
이번 포스팅에서는 인터넷에서 우연히 보게 된 현업 데이터 엔지니어의 “데이터 엔지니어가 되기 위한 준비”에 대한 영상을 보고 난 후의 후기에 대해서 작성해보려고 한다.
결과적으로는 너무 많은 도움이 되었다. 아직은 많이 부족하지만, 개인적으로 데이터 파이프라인 구축이나 Hadoop, Spark, AWS 등 데이터 엔지니어가 되기 위해 필요한 기술 스택에 대해서 공부를 해왔기 때문에 이번 영상이 나에게 많은 도움이 되었던 것 같다.
가장 많은 도움이 되었던 부분은 데이터 엔지니어라는 직무적 측면에서 지원하고자 하는 기업을 볼때 어떻게 봐야하는가였다.
데이터 엔지니어 직무로서 바라 본 기업의 업무 프로세스
이 부분은 내가 기업에 지원할때 실제 그 기업에서 어떤 데이터가 발생하는지, 그리고 그 데이터를 수집하고 관리하며, 최종적으로 데이터가 어떤식으로 활용이 되는지에 대한 이해는 필수인 것 같다는 생각을 하였다.
예를들어, A라는 기업에서 아래의 업무 프로세스를 가지고 있다고 가정하자.
[업무 프로세스]
연구 및 개발 -> 제조 -> 배송 -> 온/오프라인 판매
위의 전체 업무 프로세스를 통해 여러 데이터들이 발생할 것이다. 최종 판매 단계에서는 매일 다양한 경로로 판매가 이루어지고 있다는 것을 분석할 수도 있을 것이고, TB규모이상의 데이터가 처리될 것이다.
(위의 각 업무 프로세스상에서 발생하는 데이터들을 추출하기 위해서는 데이터 엔지니어의 필수역량인 데이터 파이프라인 구축을 해야한다.)
기업마다 업무상에서 추출 및 분석하는 데이터는 다르며, 게임회사의 경우에는 게임 플레이할 때 발생하는 로그 데이터나 게임 아이템 마켓에서 구매내역과 관련된 데이터도 있다.
이처럼 데이터를 수집(추출)하고 가공하고, 적재하는 일련의 과정을 통틀어서 ETL(Extract/Transform/Load)라고 한다. 기업은 매일 생산해내는 여러 데이터를 수집하고 관리하며 데이터가 필요한 곳에 전달해서 의사결정에 활용한다.
데이터 엔지니어 직무
데이터 엔진지어의 역할은 앞에서 언급했듯이 데이터 파이프라인을 구축하는 것인데, 데이터 유실없이 튼튼한 데이터 파이프라인을 구축하는 것이다. 뭐 데이터 그냥 엑셀파일로 저장해서 관리하면 되는 거 아닌가? 라는 생각을 가진 사람들도 있겠지만, PC 한 두 대가 아닌 클러스터 형태로 여러 노드들을 사용해서 핸들링해야되는 데이터를 다뤄야되기 때문에 이 데이터 파이프라인이 필요한 것이다.
추가적으로 회사마다 데이터 엔지니어의 업무 범위가 다르기 때문에 지원하기 전에 반드시 확인을 해야된다고 한다.
