
이번 포스팅에서는 세 번째 데이터 파이프라인 구축 오프라인 수업시간에서 배운 내용을 정리하려고 한다. 참고로 첫 번째와 두 번째 수업때도 너무 유익한 내용들이 많았는데, 이번 시간이 정말 너무 유익하고 좋았다.
아마도 이전에 인터넷 강의로 수강을 했을 때 아쉬웠던 부분이 많았는데, 이번에 개별적으로 현직자 분께 오프라인으로 직접 수업을 들으니, 궁금했던 부분이 많이 해소되기도 했고, 강사님이 수업에 필요한 여러 자료나 실제 회사에서 업무했을 때 필요한 부분에 대해 설명을 잘 해주셔서 그런 것 같다.
이번 3주차 수업에서는 수업 한 시간 전에 미리 강의장에 도착해서 어떤 식으로 데이터 엔지니어 포트폴리오의 프로젝트를 구성해야되는지 과거에는 K사에서 근무하셨고, 현재는 N사에서 데이터 엔지니어로 근무하시는 강사님께 조언을 구했는데, 너무 감사하게도 세세하게 답변을 해주셔서 이 부분에 대해서도 한 번 정리를 해보려고 한다.
포트폴리오 프로젝트 준비
이번 3주차 수업 시작전에 강사님께 미리 데이터 엔지니어 포트폴리오는 어떤 식으로 준비를 해야되는지 여쭤보았다. 내가 이전에 생각했던 것은 FE/BE는 하나의 프로젝트당 하나의 코드로 깃허브 Repository에 정리를 하면 되는데, 데이터 엔지니어는 AWS와 같은 클라우드 서비스를 이용해서 데이터 파이프라인을 구축하고, 내부적으로 일부 코드를 작성하기 때문에 문서 형태로 정리를 하면 되는 것인가? 라는 생각을 했었다.
그런데 강사님이 "데이터 엔지니어도 FE/BE 프로젝트와 다를 것이 없고, 단지 데이터 엔지니어를 위한 프로젝트는 FE/BE처럼 하나의 코드로는 나오지 않을 것이다."라는 답변을 해주셨다.
덫붙여서 1주차 강의때 더 알면 좋은 내용들 중에 IaC(Infrastructure as Code)로 인프라구축을 코드로 작성해서, 프로젝트를 구성하고 있는 인프라를 손 쉽게 구축할 수 있게 하는 부분을 해보고, 해당 코드를 프로젝트에 넣으면 좋을 것 같다는 말씀도 해주셨다.
아마 FE/BE 사이드 프로젝트와 별반 다르지 않다는 말씀이 이런 코드들을 GitHub 레포지토리에 정리해서 올리고, 데이터를 정제할때나 Event Driven Architecture로 구성했을때 작성했던 코드들도 GitHub에 프로젝트 단위로 묶어서 올리면 되기 때문에 그렇게 말씀해주신 것 같다.(Markdown으로 문서화는 필수)
IaC로 인프라 구축을 코드로 작성했을 때, Terraform에 대해 언급을 해주셨는데, 이전에 Vagrant로 스크립트를 작성해서 VM의 구성을 손쉽게 하는 것을 해보았는데, 이것과 같은 맥락인 것 같았다. (찾아보니, Vagrant와 Terraform은 둘 다 HashiCorp에서 파생된 프로젝트라고 한다. Vagrant는 개발 환경을 관리하는데 주안점을 둔 툴이고, Terraform은 인프라를 구축하는데 주안점을 둔 툴이라는 차이가 있다.)
AWS로 구축한 인프라는 HCL(Haship Configuration Language, *.tf)으로 작성해서 GitHub에 코드를 올리도록 하자.
실제 업무를 할때나 사이드 프로젝트를 할때에도 우아하게 파이프라인을 구축할 필요 없이 Lambda와 triggering하는 요소들을 잘 조합해도 효과적으로 공수를 덜 들이고 인프라를 구축할 수 있다.
간단한 처리는 Lambda와 EventBridge만을 사용해서 처리를 할 수 있다.
Athena의 사용
Athena 엔진(Version2)은 Presto(0.217)라는 오픈소스를 기반으로 만들어졌다. 관련된 함수, 연산자, 표현식에 대한 자세한 내용은 Presto documentation에서 확인할 수 있다.(Kakao )
Athena는 Presto 및 Trino의 함수와 기능의 전부는 아니지만, 일부 지원을 한다. 최근에는 Presto에서 Trino로 바뀌었다.
Athena를 사용할때 직접 Athena에 접속을 해서 브라우저에서 쿼리를 날리거나 하는 작업을 하기도 하지만, 현업에서는 파이프라인을 구축할때, Athena를 원격지의 데이터베이스 개념으로 다뤄서 쿼리를 보내는 형태로 작업을 한다.(한번 감싼 형태로 Athena를 활용)
이전에 BI툴인 Tableau에서 Amazon Athena의 데이터와 연결해서 실습해본적이 있는데, 이렇게 사용한다는 의미인 것 같다. (Tableau에서 Athena JDBC 드라이버를 설치해서 사용, 자동화시에 사용)
Presto와 Trino는 파일들을 Parsing해서 테이블의 스키마를 생성해서 데이터를 조회한다거나 하는 작업을 가능하게 해주는 엔진이다.
Output이 여러개 파일로 나오는 것을 하나의 파일로 통합
이전 실습을 할때 CTAS query의 결과로 S3에 저장된 데이터가 여러개로 생성(Athena가 Presto 엔진을 기반으로, 분산된 되서 처리를 해주기 때문에 여러개의 파일로 생성)이 되었었는데, 아래와 같이 bucketed_by=ARRAY['time'], bucket_count=1 time 필드를 기준으로 한 번 만 실행되도록 설정해서 CTAS 쿼리를 날려주면, 한 개의 파일로 추출이 된다.
1 | CREATE TABLE new_table2 WITH (external_location=‘s3://hg-data-bucket/ctas-bucketing/', |
PARQUET 데이터 포맷으로 하고, 압축방식은 SNAPPY로 한다.(SNAPPY 압축방식은 네트워크 통신비용을 줄이기 위해 많이 사용된다)
그리고 결과로 S3에 적재된 파일의 데이터가 제대로 들어갔는지 확인하려면 생성된 파일을 체크하고, [작업] - "S3 Select"를 사용한 쿼리를 선택해서 data type을 parquet로 변경하고 쿼리를 날려서 결과 데이터를 확인해볼 수 있다. (parquet 타입의 데이터의 경우에는 다운받아서 확인하려면 별도의 프로그램을 다운받아야 한다) 이렇게 하면 별도로 Athena로 연결해서 데이터를 확인하지 않아도 된다.
