라인으로 나뉘어서 같은 데이터에 대해 처리하므로, 두 배의 인프라를 구성해야 하고, 모니터링과 로깅도 각 각 나눠서 해야되기 때문에 2배의 리소스가 든다.
Single pipeline for streaming and batch consumer
유입되는 Data resource가 단일 Real-Time Layer을 통해 좀 더 민첩하게 처리해야 할 데이터는 ms 단위로 처리하고, 덜 민첩하게 처리해도 되는 데이터에 대해서는 Real-Time Layer를 통해 들어온 데이터를 담고 있는 Storage를 통해 min/hr 단위로 배치처리를 하게 된다.
스트림 프로세싱의 심화
여지까지 Kafka와 Kinesis를 이용해서 데이터를 전달하고 적재하는 부분까지는 했고, Lambda나 Kinesis Firehose에서 정형화된 데이터의 transformation을 경험했다.
이번 시간에는 스트림 프로세싱에서
처리의 관점에서 데이터를 어떻게 transformation할 것인지에 대해 고도화시킬 수 있는 방법에 대해서 심도있게 다룬다. 오픈소스나 클라우드 서비스에서 제공되는 기능 이외에 커스텀해서 구성할 수 있는 방법들이 많기 때문에 이 부분에 대해서도 배우게 된다.
Apache Flink (stream engine)

분산 스트림 처리 프레임워크이며, Spark streaming와 대응된다. Spark streaming은 Flink와 비교했을때 성능면에서 많이 차이가 나지만, 국내에서 Spark 사용자들이 많기 때문에 Spark로 배치처리를 하다가 Streaming이 필요한 경우에 기존 기술셋을 사용해서 기존에 사용하던 언어를 사용하기 위해 Spark streaming을 도입한느 경우가 많다. 하지만 Flink가 기능이나 생태계를 보면, Spark보다 Flink가 더 스티리밍 데이터(
데이터의 제한이 없는 무한한 데이터) 처리에 최적화가 되어있다.Flink를 도입해서 사용하고 있는 기업은 Alibaba, Tencent, Uber, AWS, Lyft, SKT, Kakao, NAVER, Toss, Coupang, 하이퍼커넥트 등이 있다.
Flink는 Native streaming 방식(건 by 건으로 처리하는 방식-Performance 좋음)을 채택하고 있으며, micro batch 방식(작은 단위(5초, 1분 단위)로 배치처리를 함으로써 마치 실시간 스트리밍 처리를 하는 것과 같은 효과를 주는 방식)을 사용하고 있는 Spark와 대비된다.
그리고 Flink는 High Performance, low latency, exactly-once라는 특징을 가지고 있지만, 처리 속도는 빠르다는 장점을 가지고 있다. 그리고Flink는 Java(86%)와 Scala(10.1%), Python(2.4%)로 만들어진 프로젝트이다.
그리고 Flink에서 사용할 수 있는 언어로는 Java, Python, Scala로 개발을 할 수 있다.
[Apache Flink의 특징]
Flink를 사용해서 스트림 및 배치 처리를 둘 다 할 수 있다. (통합 데이터 처리 엔진)
High Performance(Native Stream, Low Latency, High Throughput)
-> Spark streaming처럼 micro/mini batch 구조가 아닌, 완전 스트림 최적화 방식을 사용하고 있다.Fault tolerance

-> Flink의 핵심인 Checkpoint를 통해 Exactly-once를 지원한다. Checkpoint는 분산 체크포인팅 및 분사 스냅샷 기술의 일종으로, 작업 중간 중간에 스냅샷을 찍어서 장애 발생시 스냅샷을 한 상태로 되돌릴 수 있다. 내부적으로는
Chandy-Lamport라는 알고리즘을 개선한 알고리즘이 적용되어있다고 한다.(나중에 찾아서 읽어보기)
https://en.wikipedia.org/wiki/Chandy%E2%80%93Lamport_algorithmMessage guarantees로
Exactly-once를 지원한다.DataStream API, DataSet API(legacy), Table API를 지원하기 때문에 All rounder로 볼 수 있다.
