
이번 포스팅에서는 도커에 대해 학습한 내용에 대해서 정리하려고 한다.
도커를 이해하기 위해서는 서버를 관리하는 것에서부터 시작해야 되는데, 서버관리는 내부적으로 매우 복잡하고, 각 각의 과정이 서로 종속되어있다.
전통적인 서버 관리 방식으로 비춰보면, 서버에 특정 서비스를 설치하고자 할 때, 환경적인 제약으로 인하여 예상하지 못한 문제가 발생하기도 하고, 지속적으로 바뀌는 서버 및 개발 환경으로 인해 지속적으로 기존의 서버를 다시 설정해야 되는 경우가 생겨서, 서버의 유연성이 많이 떨어진다.
Docker의 등장
위와같은 전통적인 서버 관리 방식에서의 환경적 제약으로 인한 설정 오류와 유연한 서버 환경 교체에 대한 솔루션으로 등장하게 된 것이 바로 도커(Docker)라는 친구이다.
Docker를 사용하면, 어떠한 서비스(프로그램)을 하나의 컨테이너로 만들어서 관리를 할 수 있다.
그리고 만들어진 컨테이너는 어떤 환경적인 제약도 없이 어디서든 돌아가게 된다.(AWS, AZURE, GOOGLE CLOUD, KT UCLOUD, NAVER CLOUD PLATFORM 등…)
Docker가 등장하기 전에는 서버내에서 각 각의 서비스가 다른 버전의 Package를 사용하는 경우, 버전 변경에 있어 어려움이 있었다. 그로인해 배포를 위한 전체 과정 중에 한 부분이라도 문제가 생기게 되면 서비스가 구동이 되지 않는 문제에 직면하기도 하고, 전통적인 서버관리의 방법에는 많은 문제가 있었다.
서버 관리 방법의 변천
위의 전통적인 서버관리 방식에서 생겨나게 된 문제를 개선하기 위해서 가장 먼저 도입된 것이 바로 "서버배포를 위한 메뉴얼화(문서화)"였다. 하지만, 잘 정리된 문서를 보고 따라하더라도 제대로 동작하지않는 경우도 있었고, 문저 정리가 중간에 잘 안되는 경우도 많았다. 그리고 특정 OS를 타겟으로 작성된 문서의 경우, 다른 OS에서 예외가 발생하는 경우도 많이 생겼다.
이러한 문서관리에 문제가 많아 생겨나게 된 것이 바로 "상태관리 도구(CHEF, PUPPET LABS, ANSIBLE)"이다. 이 상태관리 도구는 각 서버 설정의 단계를 스크립트로 작성을 하고 관리를 하기 때문에 스크립트를 실행함으로써 마치 서버 관리자가 STEP BY STEP으로 명령어를 작성한 것과 같은 효과를 준다.
이렇게 코드로 관리함으로써 다른 관리자들과 협업도 가능하고, 버전관리도 가능하며, 코드이기 때문에 깃과 같은 저장소로 공유도 가능하다. 하지만 상태관리 도구를 사용함에 있어 러닝커브가 높다는 문제와 한 서버에 다른 버전의 동일 서비스를 설치할 때 문제가 있다는 것을 알게 되었다.
