
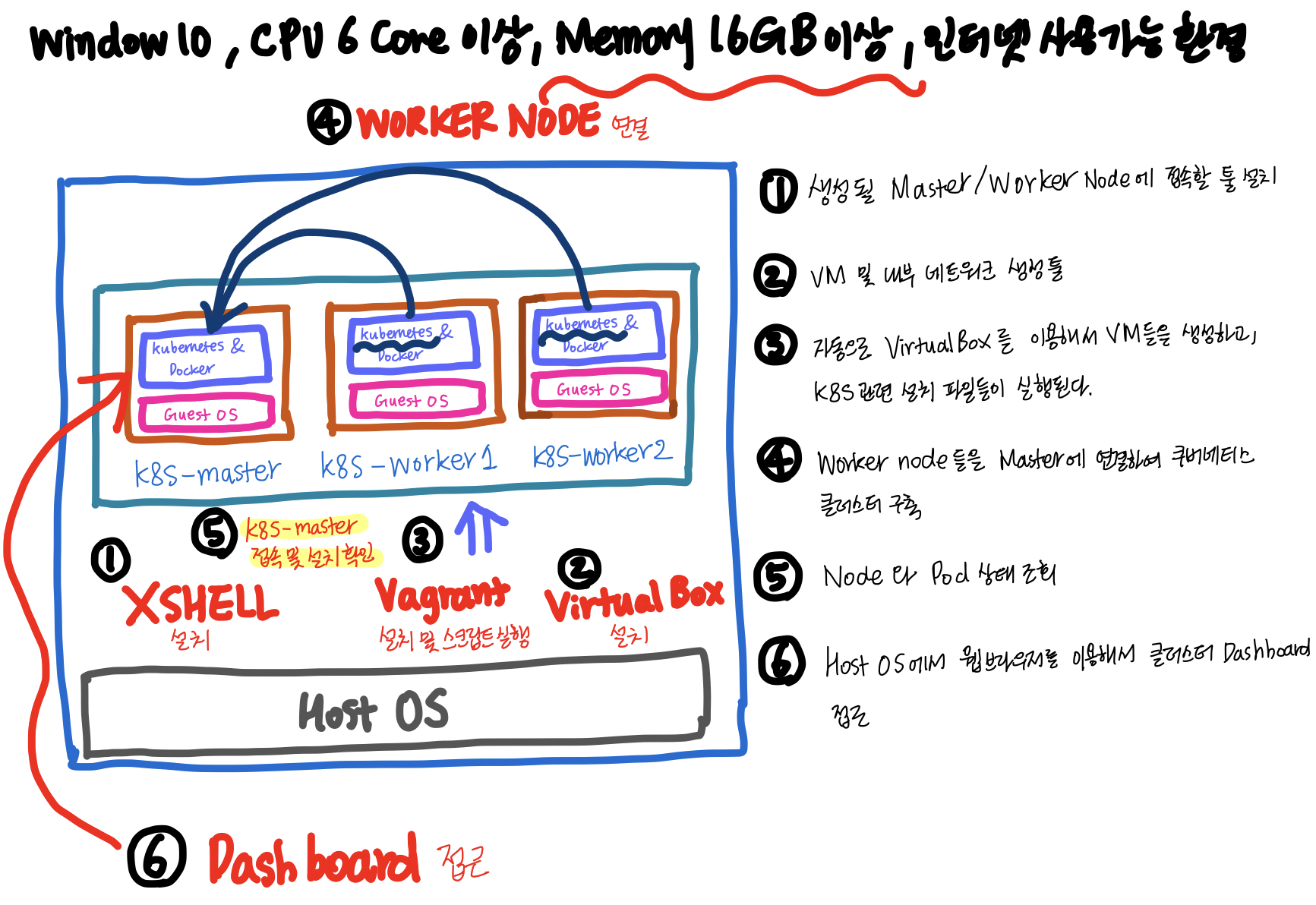
쿠버네티스 클러스터 실습 구성도
Vagrant 명령(손쉽게 VirtualBox의 VM관리)
host os의 cmd창에서 실행
1 | $vagrant up: 가상머신 기동 |
네트워크 구성 이해
Vagrant 스크립트 안에 VirtualBox를 이용해서 어떤 내부 네트워크를 생성하라는 부분이 있고, VirtualBox는 VirtualBox Host-Only와 nat를 만들어주는데, nat의 역할은 각 각의 VM들에 특정 ip를 똑같이 할당해줘서 똑같이 할당된 ip가 인터넷과 연결된 nat와 연결이 되서, 외부 인터넷과 연결이 된다.
