
이번 포스팅에서는 5월 29일날 오프라인 강의로 수강하였던 데이터 파이프라인 구축과 관련된 수업내용에서 대해서 정리해보려고 한다. 3시간 동안의 수업을 듣고 나서 느끼고 배웠던 점이 많았기 때문에 기대 이상의 수업이었던 것 같다.
사실 이전에 인터넷 강의로 관련 강의를 수강하였기 때문에 데이터 파이프라인을 AWS 클라우드 환경에서 구축하는 부분에 대해서는 약간의 배경지식을 가진 상태였다.
그래서 아마 오늘 이 오프라인 수업 시간이 더욱 유익하게 느껴졌는지도 모른다. 이번 수업을 통해 기존에 내가 잘 못 알고 있던 기본 개념과 단편적으로만 알고 있던 데이터 파이프라인 컴포넌트들에 대해서 좀 더 구체적으로 알게 되었던 것 같다. 그리고 가장 좋았던 점은 앞으로 어떤식으로 추가적으로 학습을 하면 좋은지에 대해서 강사님이 방향 제시를 해주신 부분이 좋았다.
그러면 이번 포스팅에서는 배웠던 이론적인 부분과 내가 잘 못 알고 있었던 부분, 그리고 앞으로 추가적으로 학습할 내용에 대해서 정리를 해보겠다.
데이터 엔지니어링 vs BE/FE
데이터 엔지니어링 분야는 FE/BE 분야와는 다르게 정확히 정해진 F/W가 없다. 다만 빅데이터 아키텍처가 존재하며, Lambda Architecture와 Kappa Architecture, 두 아키텍처가 있다. 이 두 아키텍처에 대해서는 아래에서 정리를 해보겠다.
Big Data의 3V
학문적인 자료에서의 빅데이터 정의 = 3V
- Volume(용량) : TB, PB 수준의 대용량 데이터
- Variety(다양성) : 데이터 내의 속성이 다양해짐 (성별 외에도 취향 등의 다양한 속성들을 갖는다)
- Velocity(속도) : 다양한 데이터들이 엄청난 속도로 쏟아지는 것
- Veracity(정확성, 진실성) : 과거에는 통계적 관점에서 데이터를 분석했기 때문에 정확성에 대한 고려가 안되었으나, 최근에는 정확(좀 더 데이터의 세부적인 조건에 맞는 데이터)하고 신뢰성이 있어야 한다.
내가 서비스하는 플랫폼의 사용자로에게 좀 더 편리함을 제공해주기 위해서 데이터 기반으로 의사결정 및 추천을 하고, 이러한 의사결정 및 추천을 위해서 가치있는 데이터를 뽑아내는 것이 바로 데이터 엔지니어의 역할이다.
수업시간에 강사님이 소개해주신 넷플릭스 오리지널 시리즈의 “거대한 해킹(The Great Hack)”에 나오는 말이라는데, 인상깊어서 글을 남겨본다.
"우리의 온라인 활동에서 나오는 데이터가 그냥 사라지진 않는다. 우리의 디지털 흔적들을 모으고 분석하면 매년 1조 달러 규모의 사업이 된다."
이전에 데이터가 제2의 석유라는 말을 들은 적이 있는데, 정말 데이터들이 엄청난 가치를 창출해내는 요즘 데이터 엔지니어 분야는 정말 매력적인 것 같다.
(데이터 기반의 의사결정)
데이터 기반 테크 기업
(1) snowflake : DW 데이터를 효율적으로 적재하고, 적재적소에 빼서 사용할 수 있도록 하는 솔루션 제공
(2) Xplenty / iTechArt / AdTech : 광고 관련 서비스를 하는 기업으로, 데이터를 기반으로 한 광고 추천
(3) Cloudera : Hadoop 빅데이터 서비스를 상용서비스로 제공해주는 업체
(이전에 Hortonworks로 실습을 했을 때 Cloudera에 합병되었다는 이야기를 들었다)
(4) databricks : 아파치 스파크를 유지보수하고 솔루션을 만드는 업체
(5) elastic : Elasticsearch를 만든 업체 (유지보수, Saas형 클라우드 서비스 제공)
(6) TREASURE DATA
(7) teradata
데이터만 다루는 큰 규모의 회사들이 많이 생겨난다. 그리고 많은 기업들이 데이터를 이용해서 문제를 해결해나가려고 한다.