Hadoop, Spark를 Athena로 대체
ETL과정에서 Transform 과정에서 Hadoop이나 Spark를 사용하지 않아도 Athena를 사용해서 대체 가능하다. (time format의 포멧을 변경하거나, 파일의 포맷을 바꾸는 쿼리 옵션도 있기 때문에 Athena에서 쿼리를 작성하면 별도로 Hadoop이나 Spark를 사용하지 않고 데이터 전처리가 가능)
데이터 저장 포맷(CSV, TSV, JSON, Parquet, ORC)
CSV는 Comma Separatored Values로 comma로 구분된 데이터 포멧을 말한다. 그리고 TSV는 Tab Separated Values로, Tab으로 각 칼럼 데이터가 구분된 데이터 포맷을 말한다.
CSV, TSV, JSON은 사람이 읽기에는 용이하나, 압축률이나 데이터를 읽어들이는 속도가 느리기 때문에 빅데이터를 보관 및 저장을 할때는 Parquet나 ORC를 주로 사용한다.
Parquet와 ORC는 column oriented data(columnar)로, 칼럼 기반 저장 포멧이다. 따라서 압축률이 높고, spark, hadoop에서 많이 사용(Parquet)되며, Hive에 특화(ORC)되어있다.
S3 객체의 스토리지 클래스 변경
S3에 보관된 객체의 스토리지 클래스를 변경할 수 있다. 이는 데이터의 사용빈도에 따라서 다르게 해서 적용해야 자원을 좀 더 효율적으로 사용할 수 있다.
그 예시로, Glacier Deep Archive가 있는데, 일년에 한 번 엑세스하는 오래된 아카이브 데이터가 있으며, 매우 저렴하게 이용할 수 있다. 저렴하지만, 해당 스토리지 클래스 객체를 검색하게 되면, 몇 분 내지 몇 시간의 검색 시간이 소요된다는 단점이 있다.Standard는 자주 엑세스하는 데이터로, 한 달에 한 번 이상 접근하는 데이터의 경우에 적용되는 스토리지 클래스이다. 가격이 다른 스토리지 클래스에 비해 비싸다는 단점이 있다.
S3의 수명 주기와 복제 규칙
앞에서는 저장된 데이터 객체의 특성에 따라서 직접 객체의 스토리지 클래스를 변경하였는데, 또 다른 방법으로는 S3 bucket에 수명 주기 규칙이나 복제 규칙등을 지정해주는 것이다.
(AWS S3 버킷 선택해서 내부 버킷으로 들어와서 [관리]탭 선택 - 수명 주기 규칙 및 복제 규칙 생성 및 관리)
이렇게 규칙을 생성해주면, S3 버킷 내의 특정 디렉토리에 계속해서 데이터가 쌓이게 된다고 가정했을때 필터의 접두사로 long-으로 설정해주고, 해당 디렉토리에 쌓인 데이터의 객체의 현재 버전 전환으로 특정 클래스를 지정하고 경과 시간을 입력해주면, log-으로 시작하는 디렉토리에 쌓인 데이터 객체가 지정한 기간 이후에 지정된 스토리지 클래스로 전환이 된다. 이외에도 특정 기간이 지나면 해당 데이터가 삭제되도록 할 수도 있다.
복제 규칙의 경우에는 일정 기간이 지나면 암호화를 하거나 다른 버킷으로 옮기거나 다른 계정의 버킷으로 옮기는 것이 가능하도록 해준다.
본사에 한 달 동안 데이터 분석 처리를 하고, 계열사나 고객사로 데이터를 넘기는 경우, 복제 규칙을 활용할 수 있다.
위와같이 자동화 설정이 가능하다.
AWS Lambda
FaS(Function as Service)로 Serverless computing이라고 한다. CPU나 메모리는 신경쓰지 않고, 오직 코드만 작성하는데 집중할 수 있다.(Infra의 provisioning 없이 내가 선택한 언어로 코드만 업로드해서 사용)
코드는 직접 브라우저에서 작성을 하거나 S3에 업로드된 코드를 import해서 사용할 수 있는 방식으로 되어있다. 초당 수십만개의 데이터를 요청 처리하는 것이 가능하기 때문에 경우에 따라서 이벤트가 올때마다 서버(Spring boot와 같은)에서 처리를 하도록 처리하지 않고, 간단한 코드처리의 경우에는 Lambda에 올려서 처리하도록 할 수 있다. 특정 API 요청이 오거나 Action, Event 가 왔을때 넘길 수 있거나 회원가입이나 간단한 조회의 경우 람다함수를 사용할 수 있다.
비용 청구는 코드가 실행되는 시간(ms)단위로 기준으로 청구된다. (길게 연산이 요구되는 처리에는 적합하지 않다)
다양한 언어를 지원해주며, 연산을 하거나 데이터 처리를 하고 결과만 넘기는 처리(stateless)를 주로 하기도 하지만, 요즘에는 storage를 직접 붙이거나해서 로컬에 데이터를 저장할 수 있도록 변하고 있다.
용도와 가격에 맞게 EC2로 서버를 올릴 것인지 ECS(Elastic Container Service)를 사용해서 서버를 올릴 것인지 선택을 해서, Filebeat를 올릴 것인지 고려를 해서 AWS를 활용하는 것이 좋다.(이 부분은 프로젝트 구성할때 한 번 고려를 해봐야겠다.)
Lambda를 호출(트리거)할 수 있는 것은 API Gateway, S3, SQS, EventBridge가 있다.
시나리오1) S3에 데이터가 들어오면 람다가 돌면서 데이터를 처리한 다음에 다른 서비스로 넘길 수 있다.
시나리오2) SQS(Simple Queue Service)에 이벤트가 쌓이면 Lambda에서 처리를 할 수 있게 할 수 있다.
예를들어, 마케팅을 위해서 여러 다수의 고객들에게 이메일을 보낼때, 사용자 데이터를 뿌려서 큐에 집어넣고, Lambda로 호출해서 큐의 정보를 뽑아서 처리하는 경우에도 활용될 수 있다.
[Lambda 함수 생성]
람다 함수를 생성할때에는 새로 code editor를 사용해서 생성을 하거나 블루프린트(자주 사용되는 template을 AWS에서 제공)로 생성을 할 수 있다.
함수 이름과 사용할 언어의 런타임을 선택해주고, 내부 코드 소스에서 editor에 직접 코드를 입력하거나 S3에 업로드된 code를 담은 zip 파일 패키지를 업로드할 수 있다.
