이번 포스팅에서는 수집한 데이터를 전처리 및 저장한 뒤에 gold 데이터를 활용하여 분석 및 시각화하는 실습을 하는 부분에 대해서 정리를 해보려고 한다.
분석하기 편한 데이터 형태로 데이터를 변환한 다음에 해당 데이터를 시각화 작업을 통해서 분석작업을 한다.
Presto는 HDFS와 S3를 비롯한 여러 데이터 소스의 처리를 할 수 있는 분산 SQL query engine이다.
Presto는 Data Visualization Tool과 연동을 해서 작업을 할 수도 있다.
[핵심]
- Presto를 사용해서 S3에 저장되어있는 Hive Table Data를 BI툴에 제공할 수 있다.
- Presto와 Tableau를 연동하여 Dashboard를 구성할 수 있다.
- Near Realtime 분석툴 ElasticSearch를 활용할 수 있다.
분석 및 시각화 전체 흐름
EMR 내의 Spark을 통해서 정제된 데이터가 S3에 저장되고, 기본적으로 AWS에서 서비스를 운영하면 전반적인 데이터가 S3에 저장이 된다. 그리고 S3에 저장된 데이터에 대한 metadata 정보는 metastore인 AWS Glue에 저장이 된다. (순환구조)
분석가분들은 Glue에 저장된 meta정보를 기반으로 데이터 분석을 시작한다.
분석을 할때에는 EMR내의 Presto cluster(cluster이기 때문에 복수 개의 노드에 거쳐서 iterative하게 분석이 가능)나 Athena(serverless 분석툴)를 사용해서 진행한다. (Presto와 Athena 둘 다 SQL 분석 지원)
Tableau, Elastic search에서 가장 많이 사용하고 있는 Kibana를 통해서 시각화를 해 줄 수 있다.
[STEP1] S3에 저장되어있는 물리적인 Hive Table Data를 Presto를 이용해서 BI툴(Tableau)에 제공
Presto
Presto는 분산형 SQL 쿼리 엔진으로, 빅데이터에 대한 빠른 분석을 위해 등장한 기술이다. 과거의 DBMS처럼 별도의 repository를 가지고 있지 않으며, 이기종 데이터간에 JOIN을 할 수 있는 기능을 제공한다. (ANSI 호환 SQL문을 실행)
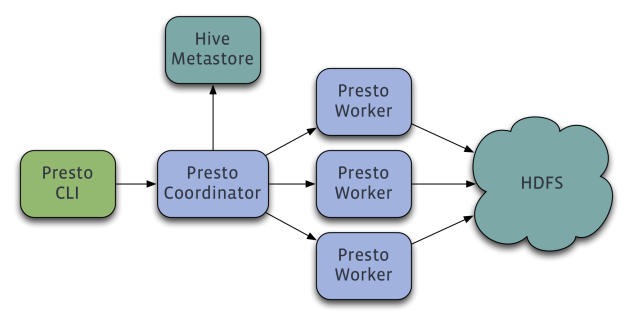
위에서 언급했듯이, Presto는 cluster로, 여러 worker로 분할되어 작업이 진행된다. 작업에 대한 내용은 Presto Coordinator가 Hive MetaStore로부터 땡겨오는 구조로 되어있다.
최초 접속은 Presto CLI를 통해서 Presto Coordinator에 접속하는 형태로 진행한다.
Coordinator (=> Master node)- SQL 구분 분석
- SQL query plan
- 어떤 작업 노드에 Job을 분류하고 실행할 것인지에 대한 전반적인 것을 조정
- REST API를 사용해서 Worker 및 Client와 통신
- 작업자의 결과를 가져와서 최종 결과를 클라이언트에게 반환
Worker- 작업 실행 및 데이터 처리
- 데이터를 가져오고 중간 데이터 교환
- REST API를 사용하여 다른 작업자 및 Presto coordinator와 통신
Presto관련 용어
Connector
Hive나 RDS와 같은 DBMS에 접속하기 위한 Connect Adapter로, Catalog의 물리적 정의 부분에 해당한다.
Catalog
Connector의 논리적 이름으로, 실제 SQL 조회시에 Catalog의 이름(논리적 이름)을 사용한다.
Schema
유사한 성격의 Table들의 그룹
Table
행과 열로 구성된 데이터
Athena와 Presto 사용의 차이
Athena도 Presto에서 실행되었던 SQL query를 실행시킬 수 있으며, serverless이기 때문에 전역에 필요한 배치처리를 돌리기에 좋은 환경을 제공한다.
