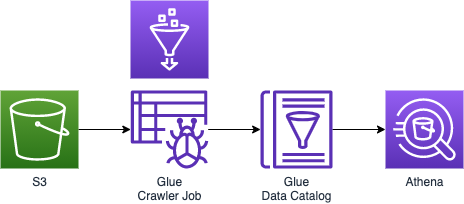
이번 포스팅에서는 AWS Glue의 Crawler에 대해 실습한 내용을 정리해보려고 한다.
데이터에 대한 트랜스폼 (CSV-JSON, JSON-PARQUET) 실습을 했는데, 쌓여있는 데이터를 크롤링을 통해서 glue에 있는 data catalog에 등록하는 작업을 실습해보고, 이렇게 Data Catelog에 쌓인 metadata를 분석하기 위해서 Atena를 사용해서 조회해보는 것 까지 실습해본다.
AWS Glue 데이터베이스 추가
테스트용 데이터베이스를 AWS Glue 하위의 데이터베이스에서 추가해준다.
데이터베이스 내의 테이블이 초기 생성에서는 비어있는 상태인데, 크롤러 추가 버튼과 함께, 크롤러를 통해 DB내의 테이블을 생성할 수 있음을 알 수 있다.
크롤러 추가
(1)Crawler source type / (s3에서 할 것이기 때문에) Data stores 선택
(2)Repeat crawls of S3 data stores / Crawl all folders 선택
(3)데이터 스토어 추가 데이터에 대한 transform (CSV-JSON, JSON-PARQUET) 실습을 했을 때 적재했던 S3의 폴더의 경로를 지정하면 된다.
(4)IAM 역할 선택 S3에 저장된 데이터에 Glue의 Crawler가 접근해서 가져오는 것이기 때문에 IAM 권한 설정이 필요하다.(IAM 역할 생성)AWSGlueServiceRole - crawlerclass
(5)크롤러의 일정 생성
S3에 주기적으로 데이터가 올라오는 것이면, 빈도에 대한 설정이 필요하다.
크롤러를 실행하게 되면, 해당 s3폴더로 가서 파일을 다 읽어서 유형이 어떤 타입이고, 무엇을 판별하고, 각 칼럼에 어떤 값이 있는지 읽어온다.
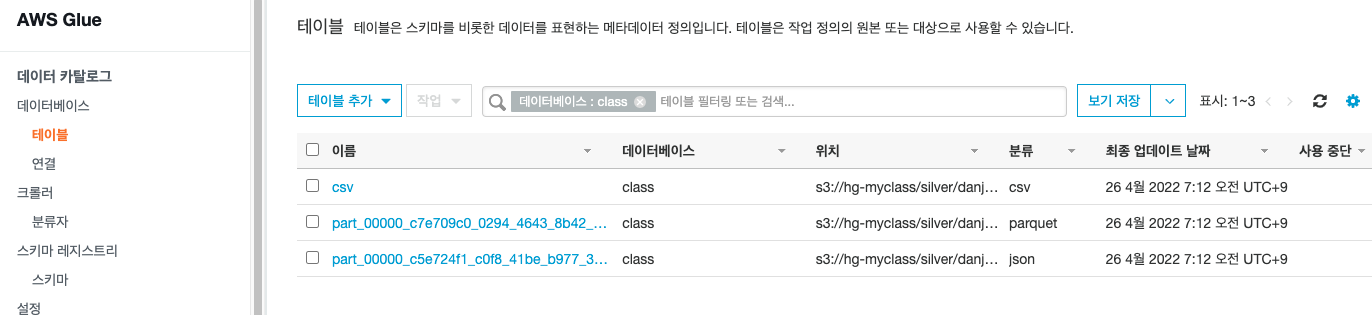
위와같이 크롤러를 실행한 뒤에 3개의 새로운 테이블이 생성되었음을 확인할 수 있다.(JSON/PARQUET format 데이터의 테이블의 경우에는 크롤러가 column정보를 쉽게 읽을 수 있다. 반면에 csv format 데이터의 테이블의 경우에는 column정보가 col1, col2...로 정의가 되어있음을 알 수 있다.)
Parquet는 데이터에 대한 데이터 타입까지 다 가지고 있기 때문에 좀 더 빠르게 데이터 값을 읽을 수 있다.