수업시간에 배우게 될 내용
이번 오프라인 수업에서는 아래의 내용들에 대해서 학습하게 될 예정이다.
- 데이터 엔지니어링 개요 / 데이터 파이프라인
- 데이터 수집기 (Logstash, Filebeat, Fluentd)
- AWS (S3, Athena, Kinesis, Glue, Lambda 등)
- Elasticsearch / Kafka (BE 영역에서도 많이 사용된다)
- Apache Flink (Batch processing + Stream processing /
Python으로 코딩 할 수 있는 인터페이스를 제공) - Apache Spark (관련 AWS 서비스를 활용해서 수업)
데이터 엔지니어링 ?
- 데이터를 수집, 저장, 처리하기 위한 시스템을 구축 및 운영
- 데이터 파이프라인을 개발/구축/운영
- 전통적인 관점에서의 ETL(Extract/Transform/Load) 작업을 수행
- 빅데이터 시스템을 유지보수/관리하기 위함
- 데이터 플랫폼을 개발 및 운영(기업에 맞게 기존 서비스들을 커스텀해서 개발)
데이터 엔지니어를 위한 공부
반복되는 작업에 대해서는 직접 API로 개발을 해서 자동화를 해야한다. 그리고 실시간으로 대량의 데이터를 처리하는 곳에서는 gRPC를 도입하는 경우도 많다. (
gRPC 개별적으로 공부하기)좋은 데이터 엔지니어가 되기 위해서는 프로그래밍을 잘 할 줄 알아야 한다.
- Scala로 개발된 Spark(빅데이터를 분석하기 위해 사용)도 Python으로 제공
- Flink 실시간 처리 플랫폼에서 Python으로 코딩할 수 있는 인터페이스를 제공한다.
SQL 지식
데이터베이스에 대한 지식이 필요하다.
OLTP(On-Line Transaction Processing: MySQL과 같은 RDB에서 트랜젝션 처리 ,OLAP(On-Line Analytical Processing): 온라인 기반 분석을 위한 DBElasticsearch / MongoDB
Data warehouses : Snowflake
Object storage : AWS S3
Cluster computing 기본 : Hadoop, HDFS, MapReduce, Amazon EMR
Data processing에 대한 지식 : Hybrid(Apache Flink), Streaming(Apache Kafka, Amazon Kinesis)
Workflow scheduling, Monitoring data pipeline에 대한 지식
Container / Orchestration 툴 : Docker, Kubernetes, Apache Mesos
데이터 파이프라인
- 데이터를 순차적으로 전달하는 시스템 (
출력이 다음 단계의 입력으로 이어지는 구조) - 요청된 데이터를 특정 Platform을 통해서 제공하는 것을 Pipeline이라고 한다. (직접 데이터를 추출해서 전달하는 것은 Pipeline의 특성으로 보기 어렵다)
- ETL 작업들을 데이터 파이프라인이라고 한다.
- 수집된 데이터를 정해진 시간 텀으로 처리를 해야되는 경우, 스케쥴러를 사용한다. (
현업에서는 Airflow를 가장 많이 사용한다)
-> Airflow는 복잡한 구조의 스케줄링을 할 때 사용된다. (개인적으로 Apache Airflow를 학습할 것을 권장) - 데이터 엔지니어의 전체 업무 프로세싱이 원유를 시추해서 가공하는 과정과 유사하다.
데이터 간섭/속도를 최적화하기 위한 처리를 소프트웨어적으로 처리하는 것을 데이터 엔지니어가 담당한다.
ETL : 전통적인 데이터 파이프라인
- 과거에는 기존 RDS에서 데이터를 추출해서 분석을 했기 때문에 ETL이라는 용어가 사용되었다. 추출된 데이터를 정제해서 새로운 분석용 DB를 생성해내는 일련의 과정을 ETL이라고 한다.
- 데이터 기반이 아닌 초기 스타트업 같은 경우에는 정재된 데이터가 없기 때문에 데이터 엔지니어의 업무가 필요가 없는 경우가 많다.