Batch 처리를 위한 별도의 Batch runtime mode가 제공되기 때문에 배치 처리도 가능
env.setRuntimeMode(RuntimeExecutionMode.BATCH);
[참고]: https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/execution_mode/
[Flink의 구조]
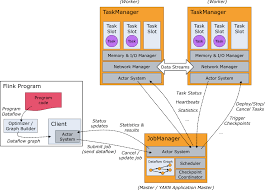
Flink Architecture는 크게 Job Manager는 Master 노드의 역할로, Task Manage(Worker)의 작업 스케줄링을 하는 역할과 Streaming 데이터의 각 구간에 Checkpointing을 하는 역할과 복구를 하는 역할을 한다.
Task Manager는 실제 일을 하는 Worker로, 분산된 Operator들은 TM로 분산 처리된다.
위의 구성도를 보면, Job Manager에서 Dataflow Graph를 통해 각 각의 Operator들의 순서도를 관리한다. Dataflow Graph의 각 각의 STEP의 작업을 TaskManager(Worker)에 분산을 시키게 된다.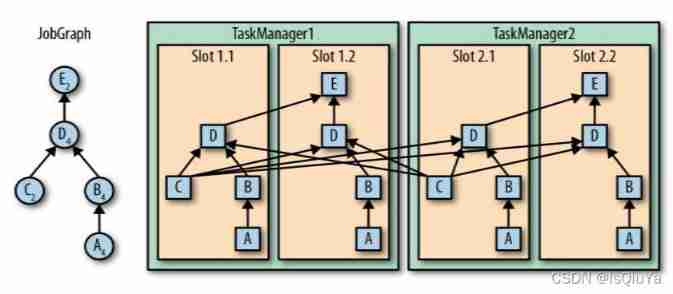
[Apache Flink의 활용]
Apache Flink는
단순 수집과 전달에서부터 합계, 평균 계산과 같은 집계와 패턴에 기반한 예측 분석 및 데이터 형식을 변환하고 다른 데이터 소스와 결합(join)등의 작업이 가능하다. 그리고 Flink는 streaming 엔진이지만 배치 처리가 가능하다는 장점을 가지고 있다. 또한 케이블 기능도 하기 때문에 데이터 베이스에서 하나의 테이블을 가져와서 스트리밍 데이터와 조인하는 기능도 제공한다.[경쟁 프로젝트]
앞서 살펴본 Spark streaming, Storm(
현재는 잘 사용되지 않음), Kafka streams, Samza(현재는 잘 사용되지 않음)[배포]
Flink는 주로 Standalone, Kubernetes(
YARN Resource에 배포하지 않고 Kubernetes에 배포해서 백엔드 개발자와 같은 인프라를 사용하는 경우도 많다), Hadoop YARN에 배포가 되어 사용이 된다. 그리고 Kubernetes는 Spark에서보다 더 잘 지원하고 있다.[내부 동작방식]
Flink를 사용해서 HDFS와 같은 FileSytem으로부터 데이터를 뒷단으로 넘겨서 처리를 할 수 있으며, Kafka로부터 스트림 데이터를 읽어서 처리를 하거나 주기적으로 JDBC와 같은 DB에서 데이터를 읽어서 처리를 할 수 있다.
그 외에도 Socket에서 실시간으로 데이터를 읽어와서 처리를 할 수 있다. (Source)
이렇게 Source로 받아온 데이터를 File의 형태로 출력, Elasticsearch로 데이터를 올리거나, HBase, 다시 또 다른 Kafka의 Topic으로 받아서 처리한 데이터를 쏴 줄 수 있다.[사용 예시]
신규 기술이 나오면, 기업에서는 바로 도입을 하지 않고, 다른 큰 기업에서 도입해서 안정성과 효율성에 대한 인정을 받았을때 도입을 한다.
이 Flink라는 기술도우버(Uber)에서 스트리밍 분석 플랫폼인 AthenaX에 Flink를 사용함으로써 알려졌고,알리바바(Alibaba)는 Flink를 기반으로 한 Blink를 개발하여, 자체 실시간 검색 숝위를 최적화하였다고 한다. 그리고 데이터가 폭증하면서 배치 처리와 스트림 처리 모두 Flink를 사용하고 있다고 한다.AWS의 스트림 프로세싱을 위한 완전 관리형 클라우드 서비스인 Kinesis Data Analytics도 내부적으로 Flink를 사용하고 있다고 한다.앞에서 이미 정리를 했지만, Flink는 단순 데이터 전달 및 저장만 하는 것이 아닌, 자체적으로 컴퓨팅을 통해 연산 및 분석 결과만 다른 곳으로 전달하는 역할도 가지고 있다.
