이번 포스팅에서는 말로만 들어왔던 ElasticSearch에 대해서 학습한 내용에 대해서 정리하고, 실습한 내용을 정리해보려고 한다.
실습내용
이전에 실습으로 EC2 인스턴스 3개를 두고, Producer에서 Logstash를 통해서 Twitter의 로그를 가져다가 Kafka(이하 메시지 큐)에 쌓았다가 Consumer로 넘겨주는 흐름으로해서 실습한 적이 있었다.
이번 실습에서는 Amazon S3에 있는 데이터 정보를 LogStash(EC2)에서 뽑아서 Amazon OpenSearch Service(ElasticSearch)로 넘겨주고, 이를 Kibana라는 시각화 툴로 시각화까지 시켜주는 부분까지 실습을 해보려고 한다.
(Amazon S3 ->(Logstash(EC2))->Amazon OpenSearch Service -> Kibana)
Amazon Kinesis Firehose -> Amazon OpenSearch Service(ElasticSearch)로 Direct로 데이터를 넣어줄 수 있다.
(2022/05/01 업데이트)
Amazon OpenSearch Service(ElasticSearch) 설정 및 실습준비
create domain
(1)도메인 이름: class(2)배포 타입: 개발 및 테스트(3)인스턴스 타입: t3.medium.search(4)네트워크 : Public Access (실습이기 때문에)(5)세분화된 액세스 제어(6)마스터 사용자 생성 - 계정정보 입력(7)액세스 정책 : 세분화된 액세스 제어만 사용(어디에서든 접속 가능하도록 설정)(8)고급 클러스터 설정 - 최대 절 수: 1,024
(생성시간은 대략 10분정도 소요)
Logstash를 위한 EC2 인스턴스 생성
(1) 인스턴스 타입: t3-medium[태그 추가]
(2) Key: Name / Value: elasticsearch-logstash
EC2 인스턴스에 필요한 환경 구성하기
[Open JDK 설치 및 logstash 설치]
1 | $sudo yum install -y java-1.8.0-openjdk-devel.x86_64 |
실습 순서
STEP1 : [ElasticSearch에 쏴줄 데이터 준비하기]
EMR에서 Zeppelin notebook을 통해서 이전에 Text형태의 파일을 JSON 파일로 convert해서 ElasticSearch로 쏴줄 데이터를 준비할 것이다.
Logstash에서 ElasticSearch로 데이터를 전달할때 to_timestamp형태가 timestamp 타입의 데이터 형태여야 시계열 형태로 그래프를 그릴 수 있다.
1 | // 이전시간에 연습했던 것처럼 아래의 spark 코드로 지정한 S3 Bucket 위치에 SQL query 결과 데이터를 JSON 형태로 저장을 한다. |
STEP2 : Elastic Search 활용하기
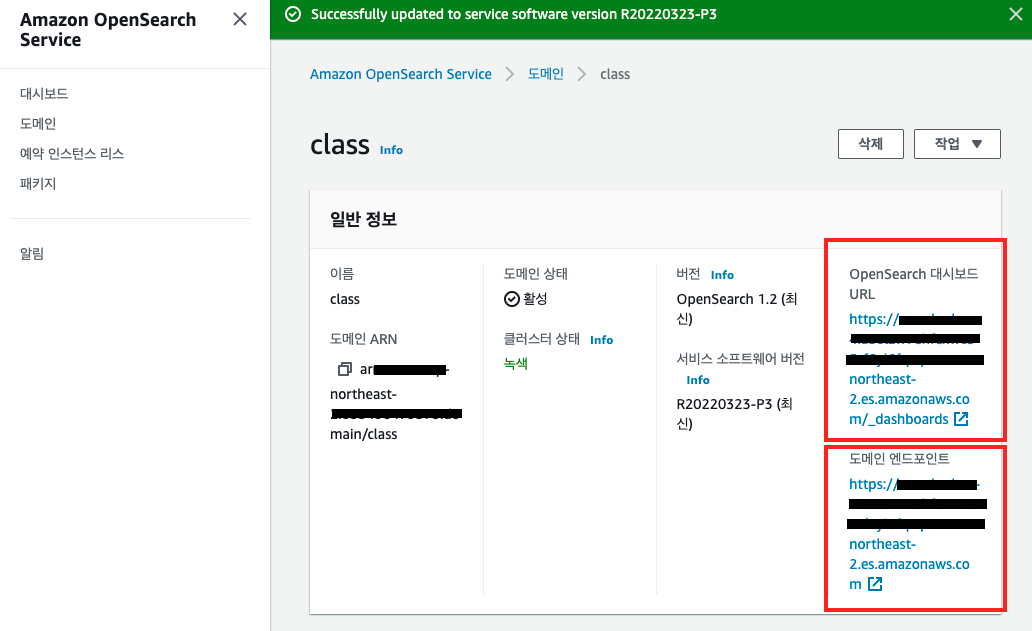
위의 OpenSearch 대시보드 URL은 Kibana로 로그인/접속하기 위한 URL이며, 도메인 엔드포인트는 프로그램에서 데이터를 뿌려주기 위해 사용되는 엔드포인트이다.