다만, Athena는 RDS의 데이터와 JOIN해서 분석하는 기능은 제공을 하지 않기 때문에 EMR의 Presto를 사용하는 것이 권장되며, EMR Presto는 computing을 사용한 시간을 기준으로, Athena는 데이터용량으로 비용을 charging하기 때문에 상황에 따라 적절하게 서비스를 선택해서 사용하는 것이 좋다.
Presto cluster 생성
Presto cluster를 생성하기 위해서 EMR cluster를 생성하는데, AWS Amazon EMR에서 기존에 클러스터를 생생했던 방식은 똑같지만 세부옵션 내역은 조금 차이가 있다.
- 소프트웨어 구성 : Ganglia, Zeppelin, Presto
- AWS Glue 데이터 카탈로그 설정 : Presto 테이블 메타데이터에서 사용 포함 전체 선택
이기종 DB간에 데이터를 테이블을 JOIN하는 경우를 위한 setting을 위해 mysql-driver 설치를 위한 "단계 추가" setting은 추가해주는 것이 좋다.
Presto cli 접속
1 | #presto의 bin folder 하위의 presto-cli executable file로 command 실행 (버전은 상이하므로 확인 필요) |
Spark와 Presto의 데이터 query 방식은 서로 다르다.
우선 Spark는 초기 메모리로 Cache를 하고, query 작업을 한다.
반면에 Presto는 분산된 노드에 sql로 query를한 뒤에 데이터를 취합한다.
(Tip: 실제로는 속도면에서 별로 차이가 안나지만, Bronze 데이터로 정제한 뒤에 Presto를 통해 데이터를 분석하면 좀 더 빠르게 데이터를 분석할 수 있다)
(2022/04/29 업데이트)
Presto-MySQL 연동
Presto는 이기종간의 데이터를 JOIN해서 새로운 데이터 산출물을 만들어낼 수 있다. 따라서 이번 section에서는 Presto와 RDS 의 MySQL DB와 연동을 시키는 부분에 대해서 정리를 해볼 것이다. (computing 시간을 기준으로 비용이 책정되기 때문에 이부분에 유의해서 실습해보도록 하자)
1 | $cd /etc/presto/conf |
mysql.properties 파일내용
1 | connector.name=mysql #catalog name |
mysql DB를 읽기 위한 작업
/etc/presto/conf
1 | $sudo vi config.properties |
바로 presto prompt가 떠서 테이블을 출력해보려고 했는데, 생각보다 Presto 엔진을 재기동하는데 시간이 걸린다.
1 | presto:dw> show tables; |
1 | #[catalog name].[schema name].[table name] |
위의 query예시처럼 hive(data catalog)내의 테이블과 mysql(RDS master data) 테이블을 서로 JOIN해서 새로운 데이터의 형태로 가공할 수도 있다.
Presto를 통해서 새로운 테이블을 만들 수는 있지만, 용도자체가 분석용 툴이기 때문에 추천하지 않는 방법이라고 한다.
Zeppelin을 통한 Presto를 활용한 분석
분석가에게는 console에서 데이터를 분석하는 것은 사용감에 불편함을 주기 때문에 Presto를 Zeppelin과 연동시켜서 분석하는 방법을 채택하기도 한다.
[STEP1] Zeppelin 헤더의 우측 상단의 annoymous - [Interpreter] 선택
[STEP2] “Create” 버튼을 클릭해서 새로운 Interpreter로 Presto를 추가해준다.
MySQL이나 Presto를 대부분 연동할때 JDBC Interpreter를 통해서 연동하기 때문에 CLI를 통해서 JDBC Interpreter를 설치하고, 다시 Zeppelin으로 돌아와서 작업한다.
1 | $sudo su - #export JAVA_TOOL_OPTIONS="-Dzeppelin.interpreter.dep.mvnRepo=http://insecure.repo1.maven.org/maven2/" |
Zeppelin interpreter에 Presto Interpreter 추가
1 | Interpreter Name : presto |
presto에 접속을 하기 위해서 driver를 설치해줘야한다.
1 | $cd /home/hadoop |
Zepplin에서 새로 노트를 추가해보면, Default Interpreter에 추가해준 presto Interpreter가 리스트되어있는 것을 확인할 수 있다.