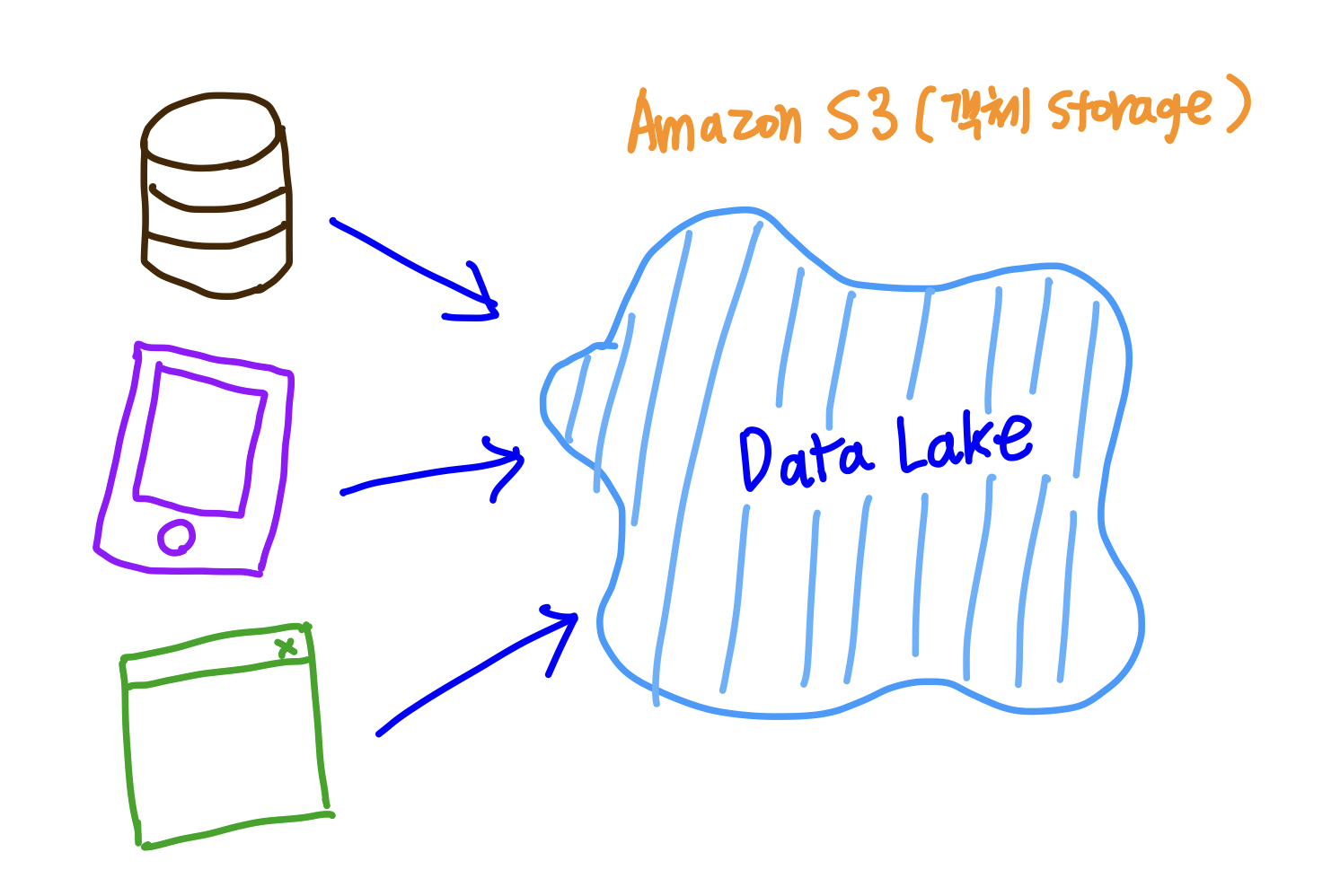
Data Lake
관계형 데이터의 경우에는 RDB에 저장을 하고, 비 관계형 데이터는 NoSQL DB에 저장하는 식으로 나눠서 따로 따로 저장하지 않고, 정형 데이터와 비정형 데이터를 한 곳에 모아서 Data Lake를 형성하게 되는데 이때 사용되는 것이 바로 AWS S3(객체 스토리지)이다.
이렇게 한 곳에 일괄적으로 모으게 되면, 분석에 용이하다.
데이터 엔지니어의 스킬셋
(1) AWS, GCP
데이터 파이프라인 구축을 클라우드 기반으로 하기 때문에 AWS나 GCP의 서비스를 활용하는 방법에 대해서 알아두는 것이 좋다.
(2) Apache Spark
Spark는 여러 컴퓨터에 대량의 데이터 처리를 나눠서 하는 분산처리 엔진이다.
(3) Kafka
Kafka는 메시징 큐로, 실시간 데이터 처리에 많이 사용이 된다.
(4) Apache Airflow
데이터가 흘러다니는 데이터 파이프라인에 x는 언제 실행이 되고, y는 x 다음에 실행이 되고, 이런 식으로 스케쥴링을 orchestration 해주는 엔진이다.
(5) Docker / Kubernetes
Docker는 Container이고, Kubernetes는 Container를 orchestration 해주는 엔진이다.