(연산/분석을 통해 실시간 검색어 순위에 대한 정보도 출력할 수 있으며, ML 라이브러리를 통해 처리를 할 수도 있다)
[Flink에서의 Time]
Flink에서는 세 가지 유형의 시간개념으로 구분을 한다.
- Event Time : 데이터가 실제로 생성되는 시간 (Event producer)으로, 데이터가 실제로 생성되었을때를 말한다. (센서로부터 센서 데이터가 생성되었을때)
- Ingestion Time : 데이터가 Flink job으로 유입된 시간 (Flink Data)을 말한다.
- Processing Time : 데이터가 특정 operator에서 처리된 시간
이렇게 구분하는 이유는 Operator마다 시간기준으로 정확한 연산을 해야 할 필요성이 있기 때문이다.
[Flink의 Task & Operator chain]
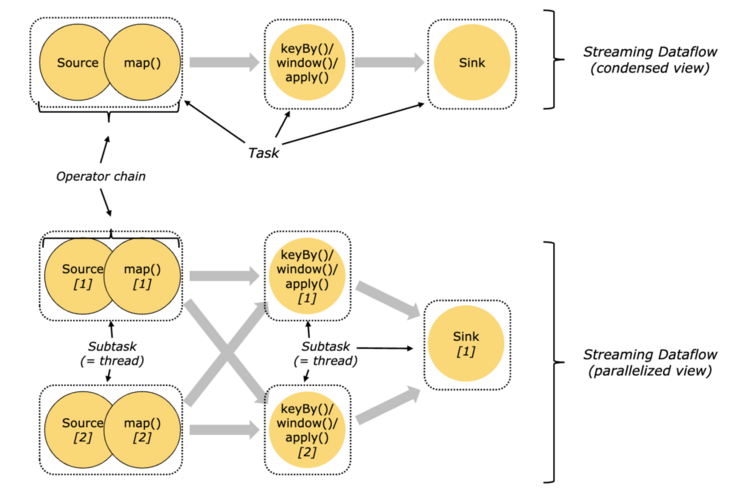
Flink에서 로직을 복잡하게 작성을 하다보면, 효율성을 위해서 연관된 각 처리과정을 Chaining하는 경우도 많다.
[Flink의 Sink Parallelism]
Task slot: 6,Sink parallelism: 1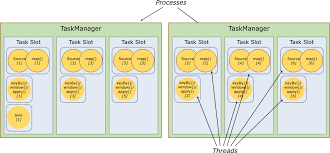
기본적으로 Flink는 다른 작업의 하위 작업인 경우에도 하위 작업이 슬롯을 공유할 수 있도록 허용한다. 결과적으로 하나의 slot은 전체 파이프라인의 job에 대해 저장을 할 수 있다.
Task slot은 정적인 개념으로, Task Manager 참조하여 동시 실행 기능을 가지고 있다.
Task Manager들의 내부의 Task slot이 각기다른 Thread로 구성이 되며, Task Manager들은 Job Manager에 의해 관리가 된다.
[Windows]
https://nightlies.apache.org/flink/flink-docs-master/docs/dev/datastream/operators/windows/
Flink에는 다양한 방식으로 데이터를 나눠서 처리하는 방법이 있는데, Windows란 개념으로 데이터를 잘라서 처리를 한다.
Windows를 사용해서 데이터를 분석하는 예로10초에 한 번 평균을 내야되는 연산을 하는 경우나사용자가 접속한 순간부터 나간 순간까지의 이벤트를 모아서 한 번에 처리하는 경우가 있다.여기서 윈도우란 Spark streaming의 micro batch의 개념과 다르다. 5초 단위로 들어오는 데이터들을 처리해야될 경우에 Window size를 5초 단위로 나눠서 처리를 할 수 있으며(
Tumbling Windows), 각 각의 Window의 구간이 겹쳐서(데이터가 중복) 처리하는 것은Sliding Windows, 정확히 시간을 기준으로 구간을 나누기 애매한 경우(사용자의 접속부터 종료 시점까지의 이벤트 일괄처리)에는 각 session별로 데이터 구간을 나눠서 처리하는Session Windows의 개념으로 데이터를 잘라서 처리한다.