- ETL 작업이란 큰 범주로 보면, 복수의 DB를 일괄적으로 모아서 Data Warehouse를 구성하고 그 데이터를 Data Mart로 다시 구성하는 각 각의 중간 과정을 ETL 작업이라고 한다. (
다층구조로 설계)
ETL과 ELT
수집 - 처리 - 저장 - 분석 - 시각화 과정에서 처리 - 저장 순의 경우에는 ETL, 저장 - 처리 순의 경우에는 ELT(일단은 쌓아놓고 처리 - 빅데이터 처리 컨셉)라고 한다.
스케줄러
스케줄러는 데이터를 처리하는 일련의 과정을 특정 시간 주기로 합계, 평균을 구하거나 지난 데이터를 가져와야되는 경우에 사용된다. Airflow는 복잡한 스케줄링을 사용하는 경우에 사용된다. 간단한 스케줄링 작업의 경우에는 Amazon EventBridge를 사용한다.
원유 시추 과정 = 데이터 파이프라인 과정
(1) 유전에서 원유 채취 : Device/DB로부터 데이터를 채취
(2) 선박으로 운반 : Kafka
(3) 원유 탱크에서 저장 : S3나 HDFS에 저장
(4) 석유 정제(정유정제) : 저장된 데이터를 정제/가공해서 정보(쓸만한 insight)를 뽑아내는 과정
앞으로 개인적으로 공부하면 좋은 것
- OLTP / OLAP
- Beam : 여러 언어와 Runner를 제공하고, 각 서비스들을 proxy해주는 역할을 한다. 순서상
Flink나 Spark를 우선적으로 학습하고, Flink와 Spark 배경지식을 기반으로, 나중에 학습하는 것을 권장
ref. 찾아보니깐 Beam은 데이터 프로세싱 파이프라인을 개발할 때 유용한 환경을 제공해주는통합 프로그래밍 모델이다.
빔에서는 다양한 언어들과 러너를 제공하고 있으며, Flink가 제공되는 여러 러너 중에 하나이다. - BigQuery의 사용으로 인해서 AWS -> GCP로 넘어가는 경우가 많다. (ML을 많이 하는 경우가 많다)