1 | 입력 형식 org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat |
Partitioning
파티션 값도 Data store에 저장이 되는데, 파티션 값이 업데이트가 되지 않으면, 데이터를 제대로 조회할 수 없다.
이 부분에 대해서는 좀 더 자료 찾아보기 아직은 좀 이해가 되지 않는 부분이 있다. 날짜별로 Partitioning이 필요한 이유 등.. 이 부분에 대해서는 아래 부분에서 추가 학습을 통해 알게 되었다. Catalog Table을 생성할때 PARTITIONED BY (base_date) 옵션을 줘서 생성하게 되면, 날짜를 기준으로 폴더가 생성되고, 그 하위에 생성된 파일이 위치하게 되는데, 읽을 때에는 빠르게 읽을 수 있다는 장점이 있지만, 일괄적으로 저장할때에는 느릴 수 있다는 단점이 있다.각 파티션 값은 AWS Glue 서비스의 데이터 카탈로그 테이블에서 확인할 수 있으며, 파티션 값만 따로 관리하는 메뉴도 있다.
그리고 나중에 조회를 할 때 조건을 주면 해당되는 날짜의 폴더에 있는 데이터만 호출해서 읽을 수 있다. (SQL의 퍼포먼스를 높일 수 있는 조건)
Redshift spectrum, Athena통해서 조회할때도 파티셔닝을 주게되면, 해당되는 데이터만 읽어오기 때문에 조회할때 금액적으로 저렴하게 처리할 수 있다.
Amazon Athena
이제 Crawler가 S3에 있는 데이터를 가져다가 AWS Glue Data Catalog에 저장을 했다. 이제 Glue Data Catalog Server는 Metadata repository로써 Amazon Athena와 같은 분석 툴을 사용해서 분석을 할 수 있다.
Athena는 query를 실행했을 때 Loading 양에 따라서 charging이 되는 방식으로 요금이 부과된다.
Athena의 엔진은 Presto를 사용하고, 최근에는 기본적인 ML을 수행할 수 있게 Query에서 처리할 수 있게 업그레이드 되었다.
Athena query result output settings
Athena에서의 쿼리 실행결과를 담을 공간에 대한 setting을 초기에 해줘야한다.
UI 구성 살펴보기
데이터 원본으로 AwsDataCatalog이고, 데이터베이스는 이전 테스트 실습을 위해 생성한 이름으로 default 설정된 것을 확인할 수 있었다.