만약에 특정 시간 구분 없이 전체 데이터를 처리하는 경우는Global Windows개념으로 데이터를 일괄 처리하도록 한다.Flink에서는 Tumbling Windows, Sliding Windows, Session Windows 이 세가지를 지원한다.
ex) 실제 사용자가 들어와서 세션내에서 어떤 작업을 했는지 취합하고 검색을 할때 주로 Session Window를 사용한다.
Dataflow Programming
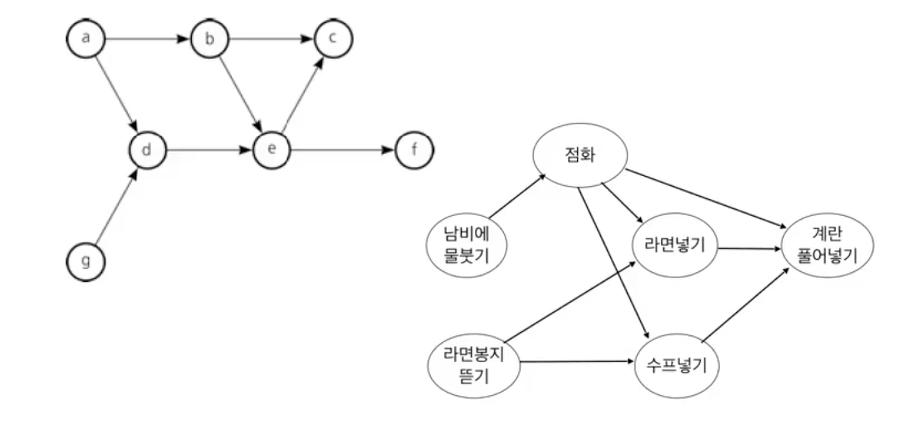
스트림 프레임워크 엔진을 개발할때 중요하게 보는 것이 Dataflow Programming이다.
DAG(Directed Acyclic Graphs):유향 비순환 그래프(방향성은 있는데 순환하지 않는 형태), Airflow에서도 많이 접하게 되는 개념
각 각의 데이터 플로우 그래프를 만들어서 서로 연결시켜서 하나의 그래프로 만들어주는 것이
Dataflow Programming이다.[Dataflow Programming의 세 가지 Operator]
- Source Operator : 그래프 상에서 제일 처음인 부분, Kafka와 같이 외부에서 데이터를 받아오는 부분 (입력이 없는 연산자 - root node (
a operator))- Custom source
- Apache Kafka
- AWS Kinesis Streams
- RabbitMQ
- Twitter Stream API
- Google PubSub
- Collections
- Files
- Sockets
- Transformation Operator : 변환/연산 등의 연산자 (
b, d operator)- Map : 사용자가 정의한 변환 코드를 통과시켜서 하나의 이벤트를 출력
- FlatMap : map과 유사하지만 각 요소에 대해 0개 이상의 출력을 생성하는 것이 가능하다. (문자열을 split해서 처리 여러 요소로 나눠서 처리)
- Filter : 특정 조건에 따라 pass or drop하는 필터 기능
- KeyBy : 특정 옵션(키)에 따라 스트림을 파티션별로 분리
- Union : 두 개 이상의 동일한 타입의 스트림을 병합
- Reduce : 키별로 나뉘어진 데이터 스트림을 합쳐주는 역할
- Sink Operator : 그래프상에서 제일 마지막 출력부 (leaf node -
c, f operator)- Custom sink
- Elasticsearch
- Kafka producer
- Cassandra
- AWS Kinesis Streams
- File
- Socket
- Standard output
- Redis
- Source Operator : 그래프 상에서 제일 처음인 부분, Kafka와 같이 외부에서 데이터를 받아오는 부분 (입력이 없는 연산자 - root node (
실제 프로그래밍을 할때에는 Source operator 부분을 개발한다. 예를들어 Kafka를 활용해서 데이터를 입력받는 부분을 우선적으로 만들고(프레임워크에서 제공), Kafka에서 들어온 데이터를 transform해주는 Transformation operator를 만든다. 그리고 최종적으로 변환된 데이터를 다른 저장소나 목적지로 쏴주는 Sink operator를 만들어서 연결시켜준다.