-> BigQuery가 데이터 웨어하우스 분석시에 많이 사용되기 때문에 우선적으로 BigQuery를 학습하고 나중에 GCP를 학습하는 것이 좋다.
대표적인 빅데이터 아키텍처
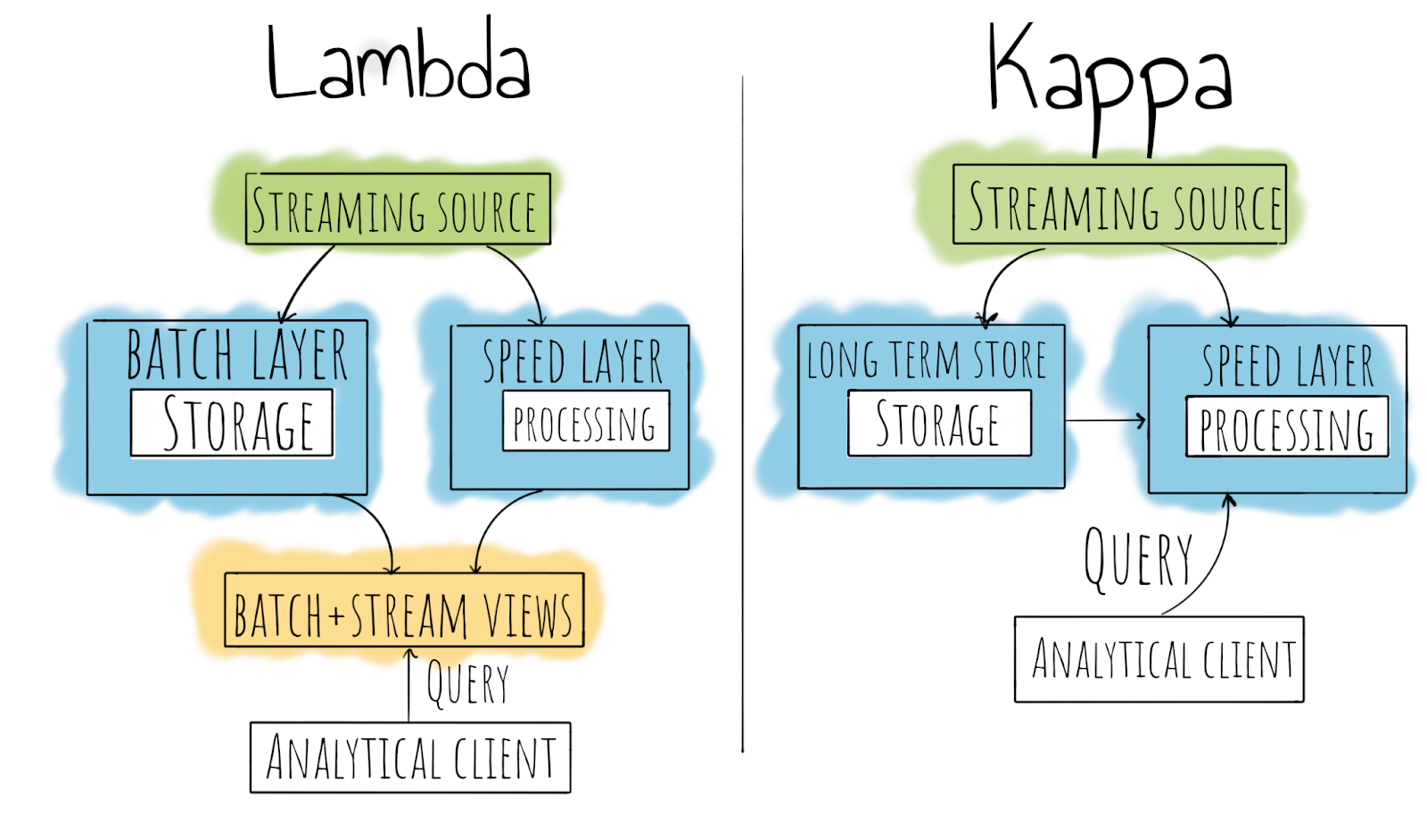
빅데이터 아키텍처 (1)Lambda Architecture
Batch processing: 데이터를 특정 시간동안 모아서 처리하는 방식(민첩성이 떨어진다)으로, 대부분의 업무처리가 이 배치 처리방식으로 처리된다. 그리고 배치처리는 영속성이라는 특성을 가진다. (이미 클러스터에 데이터를 저장하고 있기 때문에 사후 분석이 가능한 형태이다)Stream processing:건 바이 건으로 들어오는 데이터를 즉시 처리하는 방식으로, 실시간 데이터셋을 처리해야되는 경우 유용하다.
실시간으로 matching 시켜야되는 데이터 처리를 할 때 많이 사용되며, Queue에 저장된 데이터를 개별적인 공간에 저장을 해서 데이터의 영속성이라는 특성을 갖게 할 수는 있다.네트워크 문제로 데이터의 loss가 발생(Unbounded data processing)할 수 있지만, 최근 기술로는 데이터의 loss가 생기지 않는다.그래서 과거에는 대략적인 결과를 얻기위한 목적으로 사용되었다.(Approximate result)
그리고 과거의 데이터나 재처리를 크게 고려하지 않는다는 특징을 가지고 있다.
또한 네트워크 issue로 인해 Stream processing을 통해 유입된 데이터가 예상된 순차적 데이터로 처리되지 않는 경우도 있다.(배치처리보다 정확도가 떨어진다 - 이전 기술상의 문제)위의 issue를 통해서 나온 아키텍처가
람다 아키텍처(Lambda Architecture)이다.