Kibana?
Kibana란 ElasticSearch 데이터를 시각화하고 Elastic Stack을 탐색하게 해주는 무료 오픈 소스 인터페이스이다.
쿼리작업량 추적부터 앱을 통한 요청 흐름 방식에 대한 파악까지 다양한 것들을 시도해볼 수 있고 한다.
STEP3 : [Logstash에서 S3에 저장된 데이터를 뽑아서 ElasticSearch에 던져줄 수 있도록 config 파일 작성]
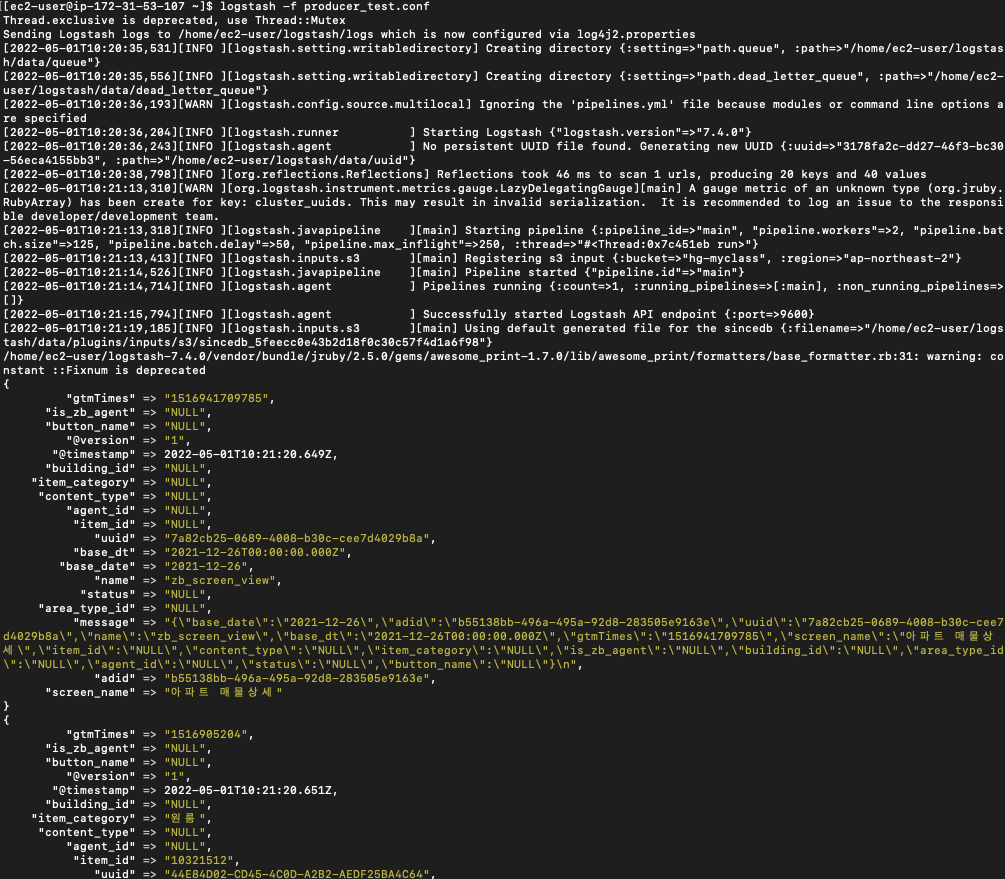
우선 S3에 있는 데이터를 일괄적으로 ElasticSearch에 던지기 전에 우선적으로 간단하게 message를 주고 받는 것을 확인하는 형태로 테스트용 producer_test.conf 파일을 작성한다.