이와 같은 일련의 과정을 DAG라고 하며, Flink 어플리케이션에서는 이러한 일련의 과정을 만드는 것이다.ETL과 비슷한 과정
Flink는 분산 스트리밍 엔진이기 때문에
source -> map -> key By()/Window()/Apply()구조의 각 STEP을 여러 노드로 분산해서 처리를 할 수 있도록 할 수 있다.1
2
3
4
5
6
7
8
9
10
11
12// Input Source
DataStream<String> lines = env.addSource(new FlinkKafkaConsumer<>());
// Transformation
DataStream<Log> logs = lines.map((line) -> parse(line));
// Transformation
DataStream<Statistics> stats = logs.keyBy("id")
.timeWindow(Time.second(10))
.apply(new MyWindowAggregationFunc());
// Output Sink
stats.addSink(new CustomSink(path))예를들어 Kafka에서 1, 2, 3, 4라는 숫자 데이터를 받아오면, Flink 클러스터의 노드가 2개 있다고 가정을 했을때, 받아온 데이터 중에서 1, 2를 A라는 노드에서, 3, 4를 B라는 노드에서 처리하도록 분배할 수 있다.
이렇게 분배된 데이터들은, map()을 통해 제곱된 수로 변환이 되고, 홀/짝수로 분류를 하는 일종의 MapReduce와 같은 과정을 거쳐서 홀수로 분류된 데이터는 또 다시 Sink를 통해 또 다른 Kafka의 odd topic으로 날리고, 짝수로 분류된 데이터는 even topic으로 날리도록 처리를 할 수 있다.
Flink와 Logstash를 비교해보면, Logstash는 각 각의 Logstash에서의 작업을 하지만 다른 Logstash 간에는 소통을 할 수 없다. 하지만 Flink는 하나의 클러스터 이기 때문에 각 각의 처리 노드들끼리 서로 소통을 할 수 있다.
(실무팁)
Kafka의 Partition이 3개 있고, consumer가 4개 있는 상황에서는 consumer 하나가 잉여가 된다. 만약에 Flink로 어플리케이션을 만든 다음에 복잡한 데이터를 처리할때에는 source node가 10대 이상이 되어야 되기 때문에 이 경우에 consumer를 10대 이상으로 늘려주게 되면, 실제로는 Partition이 3개이기때문에 consumer 3개에서만 데이터를 받아서 처리를 해주게 된다.
이 경우에는 Flink가 클러스터링 되어있기 때문에 데이터를 받지 못하는 나머지 consumer에게도 실제 데이터를 받아오는 consumer로부터 분배받을 수 있도록 구성할 수 있다. (Kafka 자체에서는 데이터를 나눠줄 수 없는 consumer이지만, Flink 내부의 operator가 consumer들에게 데이터를 분배할 수 있도록 해줄 수 있다)
(수업내용 외 질문)Q1. VPC와 Subnet 구성에 대한 질문
내가 수업시간에 한 질문은 다른 AWS service topology를 살펴보면, VPC와 Subnet으로 구분된 것들이 많은데, 실제 실무에서는 어떤식으로 사용되고 있나였다.
A : 실습에서는 default vpc와 subnet에서 AWS resource가 생성이 되는데, 실무에서 default vpc와 subnet을 사용하지 않는 것이 권장된다고 한다. 실제 업무에서는 Production에서 각 각의 서비스별로나 네트워크 보안 정책에 따라서 VPC를 나눠서 관리를 하고, 세팅을 하는 것이 옳은 방법이라고 한다.
AWS 서비스 중에서 완전 관리형 서비스가 아닌 서비스들은 VPC을 타지만, 완전 관리형 서비스의 경우에는 VPC가 아닌 별도의 AWS Zone(AWS전용 네트워크 라인)을 탄다.