람다 아키텍처는 Twitter의 Nathan Marz에 의해 처음 고안되었고, 과거에는스트림 처리에 대한 지식이 부족했기 때문에 데이터 유실의 문제가 많았고, 배치처리에서는 데이터가 다 쌓인 뒤에 일괄적으로 처리하기 때문에,결과를 보기 위해서는 모든 데이터가 처리된 이후에 가능했다. 이런 각 각의 Processing상의 문제들을 보완하기 위해 나온 아키텍처가 람다 아키텍처이다.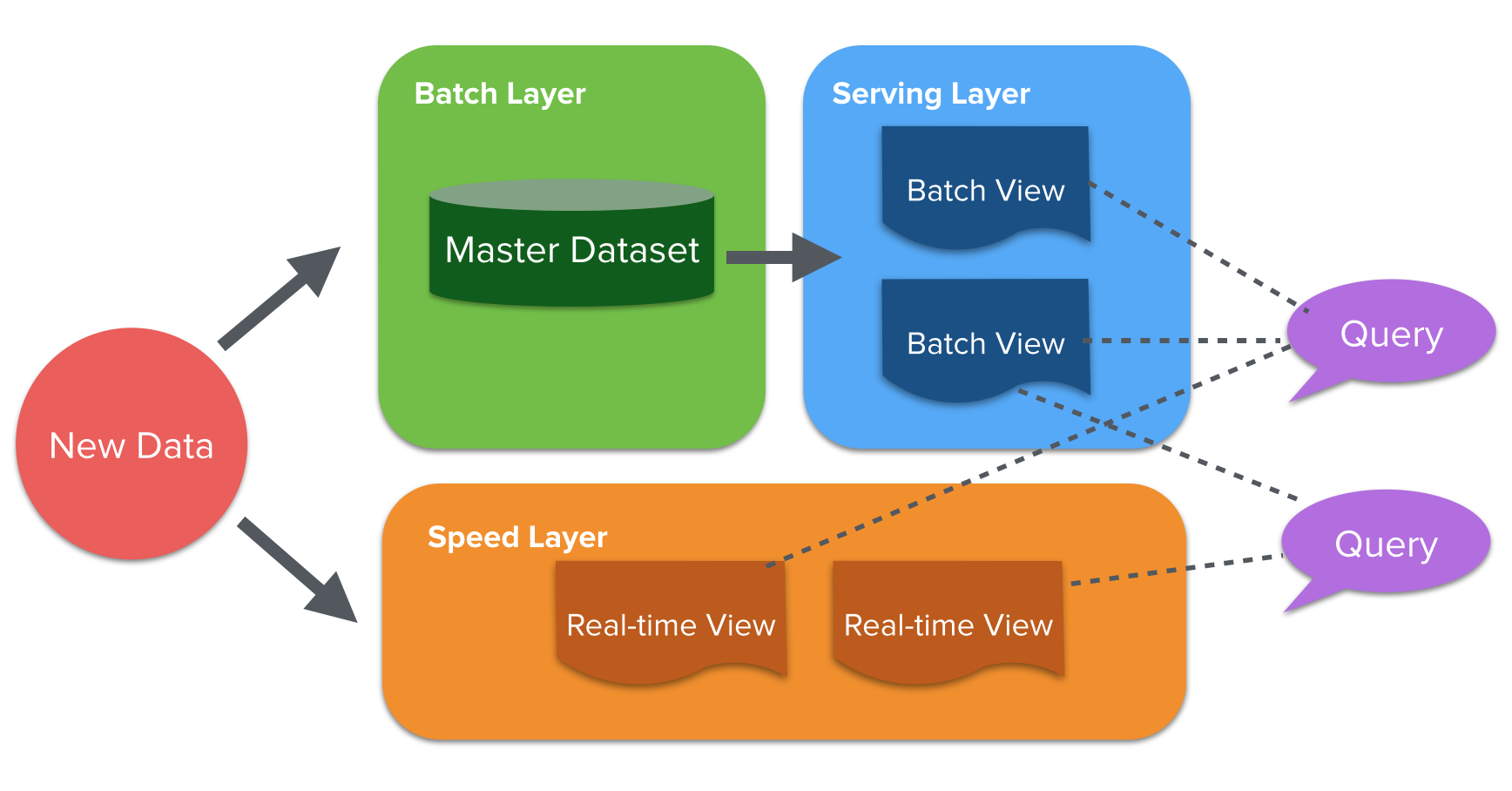
배치 레이어(Batch Layer) : 과거 데이터를 장기 저장소에 축적하여 여러 번 다시 집계할 수 있다.(
재처리 가능), 대용량 데이터를 처리하지만 1회 처리에 오래 걸린다.서빙 레이어(Serving Layer) : 정기적으로 데이터가 업데이트되어 정보를 출력한다. (단, 실시간 정보는 아니다)
배치 레이어의 경우에는 서빙 레이어에 별도의 DB를 위치하기도 한다. (DW/DM)스피드 레이어(Speed Layer) : 스트림 데이터를 처리하며, 데이터 보관 기간이 짧1아서 일정 기간이 지난 데이터는 삭제된다.