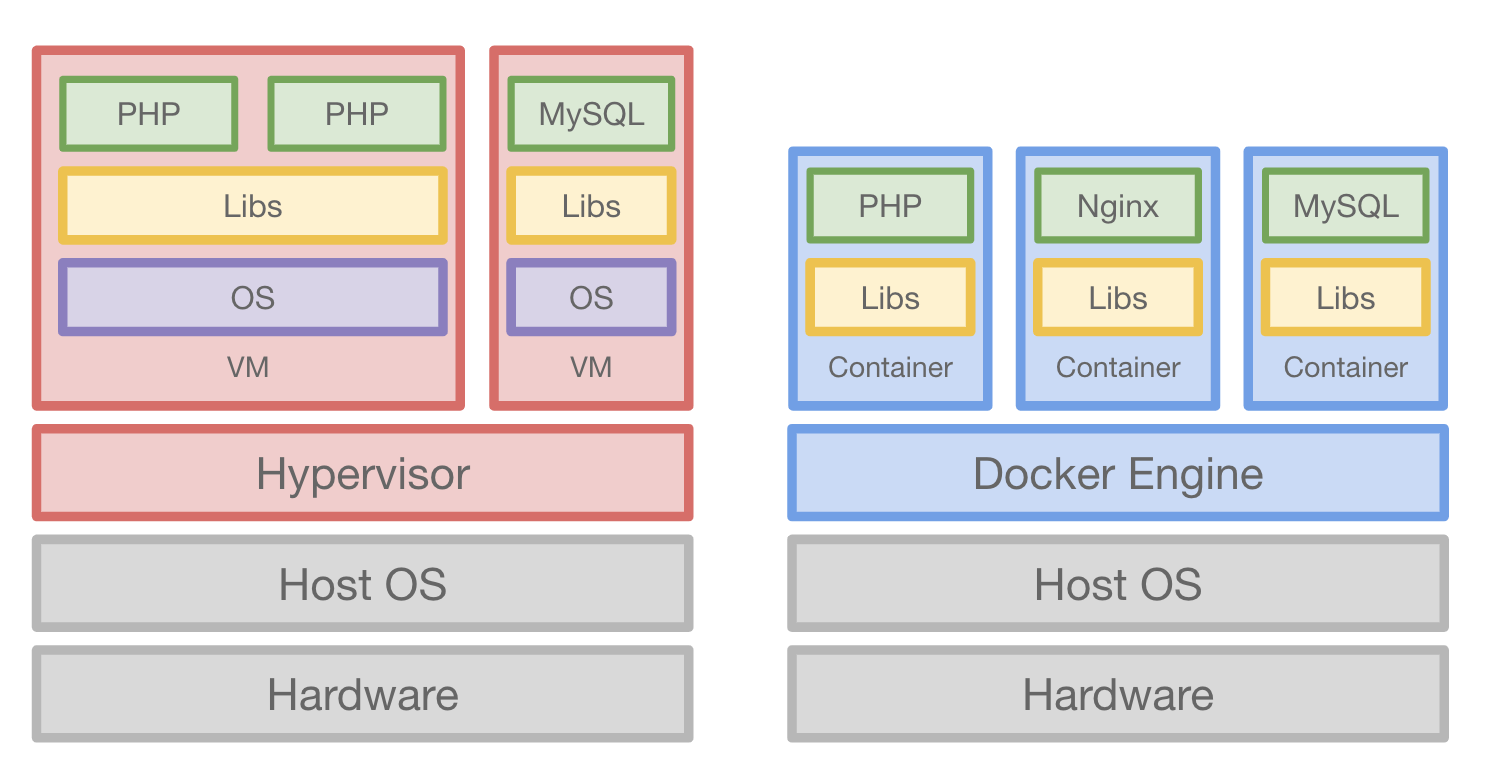
위의 문제로 인해 다음에 고려된 것이 바로 VM(Virtual Machine)이다. VM을 사용하면 하나의 서버에 여러 개의 OS를 얹어서 격리가 필요한 각 각의 서비스를 각 각의 OS에 설치하면 된다.
이렇게 관리하면 좋은 점이 snapshot 기능으로 현재 서버의 상태를 저장할 수도 있다는 장점이 있다.(하지만, 용량이 엄청 크고, 이미지 공유가 어렵다.)
하지만 서버를 처음부터 다시 셋팅하려면, 기존에 서버를 구축했던 사람을 통하지 않으면 어려웠고, 많이 느리다는 단점을 가지고있었다.
위의 VM으로 Hypervisor위에 Client OS를 얹고 그 위에 서비스 프로그램을 얹어서 사용하는 방식도 결국에는 하나의 OS의 자원을 각 각의 Client OS로 격리시켜서 사용하지만, 서버에 부하를 많이 주는 방식이기 때문에, Linux의 Kernal을 활용해서 직접적으로 각 각의 프로세스를 기준으로 사용하는 자원을 격리하도록 하는 고급 기술이 등장하였다. 이 기술의 등장으로 서버에서 동작하는 각 각의 프로세스를 가상으로 분리하고, 파일 및 디렉토리도 분리를 할 수 있게 되었고, CPU와 메모리, 입/출력 또한 각 각의 그룹별로 구분을 할 수 있게 되었다. (리눅스 기능을 활용한 빠르고효율적인 서버관리)
하지만 너무 고급 기술이며, 일부 소수의 고급 엔지니어들만 가능한 기술로, 기술 사용에 있어 많은 어려움이 있었다.