생성된 코드는 별도로 테스트를 할 수 있도록 AWS Lambda에서 테스트 전용 탭을 제공한다. 그리고 작성한 코드에서 아래와 같이 환경변수를 호출해서 사용하는 경우도 있는데, 이 환경변수는 생성한 Lambda 함수의 “구성”탭에서 하위의 “환경변수”를 선택하면 환경변수를 추가할 수 있는데, 여기에 추가된 환경변수를 참조한다.1
2
3
4
5
6
7
8
9
10
11# 예시
import os
#boto3는 python에서 AWS 서비스를 사용할때 많이 사용되는 라이브러리이다.
import boto3
SOURCE_DATABASE = os.getenv('SOURCE_DATABASE')
# AWS Athena 서비스 접근
boto3.client('athena')
# AWS S3 서비스에 접근
Bucket = boto3.resource('s3').Bucket('hg-project-data')
Bucket.put_object(Key=file_name, Body=log)추가적으로 Trigger해주는 서비스들 중에서 CodeCommit이 있는데, 이는 깃에서 코드를 commit했을때 자동으로 CI/CD가 돌도록 구성하는 부분과 같이 CodeCommit의 서비스가 구동이 되면 생성한 Lambda함수가 실행되도록 설정할 수 있다.
Amazon EventBridge
- 서버리스 이벤트 버스이다. 여기서 이벤트 버스란, 수많은 이벤트들을 받아서 라우팅하거나 필터링, 트리거링 할 수 있도록 도와주는 서비스이다.
- EDA(Event-Driven Architecture) 구축을 간편하게 처리할 수 있도록 해준다.
- AWS 서비스에서 생성되는 다양한 이벤트들을 가져올 수 있다.
- 특정 규칙을 지정하고 규칙에 맞을때, AWS의 다른 서비스를 호출할 수 있도록 해준다.
- 리눅스의 cron 기능과 같이 일정 시간마다 AWS 서비스를 호출시켜주는 스케줄러의 기능을 제공한다.
주문이 왔을때 Evnet를 EventBridge로 발생시키고, 발생시킨 EventBridge가 하위의 각 각의 서비스(청구서, 지불 등의 서비스들)을 호출한다. 이전에는 API 호출을 해서 일일이 트리거 시켜줘야했는데 EDA에서는 EventBridge를 사용해서 Loose coupling을 할 수 있고, copepipe라인에 들어온 이벤트를 이벤트 브릿지가 처리해서 람다함수를 호출하게도 할 수 있다.
Apach Airflow를 사용해서 dag를 생성해서 일정 시간에 실행되도록 만들 수 있다.
실습 1) Lambda + EventBridge 통합 실습
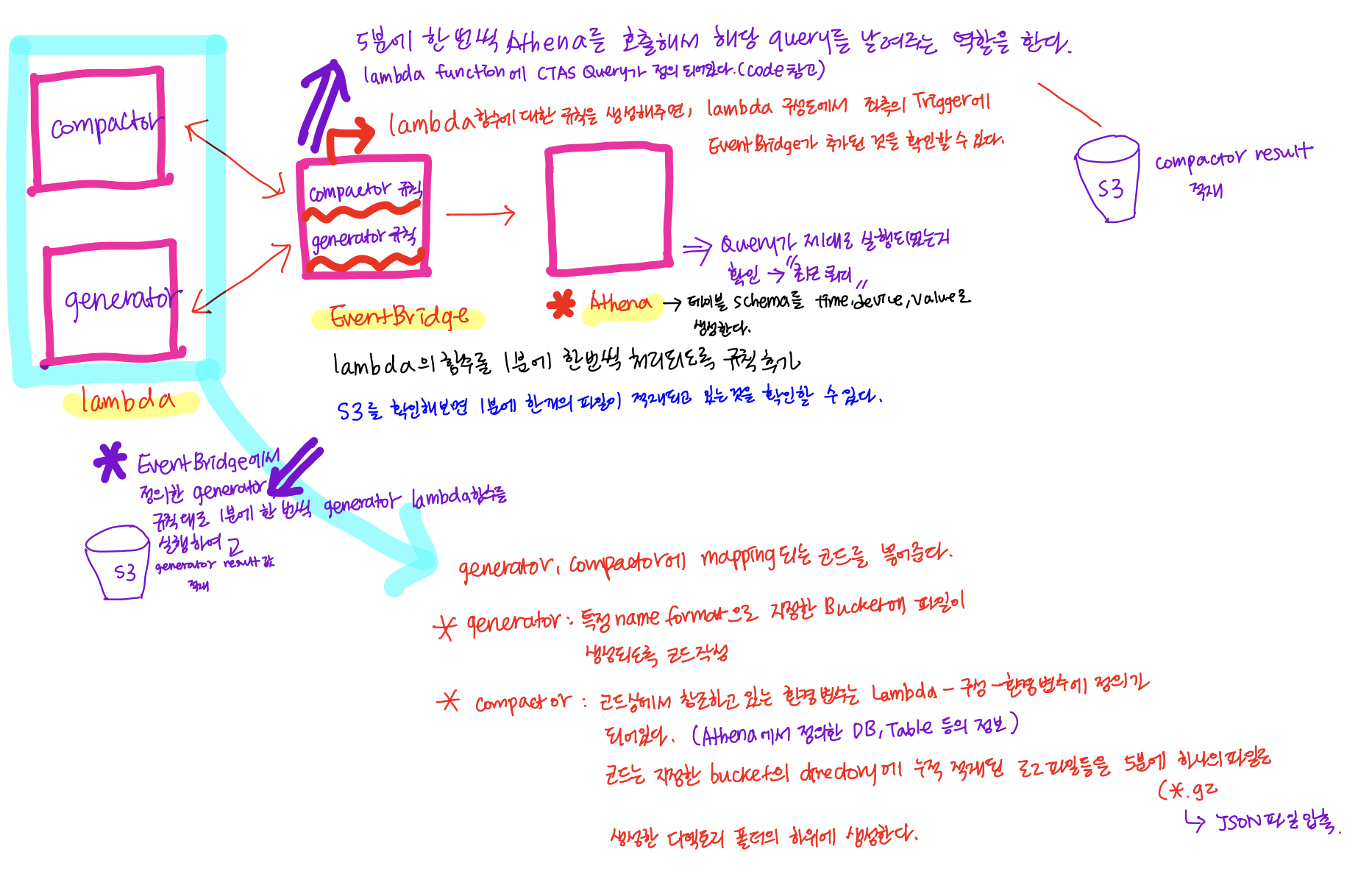
log-generatorLambda function을 생성하는데, s3 버킷에 지정한 디렉토리를 생성하고, timestamp, device_name, metric 값을 생성해서 해당 log값을 내용으로 하는 파일을 버킷에 저장되도록 코드를 구성한다.
반환되는 값은 statusCode와 body의 내용으로 한다.