람다 아키텍처의 처리 과정
- 데이터 수집기를 통해 들어온 데이터는 모두 일괄적으로 배치/스피드 레이어에 공통으로 유입되게 된다.
- 배치 레이어 + 서빙 레이어 = 배치 처리의 결과를 서빙 레이어에 정기적으로 저장이 해서 결과를 출력한다.
Pros
이전에 학습했을때는 Lambda Architecture에서 각 각 개별적인 processing으로 분류되서 데이터가 처리되는지 알았는데, 이 부분은 잘 못 알고 있던 부분이었다. 람다 아키텍처는 스트림 처리와 배치 처리 작업시에 각 각의 처리가 가지고 있는 문제점을 상호 보완하는 데이터 아키텍처이다.
배치 처리의 처리시에 생길 수 있는 latency 동안에는 실시간 뷰를 사용(정확성이 다소 떨어짐)하고, 배치 뷰가 업데이트 되면 배치 처리를 사용한다.
(상호보완적 처리 과정)Cons
- 각 각의 독립되어 구성된 파이프라인을 유지/보수해야되기 때문에 효율성이 떨어진다.
- 두 파이프라인에서 나온 결과를 병합하거나 양쪽에 query를 해야 되기 때문에 번거롭다.
빅데이터 아키텍처 / (2) Kappa Architecture
람다 아키텍처상에서
배치 처리 레이어를 제거한 아키텍처를 말한다.Kafka(실시간 message queue) 개발자인
Jay Kreps에 의해 제안된 아키테처 모델이다.PC의 Performance(CPU/MEMORY 성능향상)가 좋아짐에 따라 오직 스트림으로 데이터를 처리할 수 있게 되었다.
데이터 전달이 보장됨에 따라 스트림으로 전달되는 데이터의 유실 가능성이 낮아지고, 데이터의 신뢰성이 높아졌다.
ref.데이터 전달 보장 유형에 따른 분류
at-most-once : 최대 한 번 보장(더 전달), 메시지 유실 가능성이 있음
at-least-once : 최소 한 번 보장(더 전달), 메시지 유실 가능성 없음, 중복 가능성 있음 (Kafka 지원)
exactly-once : 전달 보장, 메시지 유실 가능성 없음, 중복 가능성 없음 (Flink 지원)과거 메시지 누락에 대한 문제를 보완한 replayable(재현가능한) 메시지 브로커인 Kafka가 등장하였다.
ref,과거에 흘려보낸 스트림 데이터를 다시 흘려보낼 수 있다. (과거 TV 방송과 IP TV의 방송 다시 보기 비교 예시)실시간 데이트 앱이나 우버와 같이 사용자와 실시간으로 매칭시켜줘야되는 needs가 많아지기 때문에 중요해진 아키텍처
대표적인 스트림처리 엔진은
Kafka,Apache Flink(배치 + 실시간 스트림 처리 가능)가 있다.Pros
- 스트림 처리로만 파이프라인을 구성하기 때문에 단순화
- 두 처리 방식의 결과물을 병합처리하는데 사용되는 Computing resource가 절약
- 단일 파이프라인과 단일 뷰로 개발/운용에 효율적이다.
Cons
데이터 재처리시에 리소스가 많이 요구된다.
=> 데이터 재처리시(리소스가 많이 요구되는 case)에는 클라우드 서비스를 사용해서 instance를 임시로 띄워서 처리하고 생성한 instance를 없애는 형태로 기존 리소스의 한계를 보완하고 있다.실사간성, 빠른 바능성으로 인해 CPU 집약적인 작업(computation intensive)(
데이터를 쌓아놓고 모델링을 학습시키는 ML/DL)에는 적합하지 않을 수 있다.
단, Flink를 활용해서 실시간으로 받은 데이터를 활용해서 ML/DL을 할 수는 있다.