위의 고급 기술을 고급 엔지니어가 아니어도 사용할 수 있도록 나온 것이 바로 Docker라는 Container 기반의 오픈소스 가상화 플랫폼이다. 위의 고급 기술과 같이 리눅스 커널을 여러 기술을 활용하여 구현하였고, 하드웨어 상에서의 가상화 기술보다 훨씬 가볍고, 이미지 단위로 각 프로세스의 실행환경을 구성하기 때문에 사용하기 쉽다는 장점을 가지고 있다.
Docker의 장점
우선 확장성(Scalability)과 이식성(Portability)이 높다는 장점이 있다.
도커가 설치되어있는 서버라면, 어디서든 컨테이너를 실행할 수 있으며, 오픈소스이기 때문에 특정 회사나 서비스에 종속적이지 않다.
그리고 쉽게 개발 서버를 만들 수 있고, 테스트 서버 생성에도 매우 편리하다.
또한 표준성으로 각 각의 배포 방식이 다른 서비스들을 컨테이너라는 표준으로 배포하기 때문에 모든 서비스들의 배포과정이 통일된다.($docker-compose up 명령으로 컨테이너 서비스를 올릴 수 있다)
Docker의 특징
- 도커는 이미지에서 컨테이너를 생성하기 때문에
반드시 이미지를 만드는 과정이 요구된다. (Dockerfile을 이용하여 이미지를 생성/처음 배포상태부터 재현가능) 빌드 서버에서 이미지를 만들고, 만들어진 이미지를이미지 저장소에 저장하고운영 서버에서 이미지를 호출해서 사용할 수 있다.
도커의 설정은 환경변수로 제어를 하며, 환경변수 제어를 통해 컨테이너를 통해 구동되는 서비스의 환경설정을 할 수 있다.(MYSQL_PASS=password)
하나의 이미지가 환경변수에 따라 동적으로 설정 파일이 생성된다.
도커 컨테이너의 자원은 컨테이너가 삭제되면 모든 데이터가 초기화된다. 따라서
업로드하는 파일을 외부 스토리지와 링크하여 사용하거나 AWS의 S3와 같은 별도의 저장소에 저장하여 사용한다.또한
세션이나 캐시를 memcached나 redis와 같은 외부로 분리하여 사용한다.
Kubernetes의 특징
Kubernetes는 여러 서버와 여러 서비스를 관리하기 쉽도록 해준다.
그 중 첫 번째로 "스케줄링"기능이 있는데, 만약에 서버들 중에 놀고 있는 자원이 있다면 적절한 서버를 선택해서 배포를 해 줄 수 있다.
컨테이너 갯 수가 많다면, 적절히 나눠서 배포를 해주고, 실행중인 서버가 죽으면, 실행 중이던 컨테이너를 다른 서버로 띄워 줄 수 있도록 한다.
여기서도 대용량의 데이터를 각 각의 노드로 분산시켜서 분산저장,분할처리해주는 클러스터링 방식을 사용하고 있다. 클러스터 내에 여러 서버 노드들이 존재하고, 도커의 컨테이너들을 클러스터 내의 각 각의 서버들에 띄워주는 것이다.
클러스터링 형태로 사용하게 되면, 여러대의 서버들을 마치 하나의 서버처럼 관리하여 사용할 수 있으며, 여기 저기 흩어져있는 컨테이너들도 가상 네트워크를 통해서 마치 같은 서버에 있는 것처럼 쉽게 통신할 수 있다.
만약 특정 서버에서 동작하고 있는 MySQL서비스 컨테이너를 클러스터 내의 다른 서버에서 동작하고 있는 PHP 서버관련 컨테이너와 Mapping시켜주기 위해서는 어떻게 해야 될까?
Kubernetes에서는 이러한 서비스 디스커버리 기능도 제공을 한다.
클러스터 환경에서 특정 컨테이너가 어느 노드(서버)에서 실행중인지 알 수 있으며, 이러한 정보(컨테이너 생성/중지시, IP 및 Port 정보를 업데이트)는 Key-Value 스토리지에 저장이 되며, 내부 DNS 서버를 이용할 수 있다. (IP가 아닌 Docker container의 이름으로 해당 서비스를 실행하고 있는 서버를 찾을 수 있도록 할 수 있다)