Access denied 에러가 발생하는 이유는 IAM 권한이 없어서다.
log-generator 코드상에서 결과 파일을 S3에 저장하는 부분이 있는데, 이 부분
때문에 에러가 발생된다.
AWS에서는 whitelist 정책에 의해 허가된 서비스 간에서 서로 통신이 가능하다. 따라서 현재 실습에서는 Lambda에서 S3에 접근을 할 수 있도록 해야한다. (최소권한의 원칙 - Lambda함수에서 업로드를 하는 기능만 하기 때문에 S3서비스에 대해 put에 대한 권한만 부여해야 한다.)
권한에 대한 부여는 생성된 람다 함수의 "구성"탭에서 하위메뉴의 "권한"을 선택하고, 실행역할에 역할 이름 링크를 타고 들어가서 추가 권한을 부여해주면 된다. ("권한추가" - "정책연결" - AmazonS3FullAccess 권한 추가)
그리고 구성 부분에서 timeout 및 메모리의 사용량에 대해서도 편집할 수 있다.
Lambda 함수를 작성하고 반드시 Deploy를 해주도록 하자.
Deploy후에 테스트를 해주면 결과적으로 S3에 코드에서 생성한 임의의 디렉토리의 하위에 파일이 생성된 것을 확인할 수 있다.
EventBridgeTrigger 추가는 우선 EventBridge에 대한 개별설정을 한 다음에 연결되도록 하는 것이 좋다. (EvnetBridge에 대한 개념 설명은 별도의 세션에 정리를 하였다(참고))
EvnetBridge에서"규칙 생성" - 이름 입력 및 규칙 유형을 "일정"으로 선택하고 일정한 빈도로 실행(1분에 한 개씩)할 것이기 때문에 빈도 값과 단위를 선택해서 EventBridge의 규칙을 생성해주면 된다. 그 다음에는 AWS 서비스를 선택하고, Lambda function을 선택해서 이전에 생성한 log-generator lambda function을 선택한다.
이렇게 되면, EventBridge에 의해 Lambda 함수가 실행되어, S3에 파일이 하나씩 떨어지는 것을 확인할 수 있다. (IoT 기기에서 센서 로그를 찍어내는 것과 같은 상황 구현)
log-generator에 의해서 생성되는 JSON 포맷의 데이터에 맞게 Athena table의 schema를 생성해줘야 한다. [Create] - S3 Bucket data을 선택하고, 테이블 명과 데이터 베이스를 선택해준 다음에
Dataset을 현재 1분에 한 개씩 로그 데이터가 쌓이고 있는 location을 지정해준다. 그리고 Data format section에서는 현재 CSV 파일의 형태로 S3 Bucket에 데이터를 쌓고 있기 때문에 JSON을 선택해준다.
열 정보에서는 현재 쌓고 있는 JSON 타입의 데이터의 각 Key값을 column으로 타입과 함께 명시를 해준다.
(최종적으로 테이블을 생성한 다음은 테이블 미리보기를 통해서 테이블을 통해 값을 미리 확인해본다)5분에 한 번씩 compaction해서 처리하는 Batch 작업을 하기 위해
log-compactor Lambda 함수를 생성한다.
log-compactor에서는 5분에 한 번씩 Athena에 쿼리를 날려서 압축 및 변환을 하는 query를 실행을 시키도록 하는 부분이다. (실제 실행은 Athena에서 처리)
실제 log-compactor Lambda 함수의 파이썬 스크립트를 살펴보면, 실제 Athena로 전송하는 CTAS 쿼리문의 조건 WHERE 절을 살펴보면, timestamp 칼럼의 start_time, end_time을 통해 특정 기간내의 데이터 파일만 모아서 하나의 파일로 압축하는 형태로 쿼리를 처리하고 있다.
log-compactor lambda 함수의 환경변수는 S3의 Bucket(1분에 한 개씩 센서 데이터를 누적하고 있는 버킷)과 Athena에서 생성한 테이블 정보와 테이블을 포함하고 있는 DB, 생성될 파일의 prefix(NEW_TABLE_NAME), 참조할 DB와 TABLE 정보를 입력해주면 된다.새로 생성한 log-compactor Lambda function에는 이전 log-generator Lambda function과 동일하게 Athena와 S3에 접근해서 처리할 수 있도록 권한을 부여해야 한다. (
AmazonS3FullAccess, AmazonAthenaFullAccess)이제 생성한 log-compactor Lambda 함수와 mapping되는 EventBridge 이벤트를 생성해줘야 한다. 이 EventBridge는 log-generator와 동일하게 하되, 5분 간격으로 복수 개의 파일에 대해 compaction을 할 것이기 때문에 5분 단위로 lambda함수가 실행되도록 해야한다.
S3의 압축된 파일도 압축된 original file의 데이터 타입(JSON)을 통해 “Query with S3 Select”를 해서 제대로 데이터가 찍혀있는지 확인을 할 수 있다.
기타 주의사항
- Athena 테이블에서 ‘-‘ 특수기호를 넣어서 DB나 Table이름을 지정하게 되면, 쿼리에서 테이블을 호출 할때 에러가 발생한다.
(중요)Apache Kafka
Apache Kafka는 데이터 엔진지어 분야 외에도 백엔드에서도 많이 사용된다.
MS에서 인수한 Linked에서 개발되었다가 2011년쯤에 오픈소스화된 프로젝트로, 스칼라 언어로 개발되었다. 주로 데이터 스트림을 위한 미들웨어, 메시지 큐, 메시지 브로커(이벤트 브로커)등의 말로 불리고 있다.
어플리케이션이나 소프트웨어 간의 메시지 중계자 역할을 해주고 있다.
[Kafka의 특징]
pub/sub 모델이다.
데이터의 영속성을 가진다.(
Data Persistency) 일정기간동안 데이터를 보관하기 때문에 데이터의 재처리가 가능하다.손쉽게 scale in/out이 가능하며, 고가용성이다. (
Highly scalable and available)At least once를 지원(
최근에는 exactly once를 지원하지만 성능이 낮아진다)
비동기 처리를 위한 Pub(발행)/Sub(구독) Model
마치 전화가 아닌 이메일과 같은 연락 방식과 유사하다고 생각할 수 있다.
송/수신 관계에 있는 양 극단의 Publisher와 Subscriber가 Direct로 연결하는 방식이 아닌, 중간에 중개자 역할을 해주는 Broker를 위치시킨다.
(A----(Broker)----B)A는 B 서버로 보내기 위해 B의 서버 주소나 DNS에 관한 정보를 알 필요 없이 바로 Broker로 데이터를 보내서 적재하면 되며, 만약에 B 서버에 문제가 생겨서 다운되더라도 A에서 송신한 데이터는 Broker에 누적이 되고 있기 때문에 B 서버가 복구된 후에 Broker로부터 쌓인 데이터를 이어서 수신해오면 된다.