Cloud Service
- 확장성 : 늘어나는 데이터를 손쉽게 대응할 수 있다. (컴퓨팅 자원, 스토리지, 신규 기능)
- 효율적인 자원 활용 및 비용 효율성
- 관리형 서비스를 사용함으로써 얻게되는 이점 (개발/구축을 위한 인력의 필요성이 줄어든다)
- Compliance issue로부터 constraint되는 문제를 해결 할 수 있다. (
클라우드의 개인정보 관련 법적/제도적 이슈를 인증해서 해결할 수 있는 방법이 생겨나고 있다) - 대체 불가능한 서비스 (Bigquery, S3)
추가적으로 학습하면 좋은 것들
Docker / Kubernetes
Hadoop / Hive / Presto / Trino
Apache Spark
Airflow
AWS
IaC(Infrastructure as Code): ansible, terraform, AWS CDK, AWS CloudFormation 코드로 인프라를 관리, 구축할 수 있도록 하는 기술
CI/CD 플랫폼에 대한 지식
첫 실습(Beats + Logstash + Elasticsearch)
실습에 사용할 Beats, Logstash는 elastic이라는 기업에서 오픈소스화한 프로젝트인데, 이러한 오픈소스 프로젝트로 유명해진 기업이다.
이전에 Logstash를 통해 외부의 로그 데이터를 받고, 받은 데이터를 Kafka를 통해 Consumer instance로 흘려보내주는 일련의 과정을 실습한 적이 있다. 이때는 Logstash에 파일에 정의된 input, filter, output을 통해서 데이터를 Kafka로 넘겨주는 역할을 한다고만 알고 있었는데, Logstash의 input, filter, output에는 다양한 plugin이 존재한다.
과거에는 Logstash가 단순 collector 역할을 했지만, 최근에는 filter해주는 다양한 플러그인 기능들을 제공한다. 사용 용도에 따라 찾아서 사용해보자. Logstash에서 제공해주는 다양한 플러그인 중에 S3로 넘겨받은 데이터를 저장할 수도 있고, Kafka로 데이터를 넘겨줄 수 있도록 도와주는 플러그인도 있다. (input/output plug-in을 다양하게 사용해서 조합할 수 있다)그럼 Flink와 Kafka가 필요한 이유는 무엇인가? logstash는 단일 Agent(Single node)로 데이터의 병렬 처리가 불가능하기 때문에 Flink를 사용해서 클러스터 내의 여러 노드로 대량의 데이터를 분산시켜서 처리할 수 있다.
[다양한 input/output 조합]
file - logstash - elasticsearch
file - logstash - kafka
kafka - logstash - elasticsearch
kafka - logstash - hadoop
…
ref. Logstash Input/Filter/Output의 다양한 플러그인들
(1) Input : https://www.elastic.co/guide/en/logstash/current/input-plugins.html
(2) Filter : https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
parsing, transform도 가능하다.
(3) Output : https://www.elastic.co/guide/en/logstash/current/output-plugins.html
이번 실습에서는 Beats라는 경량 수집기를 사용한다. logstash는 데이터 파이프라인으로, 여러 소스로부터 데이터를 긁어서 여러 데이터 저장소에 저장을 할 수 있는 다양한 기능을 제공하므로, 매우 무겁다.
따라서 빠르게 데이터만 수집할 수 있는 Beats라는 경량 데이터 수집기가 등장하였다. Logstash보다는 제한된 기능을 하지만, 리소스를 적게 먹는 경량 데이터 수집기의 역할을 한다. Beats를 container에 심어서 사용하는 경우도 있다.
그럼 logstash를 사용하지 않고, beats만 사용해도 되지 않나?
Logstash와 같은 Aggregator가 존재하는 이유는 다수의 Server cluster의 노드들(beats)에 공통된 로직을 적용하기 위함이다. 또한 Storage에 복수의 connector로 연결시키게 되면, 과부하가 발생된다.(개별 노드에서 처리를 하게 되면 리소스가 그만큼 많이 소모된다.)
실습1) 구체적인 실습 과정
Logstash - Logstash도 가능한데, 실습에서는 각 서버에 beats를 설치하고, 각 beats를 Logstash에서 모아서 Store에 저장을 하는 구조로 구성을 한다.
EC2 Instance 생성하기
logstash는 java base 이기 때문에 jdk를 필수로 설치해줘야 한다.
오늘 날짜를 기준으로 file name format을 맞춰서 log파일을 생성해준다.
일반적으로 vm이나 container에서 환경에서 앱을 띄워놓고 생성된 로그정보를 local에 로그파일 형태로 떨구고, 떨궈진 로그파일을 logstash가 읽어서 처리하게 된다. 따라서 logstash에서 File을 읽는 처리는 중요하다.