위의 과정이 있기 때문에 스크립트가 실행되는 동안 필요한 설치파일을 다운받아서 설치할 수 있는 것이다.
VirtualBox Host-Only는 각 각의 VM에 개별 IP를 할당해서 VM간의 통신을 하는 역할과 HOST OS에서 쉘을 통해서 개별 IP를 통해 VM에 접근할 수 있도록 돕는다.
클러스터 설치가 완료되면,
Service Network CIDR: 10.96.0.0/12
(서비스의 IP대역대는 10.X.X.X)
Pod Network(CNI: Calico)CIDR: 20.96.0.0/12
(파드의 IP대역대는 20.X.X.X)
Maser node에서 kubectl 명령으로 설치 확인
1 | $kubectl get pod -A #모든 파드들의 상태정보 확인 (Running Status 확인) |
이후에 최종적으로 브라우저를 통해 K8s cluster의 Dashboard 확인한다.
Maser node 재기동 후에 Dashboard 접근시에 아래의 명령으로 Proxy를 오픈
1 | $nohup kubectl proxy --port=8001 --address=192.168.56.30 --accept-hosts='^*$' >/dev/null 2>&1 & |
Container & Label & Node Schedule 이미지 트레이닝하기
[Container]
클러스터 내의 단일 Pod 내에는 복수 개의 컨테이너가 위치 할 수 있다. Pod 내의 컨테이너들에는 내부에서 컨테이너들간에 통신을 위해 각 각 복수 개의 ip를 할당할 수 있는데, Pod 내에서는 반드시 고유한 IP여야한다. (IP 충돌)
각 각의 Pod에는 하나의 고유 IP 주소가 할당되는데, 클러스터 내에서 이 IP를 통해 해당 Pod에 접근을 할 수 있다. 하지만, 클러스터의 외부에서는 이 Pod IP를 통해 접근이 불가능하다. 이 고유 IP의 경우에는 Pod에 문제가 생겨서 시스템이 자동 감지하여재생성을 해주게 되면, IP도 재할당된다.1
2
3
4
5
6
7
8
9
10
11
12
13
14apiVersion: v1
kind: Pod
metadata:
name: pod-1
spec:
containers:
- name: container1
image: tmkube/p8000
ports:
- containerPort: 8000
- name: container2
image: tmkube/p8000
ports:
- containerPort: 8080[Label]
Label은 사용 목적에 따라 등록해서 사용하는데, 모든 Object에 Label을 다는 것이 가능하지만,
주로 Pod에서 사용된다.
Label은key:value형태의 구조를 가지며,Service를 특정 label별로 그룹화하거나Pod를 특정 label별로 그룹화할 때 사용된다.
Pod들에 type과 lo라는 Key값이 할당되어있다고 가정했을 때, 아래의 예시 yml 파일과 같이 Service는spec > selector > type에 값을 정의해서 Service를 Pod별로 묶어서 정의할 수 있다.Pod는
metadata > labels > type, lo에 값을 정의해서 개별 Pod를 그룹화해서 묶을 수 있다.이렇게 Pod들을 묶어서 관리해서 사용하는 예시로는,
상황1) 웹 개발자가 웹 화면만 확인하고 싶을 때, type이 web인 port들만 service에 연결시켜서 웹 개발자들에게 알려줄 수 있다.
상황2) 서비스 운영자가 각자가 원하는 Pod에 접근하고자 할 때, lo: production인 Pod들을 묶어서 새로운 pod의 이름을 할당해서 알려줄 수 있다.
Service.yml1
2
3
4
5
6
7
8
9apiVersion: v1
kind: Service
metadata:
name: svc-1
spec:
selector:
type: web
ports:
- port: 8080Pod.yml1
2
3
4
5
6
7
8
9
10
11apiVersion: v1
kind: Pod
metadata:
name: pod-2
labels:
type: web
lo: dev
spec:
containers:
- name: container
image: tmkube/init[Node Schedule]
각 각의 Pod들은 여러 노드들 중에 하나의 노드에 올라가야한다. 노드에 올리는 방법으로는
직접 선택과k8s가 자동으로 선택해주는 기능이 있다.[직접 선택]
우선 직접 Pod가 올라갈 Node를 지정해주는 방법으로는 아래와 같이 Pod 생성시에
spec > nodeSelector > hostname: node1와 같이 해당 노드 이름을 Pod의 yml파일에서 할당해줄 수 있다.각 각의 Node에도 label을 달 수 있는데, 위의 hostname의 값으로 연결하고자 하는 Node의 hostname을 넣어주면 된다.