그리고 테이블은 Crawler를 통해 추가 생성된 테이블이 리스트업된 것을 확인할 수 있다.
각 테이블을 통해 어떤 데이터를 가지고 있는지 query를 통해 조회가 가능했다.
(2022/04/27 업데이트)
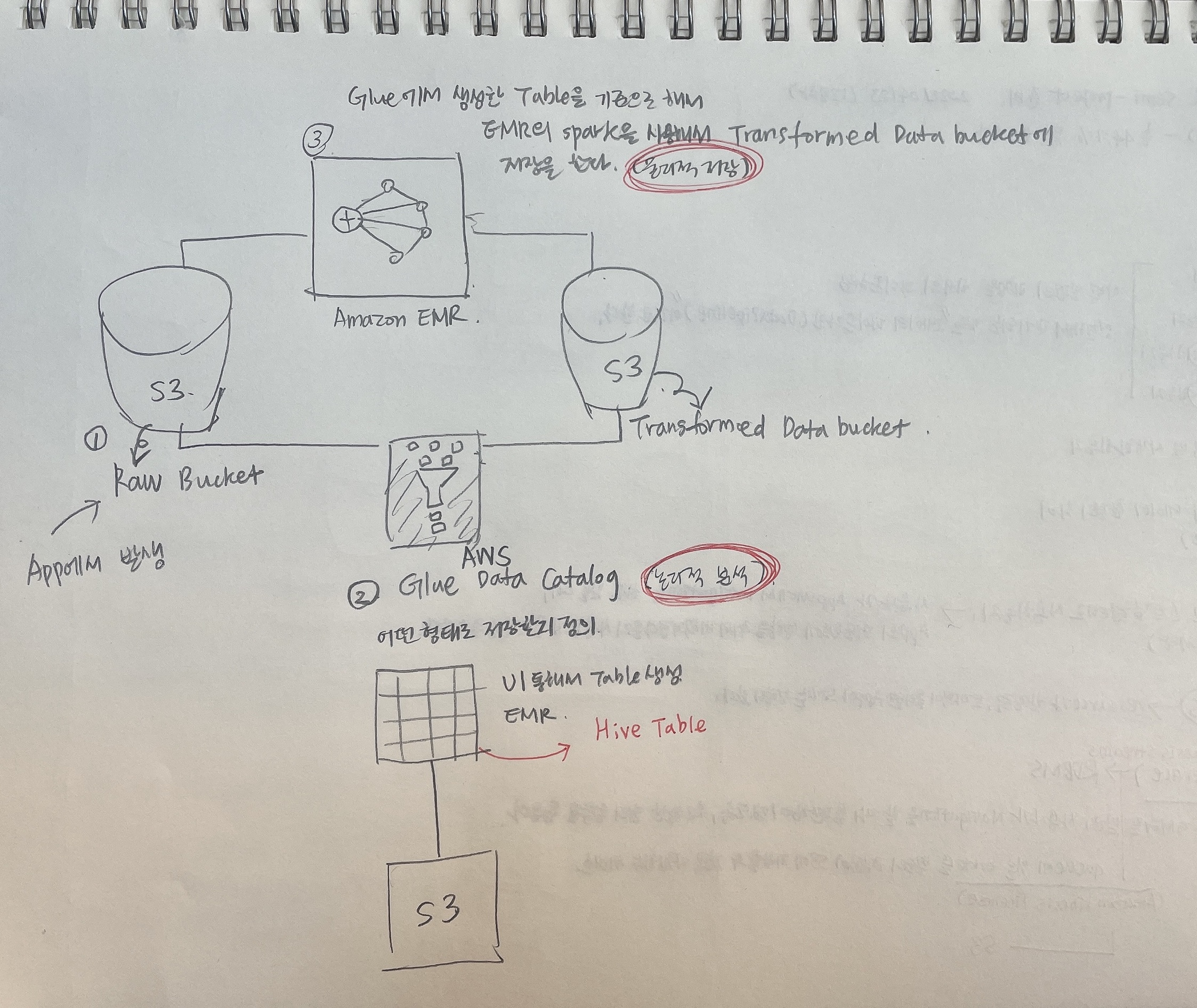
데이터 파이프라인의 전체 flow 잡고 들어가기
(flow1)
우선 S3에 저장된 Bronze 데이터를 EMR에 있는 Spark를 활용해서 전처리를 한 다음에 Sliver 데이터의 형태로 변환을 한다. 변환된 데이터의 경우에는 과거에는 RDS에 저장을 하였으나, 요즘에는 S3에 저장을 하고, S3에 저장을 할 때에는 기본 metadata는 앞서 실습을 했듯이 AWS Glue Data Catalog라는 곳에 테이블을 정의 및 데이터를 저장해서 sliver 데이터를 관리하도록 할 것이다.
(flow2)
생성된 sliver 데이터를 기준으로, EMR의 Spark를 활용해서 RDS나 Redshift에 Gold 데이터를 저장하는 형태로 flow가 진행이 된다.
최근에는 Gold 데이터도 S3에 저장을 한 다음에 Athena와 같은 분석 tool을 활용해서 분석을 한다.
AWS Glue를 활용한 분석 Table 생성
위에서 표시한 부분은 AWS Glue Option으로, Catalog setting에 대한 옵션이다. metastore의 역할을 하는 data catalog를 활용을 할 것인데, 외부 DB에 metastore를 운용하는 경우도 있는데, 관리 point를 줄이기 위해서 Glue에 있는 data catalog를 사용하는 것을 권장한다.
Hive table(Hadoop의 metastore 기능) 선언 후 데이터를 넣을 때 필요한 옵션
선언한 Hive table에 데이터를 insert해서 넣을 때 필요한 옵션이다.
Dynamic partitioning(여러 폴더가 있으면 각 폴더에 데이터를 나눠서 넣을 수 있도록 하는것)
아래와같이 SparkSession에 option을 추가설정해준다.
1 | val spark: SparkSession = |
log file 내의 내용을 확인하고 parsing하는 function이 별도로 필요한 경우에 function을 짜지만, 파일의 사이즈가 커지더라도 JSON format으로 파일을 저장해주는 것이 관리적 측면에서 좋다.