이러한 컨테이너 관련 서비스를 이용하는 이유는 앱이 모두 동일한 환경에서 작동하는 것을 보장하고, 같은 환경을 배포하도록 하기 위해서이다.(6) Hadoop
Hadoop은 분산 컴퓨팅 에코 시스템이다.
(7) ELK Stack
여러 데이터 관련 툴을 제공하는 Stack이다.
(8) SQL
데이터베이스에 접근해서 데이터를 저장하고 호출하거나, 수정하고 삭제하는데 사용되는 구조화된 질의 언어이다.
아직 위의 기술셋 중에서 Docker/Kubernetes, Apache Airflow는 아예 해보지도 못했는데, 지금 하고 있는 공부를 하면서 한 번 배워봐야겠다.
그런데 유행하는 기술이나 다양한 기술셋들은 빠르게 변한다. 따라서 아래의 항목들에 대해서 유의해서 학습하면 좋다고 한다.
(1) 필요한 기술을 빨리 습득하고, 업무에 사용할 수 있는 능력(2) 분산 컴퓨팅, 컨테이너 기술에 대한 이해(3) 하나의 언어와 SQL 능력 필요
어쩌면 지금 단기간에 여러가지 기술들을 스스로 배우고 정리하고, 반복학습을 하면서 내것으로 만드는 과정이 나중에 실무에서 새로운 기술을 만났을때 스스로 찾아서 공부하고 내것으로 만들 수 있는 좋은 습관으로 자리잡을 수 있도록 열심히 노력해야겠다.
가장 먼저 해야되는 일
- 내 활동과 스펙들을 쭉 정리를 해보자.
- 채용공고들을 쏵 훑어보자.
- 나에게 맞는 포지션을 고른다.
포트폴리오 준비
포트폴리오의 주된 목적은 내 스킬셋을 보여주기 위한 것이다. 구구절절 적지 말고, 한 눈에 잘 들어올 수 있도록 작성하도록 하자. (
포트폴리오는 선택이 아닌 필수)PDF나 URL로 준비를 해서 제약 없이 어디서든 접속해서 볼 수 있는 형식으로 제출하자.
코딩 테스트
- 문제를 푸는 것 이상으로 효율적이고 좋은 코드를 내 것으로 만들기
- 내가 한 번 풀어보고, 좋은 풀이 보기
- 하다보면 실력이 생긴다! 여러 사이트를 통해서 다양한 플랫폼을 경험해보는 것이 중요!
(Leetcode, HackerRank, Programmers(프로그래머스 문제에서 고득점 kit을 풀 수 있으면 탑티어 기업을 제외한 기업들의 코테를 어느정도 통과할 수 있다))
면접
- 개발자 성향 (습득이 빠르고, 새로운 기술에 대한 호기심)
- 협업 경험
- 면접 태도에서 보여지는 커뮤니케이션 능력
- 기술 능력
- 이력서에 ~ 는 써 봤는데 어느 정도로 사용해보셨나요? (
버전, 어느정도 설정까지 해봤는지에 대해 설명할 수 있어야 한다) - 이슈, 장애상황에 대한 설명 (어떻게 문제상황을 대처했는지에 대한 설명을 할줄 알아야함)
- 구글링을 통해
개발자 기술 면접 질문 리스트,데이터 엔지니어 면접 질문 리스트뽑아서 연습하기 - 최대한 많은 질문들을 뽑아서 한 번씩 생각해보고 가기(1분 자기소개도 준비해가기)
- 여러 면접 팁 관련 영상자료 많이 보고 가기(실제로 많이 도움이 된다) - 자투리시간 활용해서 시청하기
- 편안하게 내가 노력한 것들에 대해서 보여주기
- 이력서에 ~ 는 써 봤는데 어느 정도로 사용해보셨나요? (
반드시 준비해야되는 것들
- 내가 개발자 성향인지 보여줄 수 있는 것
- 커뮤니케이션 능력, 프로그래밍 실력
- 포트폴리오를 통해서 내가 지원한 직무에서 얼마나 적합한 사람인지 보여줄 수 있어야 한다.
취득하면 좋은 자격증
- AWS 클라우드 자격증
- 쿠버네티스 자격증
마지막으로 정리
- 채용공고 상시보기
- 내 자신을 스스로 평가하지 말고, 서류를 직접 제출하고 결과로써 평가받기
- 목표는 포트폴리오를 채우기!