그리고 Subscriber 역할을 하는 B는 역량만큼만 Broker로부터 데이터를 취득해서 처리하며, 기존 API호출의 경우에는 DDos 공격과 같이 request를 무한정 보내서 문제가 될 수 있지만, 중간에 Broker역할을 해주는 Message Queue를 위치시켜주면, 구조상 Loose coupling이 가능해서 DDos와 같은 문제상황을 사전에 예방하고, 확장가능한 설계를 할 수 있다. (
Direct로 A와 B 서버를 연결하게 되면, 이러한 확장 가능한 구조가 되지 않는다)MSA(MicroService Architecture) - 확장 가능한 설계
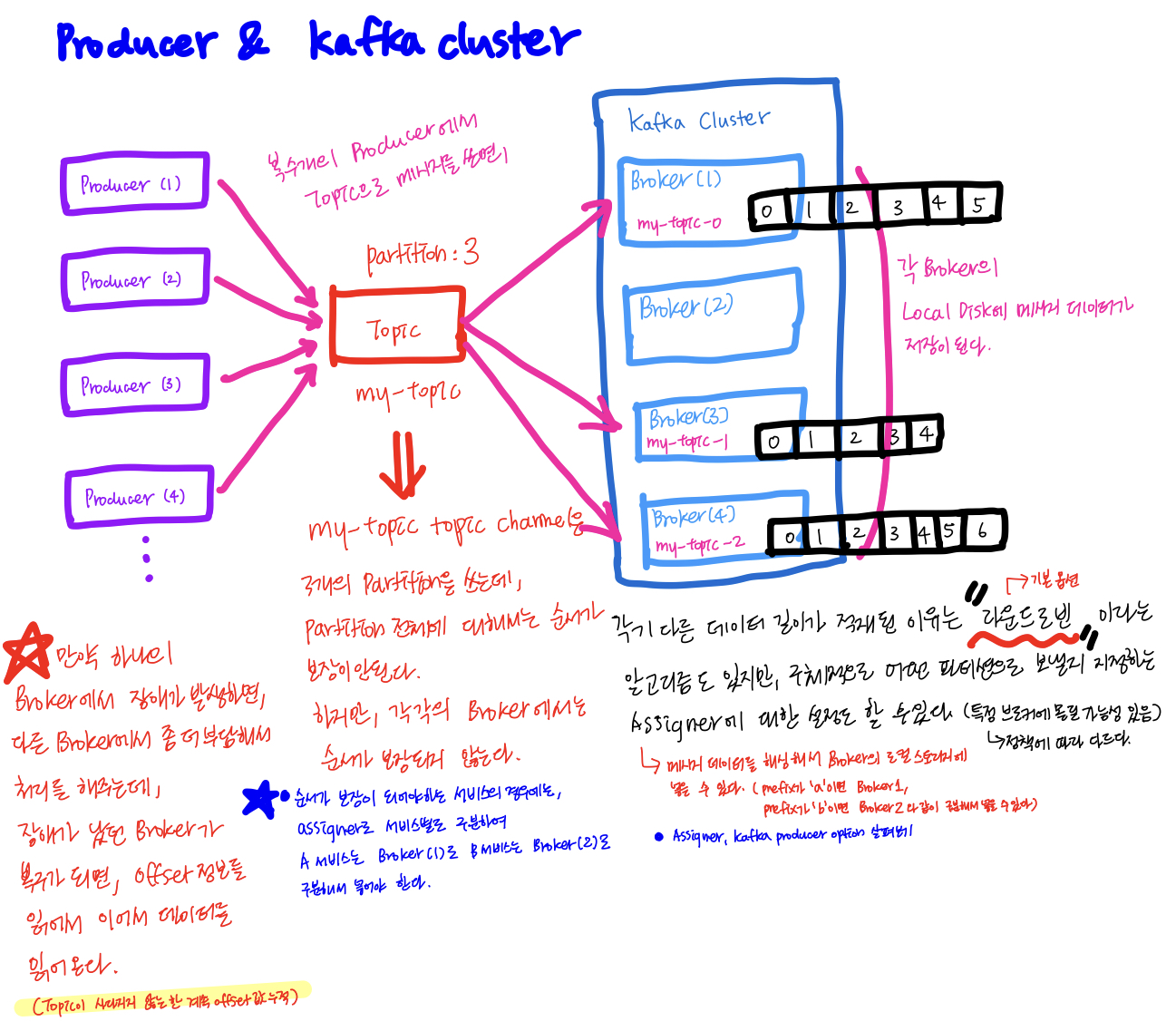
Kafka에서는 Producer(Publisher), Consumer(Subscriber)라고 한다.
원래 RabbitMQ나 일부 메시지 큐의 경우에는 메시지 큐에서 받은 데이터를 가져가면 브로커 입장에서는 메시지가 사라지게 된다.(일정기간 in-memory에 가지고 있다가 최종 전달자에게 전달하면, 사라지는 형태로 동작) 하지만, Kafka의 경우에는 publisher가 데이터를 넣으면 스토리지에 저장한다. (데이터의 영속성(Persistency)
(Data retention 기간(데이터를 스토리지에 저장하는 기간)에 대한 설정을 할 수 있다. (해당 retention 기간 내에는 다른 consumer들이 요청을하면 같은 메시지를 처리할 수 있다 - 데이터 재처리 가능))
Kafka의 구조
Kafka는 Broker라고 불리우는 서버가 여러대로 클러스터링 되어 구성되어있으며, Apache Zookeeper와 함께 쓰인다. Apache Zookeeper는 누가 리더인지 정해주는 코디네이터 역할을 해준다. Apache 3.0부터는 Zookeeper없이 Zookeeper의 기능을 Broker가 내장되서 기능이 개선되고 있다. 아직은 Production 단계이며, 올해 말쯤에는 도입될 새로운 기능이다.
이렇게 Kafka cluster + Apache Zookeeper에 producer와 consumer가 붙어서 데이터를 주고받는 형태를 갖는다.[참고] KIP-500 Issue
Kafka open source project 500번 이슈 -> Kafka without Zookeeper(kafka 2.8)
Zookeeper의 기능
Zookeeper는 분산된 카프카 브로커를 클러스터링해주는 중요한 컴포넌트이다. 클러스터링 되어있는 Broker들 사이에서도 리더가 있어서 어떤 친구가 데이터를 처리할 것인지, 쓸 것인지 구분해야 되기 때문에 Zookeeper가 이러한 리더의 선출을 담당한다. 그리고 파티션 수와 같은 Topic(
Topic은 메시지를 넘겨 줄때 사용되는 채널이며, 해당 토픽에 producer가 메시지를 push하고, consumer가 메시지를 pull해서 소비하는 구조의 형태로 되어있다)의 메타데이터를 관리하며, 정보를 공유한다.