1 | logsDFAll.createOrReplaceTempView("logs") |
위의 코드는 Ganglia의 Cache 영역의 표시를 확인할 수 있는데, 이 부분에 데이터를 올릴때, 옵션을 따로 줄 수 있는데, 이 캐시 주는 부분은 데이터 프레임 자체에 캐시를 주거나 위의 코드와 같이 view table 자체에 캐시를 주는 경우가 있다.
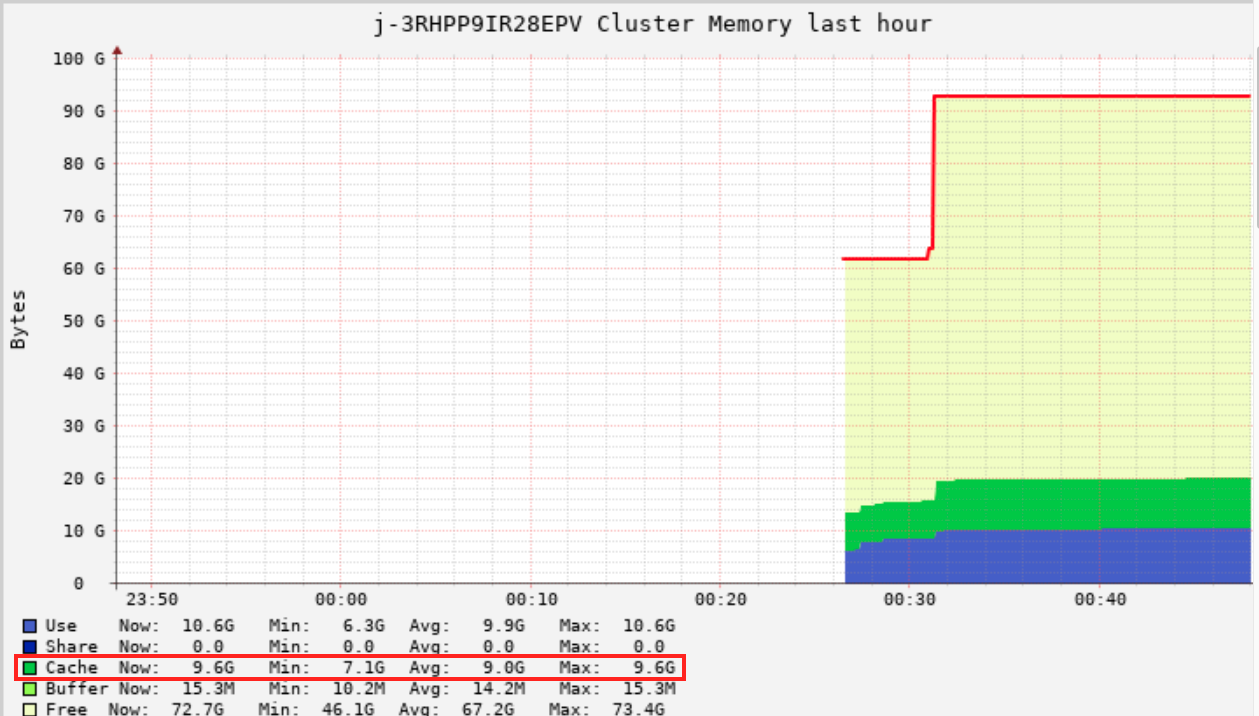
caching을 하면, S3에 있는 데이터를 대해서 캐시로 로드를 해야한다. 이러한 이유로 아래와같이 count(*)로 일괄적으로 캐시 데이터를 로드해준다. (캐싱하려는 데이터가 master성 데이터라면, 캐싱하는 과정을 통해서 이후 과정이 수월하게 진행될 수 있게 하는 것이 좋다)
1 | %sql |
왜 Zeppeling의 Spark SQL을 통해서 전처리한 데이터를 단순 테이블 형태 말고도 각종 그래프 형태로 시각화시켜서 시계열 그래프로 데이터의 기간별 추이를 살펴볼 수 있다.