1
2
3
4
5
6
7
8
9
10apiVersion: v1
kind: Pod
metadata:
name: pod-3
spec:
nodeSelector:
hostname: node1
containers:
- name: container
image: tmkube/init[자동 할당]
Pod를 Node에 자동으로 할당하는 방법은 스케줄러가 판단해서 할당해주는 방법이 있는데, Scheduler가 현재 각 각의 node들이 가지고 있는 여유 메모리 공간을 확인하여, 메모리상 여유가 있는 Node에 자동할당하고자 하는 pod를 할당해주게 된다.
pod의 yml파일에서spec > containers > resources > requests > memory, limits에서 request의 memory에 요구되는 메모리의 양을 명기하고, requests의 limits에 최대 허용 메모리를 명기해줌으로써 HDD의 App에서 부하가 생겼을때 무한정으로 노드의 자원을 사용하는 것을 막는다.만약 설정을 안하게 되면,노드 내의 자원을 무한정으로 사용하게 되고, 이로인해 노드내의 자원이 부족해지게 되면, 노드 내의 다른 pod들은 자원이 없어서 다 같이 죽게 되는 상황이 된다.memory가 초과되면 클러스터 내의 pod를 종료시키지만, cpu가 초과되면 request의 memory 용량의 수치를 낮추고, memory가 초과되었을 때와 같이 pod가 종료되지는 않는다.이렇게 Memory와 Cpu가 다르게 동작하는 이유는 각 자원의 특성이 다르기 때문인데, 예를들어 파일을 복사할때 또 다른 파일을 또 다시 복사하게 되면, 기존 작업들이 중단되지 않고, 단지 처음 복사한 파일의 작업의 속도가 느려지게 된다. 이러한 예처럼 클러스터 내에서 cpu가 초과하게 되면, pod가 종료되지 않고, 단지 requests의 memory의 사이즈가 줄어들게 되는 것이다.
pod.yml1
2
3
4
5
6
7
8
9
10
11
12
13apiVersion: v1
kind: Pod
metadata:
name: pod-4
spec:
containers:
- name: container
image: tmkube/init
resources:
requests:
memory: 2Gi
limits:
memory: 3Gi
실습내용
Pod 생성
Pod내에 각기 다른 port가 할당되어있는 container생성
Pod 내에 동일한 ip를 가진 컨테이너 생성
pod내에서 각 각의 컨테이너가 동일한 ip를 가질 경우, 충돌이 일어나기 때문에 제대로 Pod가 생성되지 않는다.
ReplicationController
ReplicationController로 pod를 생성하고, 다시 ReplicationController를 삭제하게 되면, controller가 삭제가 진행됨과 동시에 새로운 ReplicationController를 사용해서 pod를 다시 재생성한다.(
pod의 ip가 재할당)근데 영구적으로 삭제는 어떻게 하는거지??
1
2
3
4
5
6
7# k8s-master node 에서
$kubectl get pods # 현재 cluster내에 있는 pods 리스트 출력
# replication controller관련 파트들을 삭제하기 위해서
$kubectl delete rc rep-pod # NAME이 rep-pod-* 인 모든 replication controller를 삭제한다. 문자-pod 까지만 입력(첫 - 다음 문자까지만 입력)
# namespace가 default로 설정된 모든 pod들을 삭제하도록 한다. (이렇게 삭제하면 rc 파드가 다시 생성된다. 따라서 kubectl delete rc [삭제하고자 하는 pod name]의 패턴으로 rc pod를 삭제해줘야 한다)
$kubectl delete --all pods --namespace=default복수의 pods를 label별로 묶어서 service 생성
yml 파일에서 spec > selector > type: web을 통해서
type이 web인 pod들을 묶어서 service를 생성할 수 있다.
그리고 production 전용의 pod들을 묶기 위해서 lo: production인 pods를 모아서 service를 생성할 수도 있다.pod의 현재 CPU 및 메모리 사용량 확인
현재 dashboard에서 CPU, MEMORY 사용량에 대한 확인이 안되는데, 방법 찾아서 해결하고, console에서 명령으로 확인할 수 있는 방법 찾아보기