또한 새로운 브로커를 추가하거나 브로커의 장애를 감지하는 기능을 한다.Topic / Partition
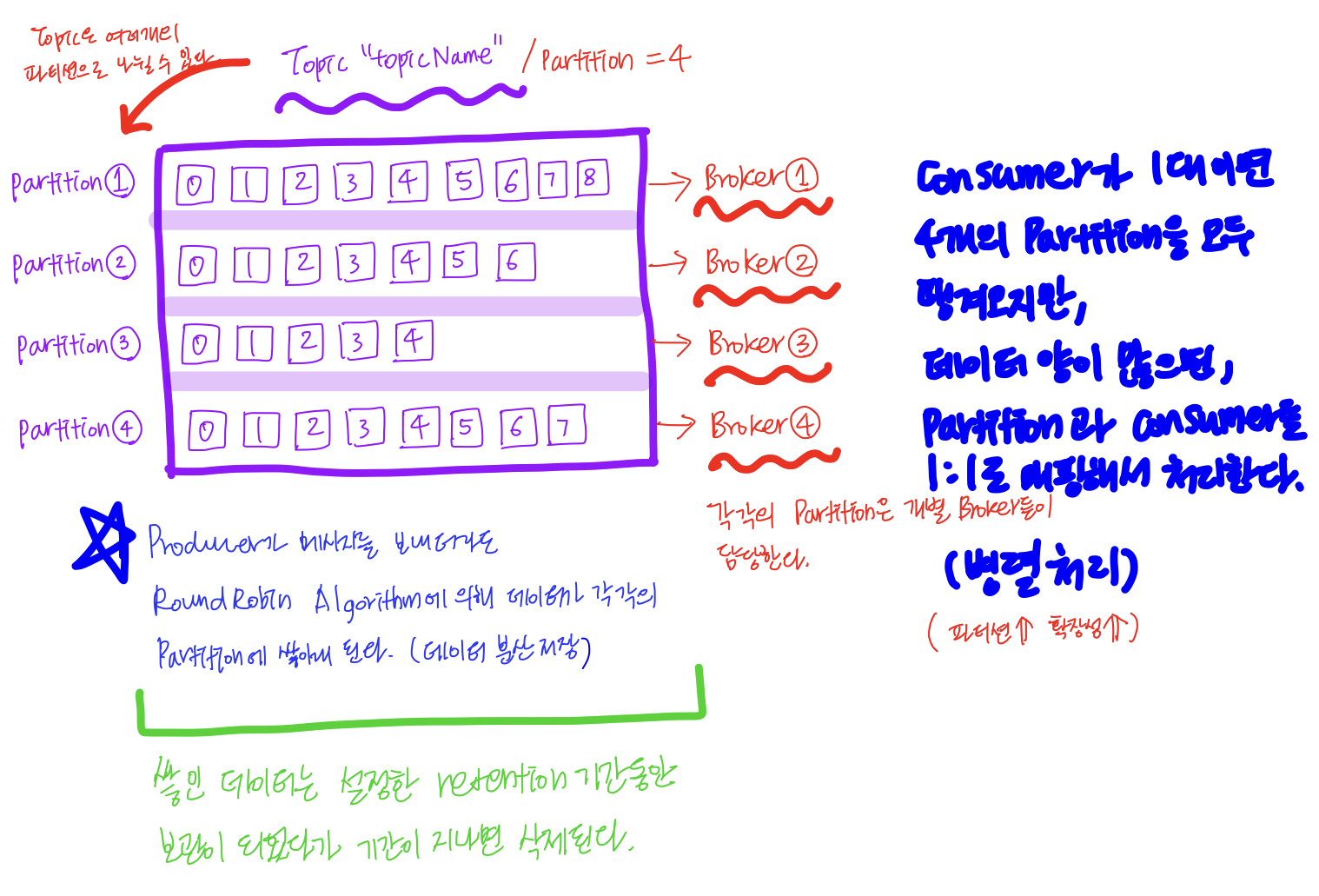
Topic은 메시지를 분류해주는 채널이며, partition은 Topic을 여러 애들이 분산처리하기 위해서 파티션으로 나눈다.(
데이터 병렬 처리) 그리고 나뉜 파티션들은 각 각 브로커들이 담당한다.단일 파티션 생성이 가능하지만, 내결함성이 떨어진다.(
만약에 토픽에 브로커가 세 대있는데, 단일 파티션으로 하나의 브로커만 이용하도록 하면, 장애가 발생해서 데이터가 유실되었을 했을 때 대처하기 어렵기 때문에 세 개의 브로커를 사용하는 것이 좋다)
단, 파티션은 늘릴 수는 있어도 줄일 수는 없다.나뉜 각 각의 파티션은 데이터양이 많을 경우, 각 각의 파티션에 consumer를 물려서 확장성있게 대량의 데이터를 처리할 수 있다. (
확장성과 병렬처리 - 파티션)모든 메시지는 offset 값(bigint 기준)으로 어디까지 메시지가 읽혔는지 기록이 된다. (토픽이 새롭게 생성되지 않는 이상 계속 증가되는 형태이다)
Replication
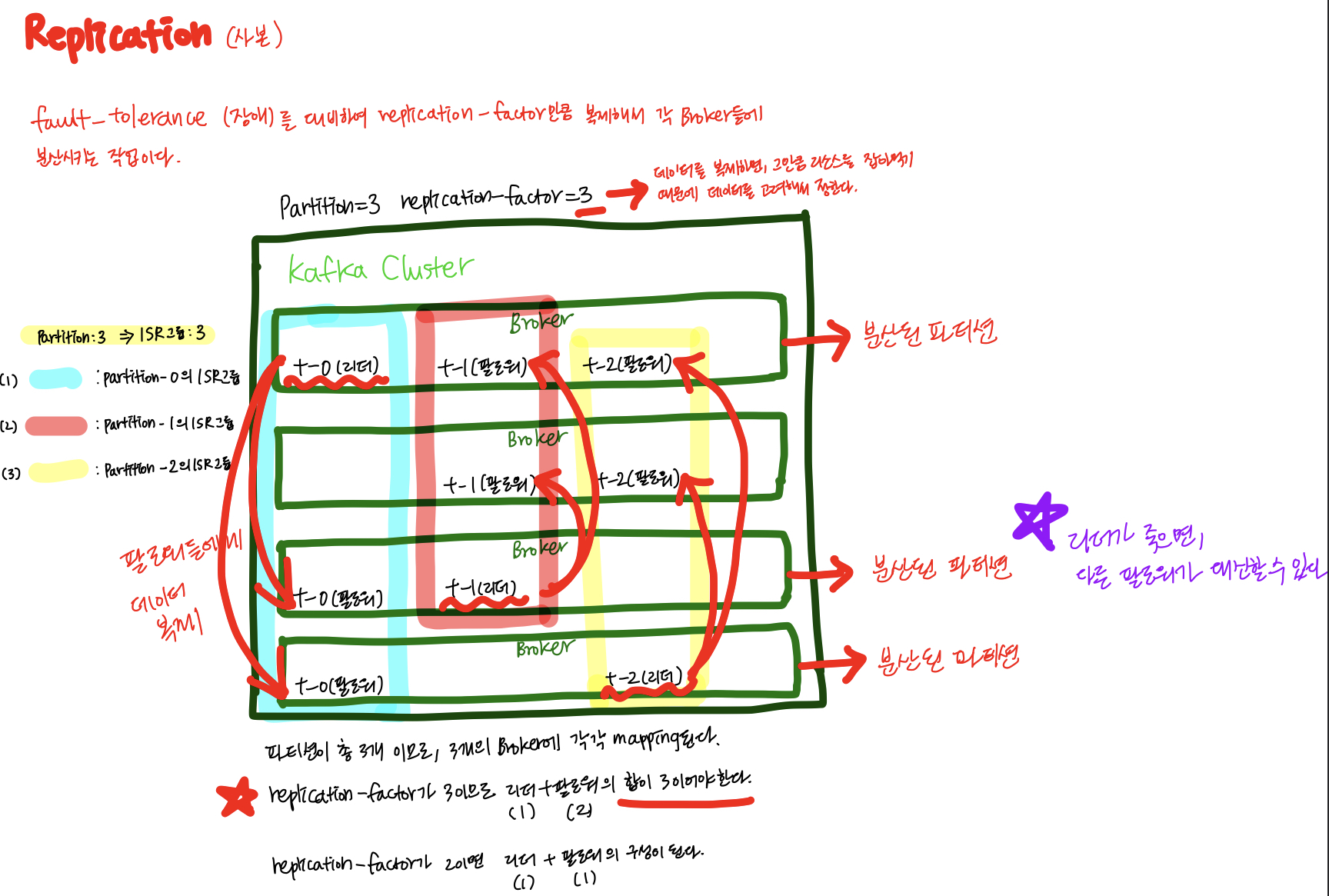
Replication이란, Fault-tolerance(장애)에 대비하여 메시지를 설정한
replication-factor만큼 복제해서 각 각의 브로커들에 분산시키는 작업을 말한다.