1 | input { |
CLI에서는 S3 bucket에 있는 데이터를 읽을때에는 access key나 secret key 없이도 서비스별로 권한을 부여하여 데이터에 접근할 수 있었다. 하지만 위의 경우는 어플리케이션 레벨에서 S3 bucket에 접근을 하는 것이기 때문에 위와같이 access_key_id와 secret_access_key에 대해서 정의를 해줘야한다.prefix는 데이터를 가져올 대상 폴더의 경로를 의미하며, filter에서는 가져온 json 데이터를 처리하는 부분을 담당한다.
producer.conf
1 | input { |
output의 index 부분은 partitioning과 동일한 부분으로, ElasticSearch는 데이터를 많이 가져가면 비효율적인 부분이라고 이전에 학습을 했었다. 그래서 2주에서 최대 1달정도의 기간동안의 데이터를 취합해서 분석할때 유용하다고 했다.
index에서 이름에 기간을 넣어서 유동적으로 표시를 한 이유는 나중에 특정 기간 이전의 데이터를 삭제할때 조건처리로 할 수 있기 때문에 위와같이 기간을 index명에 포함을 시켰다.
logstash에는 다양한 기능이 있는데, filter에서 mutate는 그 중 하나의 기능으로, 분석에 필요하지 않는 column이 있는 경우, script에서 간단하게 column 명을 넣어서 해당 column을 삭제처리할 수 있다.
STEP4 : [Kibana에서 데이터 확인하기]
지정해준 ElasticSearch domain endpoin에 데이터를 보냈다면, Kibana에서 해당 데이터를 확인할 수 있다.
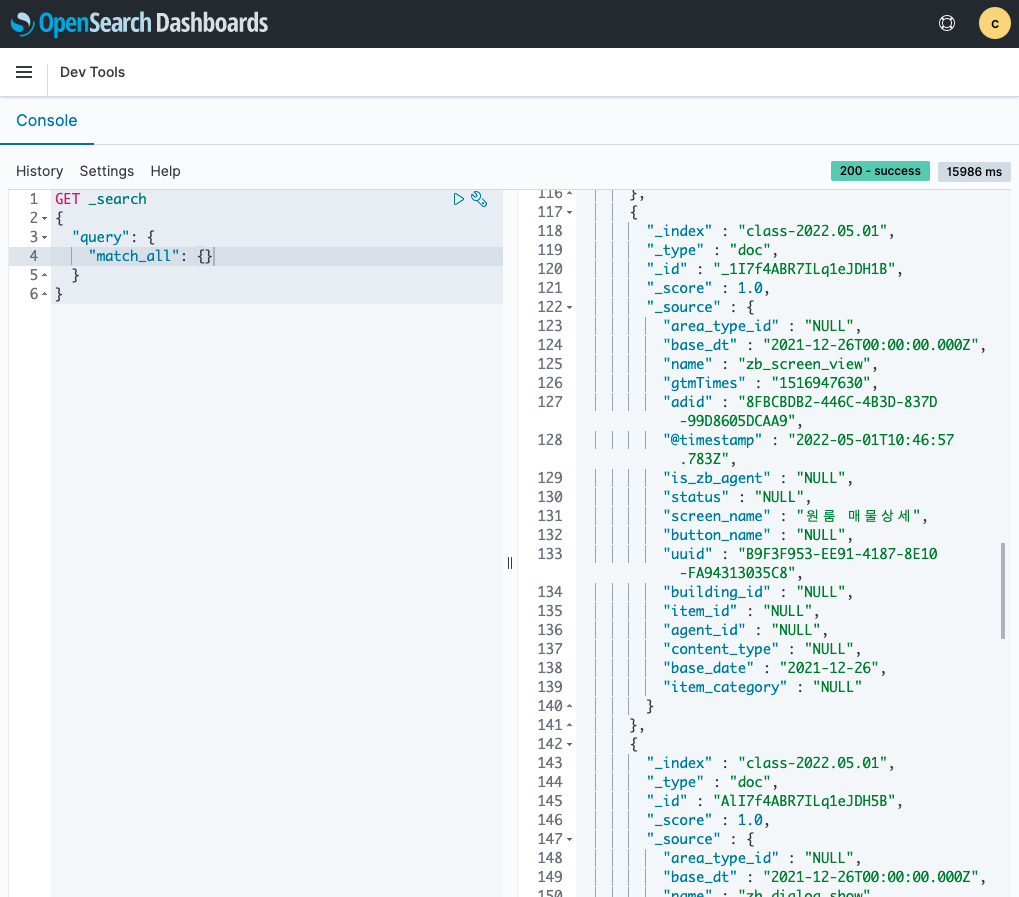
햄버거 버튼에서 Management - Dev Tools 메뉴를 클릭하면, query를 날려서 현재 데이터를 확인할 수 있는데,
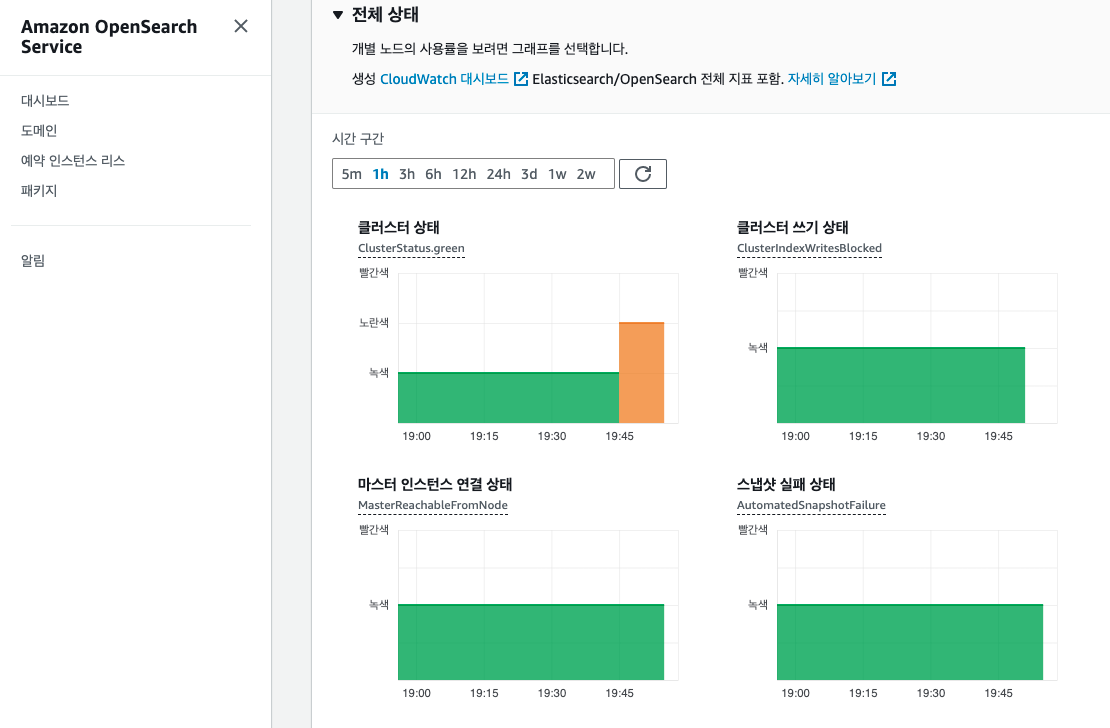
Amazon OpenSearch Service의 Domain에서 클러스터 상태 메뉴에 들어가면, 클러스터 상태를 확인할 수 있는데, 상태에 따라서 클러스터의 노드를 늘려주거나 디스크를 확장해서 해결해 줄 수 있다.