데이터는 파티션 단위로 복제를 하며, 복제를 통해 일부 브로커가 불능 상태가 되어도 전체 클러스터는 정상 작동하도록 도와준다.
안전을 위해서 권장은 되지만, overhead가 존재하기 때문에 토픽의 특성과 리소스 사용량을 고려해서 replication-factor를 정해야한다.ISR(In-Sync Replicas)와 Producedr acks
- Replication을 위해서는 파티션별로 Zookeeper가 Leader와 Follower 역할을 할당한다.
- Leader와 Follower는 ISR이라는 그룹으로 묶는다.
- 각 각의 파티션의 Leader들은 Follower들이 offset을 잘 맞춰서 따라오고 있는지 모니터링하고, 잘 못 따라오는 Follower가 있다면, ISR 그룹내에서 추방한다.
- Follower들은 Leader가 가진 데이터와 자신의 데이터를 일치시키기 위해서 지속적으로 리더로부터 데이터를 땡겨온다.
- Leader가 불능상태가 되면, ISR 그룹 내의 Follower 중 하나를 Leader로 선출한다.
Consumer & consmer group(메시지를 가져오는 에이전트들의 집합)
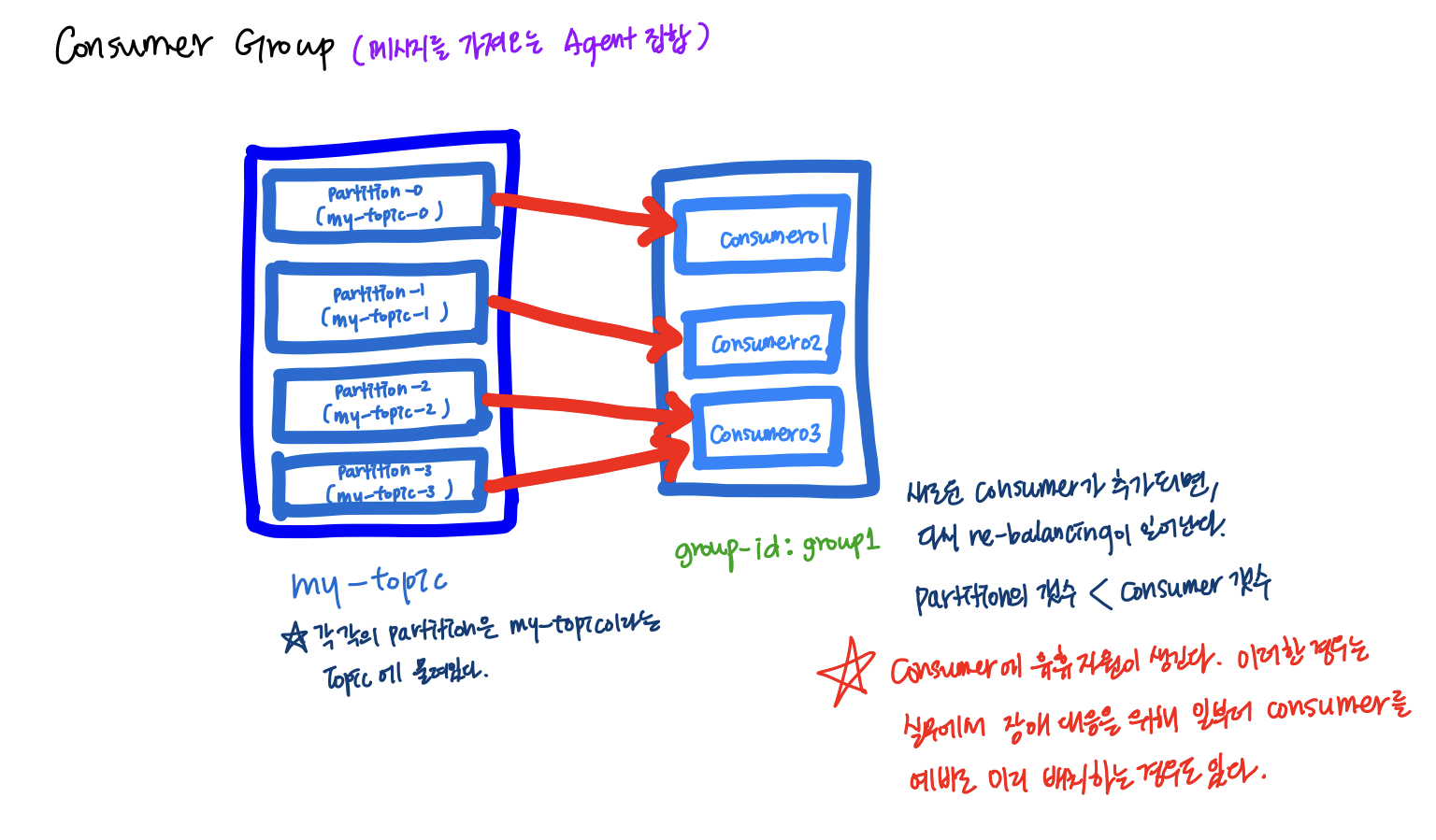
Consumer Group으로 나누는 이유는 그룹내의 Consumer들끼리 서로 중복된 데이터를 땡겨오지 않게 하기 위해서이다.
Consumer는 특정 Consumer Group에 반드시 속한다.
각 consumer들은 토픽의 파티션에 1:1로 매핑되어 메시지를 땡겨온다.
Consumer Group은 고유 group-id를 가지고 있고, 이를 통해 그룹을 구분하고, offset등의 정보를 관리한다.
Consumer를 띄울때 Consumer Group을 지정할 수 있다.
consumer group의 group id를 group1으로 띄우게 되면, 이 group1에 속한 Consumer들이 모든 데이터를 땡겨오고 나서 다음 offset부터 데이터를 땡겨올 수 있다. (
group-id: group1로 지정한 경우)
하지만데이터의 처음 offset부터 데이터를 다시 땡겨오고 싶은 경우에는 어떻게 해야될까?방법은 group-id를 group1이 아닌 다른 이름의 consumer group(다른 이름)으로 해서 별도의 Consumer를 그룹화하면 된다. 그러면 새로 생성한 group-id: x는 offset을 처음부터해서 데이터를 읽어온다.
따라서지정한 group-id별로 offset이 관리가 된다는 것을 이해할 수 있었다.각 consumer group에 속한 consumer들은 메시지를 가져오고, 그 메시지에 해당하는 offset을 commit하게 되는데, 메시지를 어디까지 가져왔는지 Broker에 표시하기 위한 용도로 사용한다.
offset 값을 통해서 데이터를 생산해내는 쪽(producer)와 소비하는 쪽(consumer)간의 속도차이도 파악할 수 있다. 만약 producer에서 100의 데이터를 보내고 consumer에서 50만큼 소비했다면, 이 속도차이 50을
Lag(데이터의 생산과 소비 속도차이)-offset 번호 차이이라고 한다.
이를 통해 producer와 consumer의 갯수를 조정한다.
Consumer 장애 발생시 구동 방식
- Consumer group내에서 특정 Consumer에 장애가 발생하면, re-balancing이 일어나서 consumer 그룹 내의 다른 consumer가 장애 발생한 consumer의 몫까지 데이터를 소비한다. 이후에 장애가 발생한 consumer가 복구가 다 되면, 다시 Partition과 연결되어 데이터를 이어받는다.
- 데이터가 많아져서 파티션을 늘린 경우에는 다수의 Partition을 하나의 Consumer에 물릴 수 있다. 단, 하나의 파티션에 여러개의 Consumer가 붙을 수는 없다.
Producer
Kafka broker에 메시지를 send/publish/produce하는 인스턴스(에이전트)이다.
Producer관점에서는 Acks 옵션 [0, 1, -1(all)]이 매우 중요하다. 이전에 ISR 그룹 내에서의 작동원리에 대해서 배웠는데, Producer의 입장에서는 아래와 같이 acks의 옵션으로 다르게 할 수 있다.
acks=0으로 설정을 하면, 안정성은 낮은 대신에 속도가 빠르다. 그 이유는 프로듀서가 리더 파티션에 메시지를 전송하고 나서 리더 파티션으로부터 별도의 acks(확인)을 하지 않는 방식이다. 재전송이나 offset을 신경쓰지 않기 때문에 별로 중요하지 않은 로그 데이터를 보낼때 사용되는 옵션이다.acks=1은 안정성과 속도가 중간으로, 프로듀서가 리더 파티션에 메시지를 전송하고, 리더로부터 ack를 기다린다. 하지만 팔로워들에게까지 잘 전송되었는지에 대해서는 신경쓰지 않는다. 리더들에게는 ack를 받았지만, 팔로워들에게 데이터를 복제하는 도중에 리더가 죽으면 fail이 발생한다.acks=-1(all)은 안정성이 높은 대신에 속도가 느리다는 특징을 가진다. 프로듀서가 전송한 메시지가 리더와 팔로워 모두에게 잘 저장이 되었는지 확인을 전부하기 때문에 속도가 느릴 수는 있지만 안정적이다. ISR에 포함된 모든 파티션에 전달이 되었는지 확인하는 것이 아닌min.insync.replicas에 값을 별도로 지정해서 몇 번째 팔로워까지 복제본 저장이 되었는지 확인을 해야하는지 지정할 수 있다.
(min.insync.replicas 값이 2이면 리더(1), 팔로워(1)까지 확인을 하고, 값이 3이면, 리더(1), 팔로워(2)까지 확인을 한다.)
Amazon MSK(Managed Streaming for Kafka)
이전에 완전 관리형 Kafka 서비스라고 들어본적이 있는데, 마침 오프라인 수업에서 다뤄주셔서 너무 좋았다.
Amazon MSK는 Zookeeper의 설치 없이 손쉽게 Kafka cluster를 관리하고 Connector 연동하는 것이 가능하다.
Kafka는 Connector가 중요한데, 앞/뒤로 데이터를 넣고 빼는 부분을 MKS에서는 플러그인을 설치해서 연결시켜줄 수 있다.
아직 한국에서는 서비스를 하고 있지 않지만, Amazon MSK Serverless라고 하는 별도의 용량관리 없이 자동으로 프로비저닝해주고, 순수 Kafka의 기능 API만 사용하도록 지원하고 있다.
(Amazon Kinesis가 Amazon MSK Serverless와 같이 Kafka의 기능을 별도의 프로비저닝 없이 기능만 사용하고 사용한 만큼 요금만 납부하는 형태로 이용할 수 있도록 해주는 서비스이다)