Tip : 외부에서 발생하는 데이터를 API Gateway를 통해서 Kinesis stream -> Kinesis firehose -> S3의 형태로 외부 데이터가 수집되어 분석되는 것을 이전에 실습을 해보았는데, 이 경우에는 ElasticSearch에서 데이터를 수집했을때와 비교하면 느리다.
따라서 좀 더 빠르게 새로 런칭한 신규 서비스의 사용자 이용추이 데이터를 분석할때에는 이번 포스팅에서 다룬 ElasticSearch가 활용하기에 좋다.
STEP4 : [들어오는 데이터에 인덱싱해주기]
OpenSearchDashboard에서 햄버거 버튼을 클릭하고, Management -> Stack Management를 클릭 -> Index Pattern 안에 생성된 data object를 확인할 수 있다.
이것을 분석할 수 있는 하나의 테이블 뷰 형태로 만들어주면 된다.Index pattern name : class* -> NEXT -> (시간 기준 데이터 Time field 선택) 우측 상단의 별을 클릭하면 default index로 사용을 할 수 있다.
이제 햄버거 버튼 클릭후 OpenSearch Dashboards - Discover를 클릭하면, 상단에 필터된 기간에 맞게 그래프에 데이터가 출력이 된다. 세부 데이터 관련 내용은 하단에 세부 항목으로 확인을 할 수 있다.
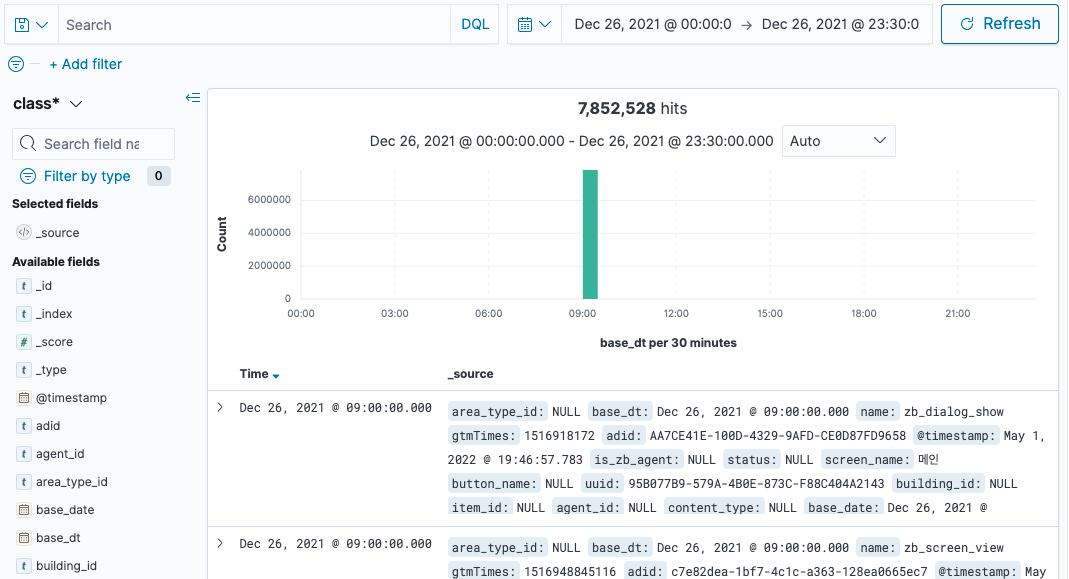
이외에도 Visualize 메뉴를 통해서 빠르게 들어오는 데이터(예시-신규 서비스 당일 접속자 데이터)를 그래프로 시각화를 할 수도 있고, Search Engine기반이기 때문에 매우 빠르게 처리를 해준다.
하지만 너무 많은 데이터를 ElasticSearch를 통해서 너무 많은 데이터를 처리하려고 하면 비용이 너무 많이 들기 때문에 이 경우에는 다른 구조로 파이프라인을 구성해서 데이터를 분석하는 것이 좋다.