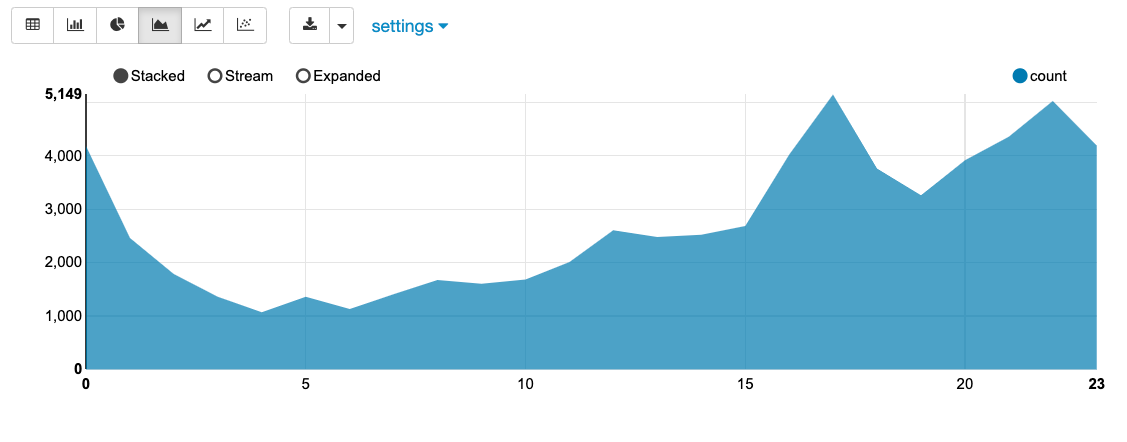
Parquet 포멧으로 S3에 저장 및 확인
metaStore가 없던 시절에는 Parquet 포멧 형태로 데이터를 저장해서 많이 사용되었었다.
1 | val dataDF = sqlContext.sql(s""" |
하지만 위와같이 파일을 쌓는 방식은 File I/O가 발생하기 때문에 속도면에서 많이 느리다는 단점이 있다.
Hive Table(Hadoop의 metastore 기능)을 생성하고 삽입하는 방식
(방식1) Zeppelin에서 SQL Query로 Hive테이블 추가 - AWS Glue에 Table 정의
Spark data catalog로 연결을 해놓은 상태이기 때문에 아래와같이 테이블을 쿼리로 생성해도 생성이 된다.
Storage를 하둡이 아닌 외부(EXTERNAL)에 저장을 하기 위해서 아래와 같이 CREATE EXTERNAL로 정의한다.
1 | %sql |
PARTITIONED BY 옵션은 날짜별로 폴더가 생성이 되고, 그 하위에 생성된 파일이 위치하게 된다. (속도있게 읽기 위한 옵션/단, 저장할때는 느릴 수 있다)
생성된 Hive table은 AWS Glue 서비스의 데이터 카탈로그 테이블에서 확인할 수 있다.
열 이름 중에는 Partition 키의 역할을 해주는 칼럼이 있는데, 이 파티션을 통해 등록된 내용을 통해서 데이터가 참조된다.
INSERT 명령을 통해서 생성한 테이블에 데이터 입력하기
1 | sqlContext.sql(s""" |
Parquet로 데이터 파일을 추출하는 것보다 위와같이 생성한 메타데이터 테이블에 데이터를 넣고 관리하는 것이 속도면에서 빠르고 효율적이다.
(방식2) AWS Glue 서비스에서 직접 수동으로 테이블 추가
(방식3) Athena에서 query를 통해서 테이블을 추가
(결론) 전처리한 데이터를 Parquet 포멧으로 S3에 저장하고 저장된 데이터를 DataFrame 형식으로 호출해서 사용하는 방식과 HiveTable을 생성(target 테이블은 Glue의 catalog table)하고, metadata 형태로 데이터를 저장해서 호출하는 방식을 비교했을때, 후자의 방식이 더 효율적임을 알 수 있었다.
Glue의 스키마에 설명 포함시키기
메타정보를 관리할때 테이블 스키마의 설명정보를 관리하는 것이 좋다. (한글명/부가설명)
Sliver data를 통해서 Master성 데이터와 Gold 데이터로 정제하기
정형화된 데이터를 Data Catalog에 정의를 하고, Master성 데이터를 DBMS에 별도로 구성(ODS, Operation Data Store)해서 넣는다.
이렇게 따로 DBMS에 구성한 마스터성 데이터와 정제한 데이터를 잘 조합해서 다른 GOLD Data/DM(시각화가 가능한 형태의 데이터)로 만들어서 저장을 한다.
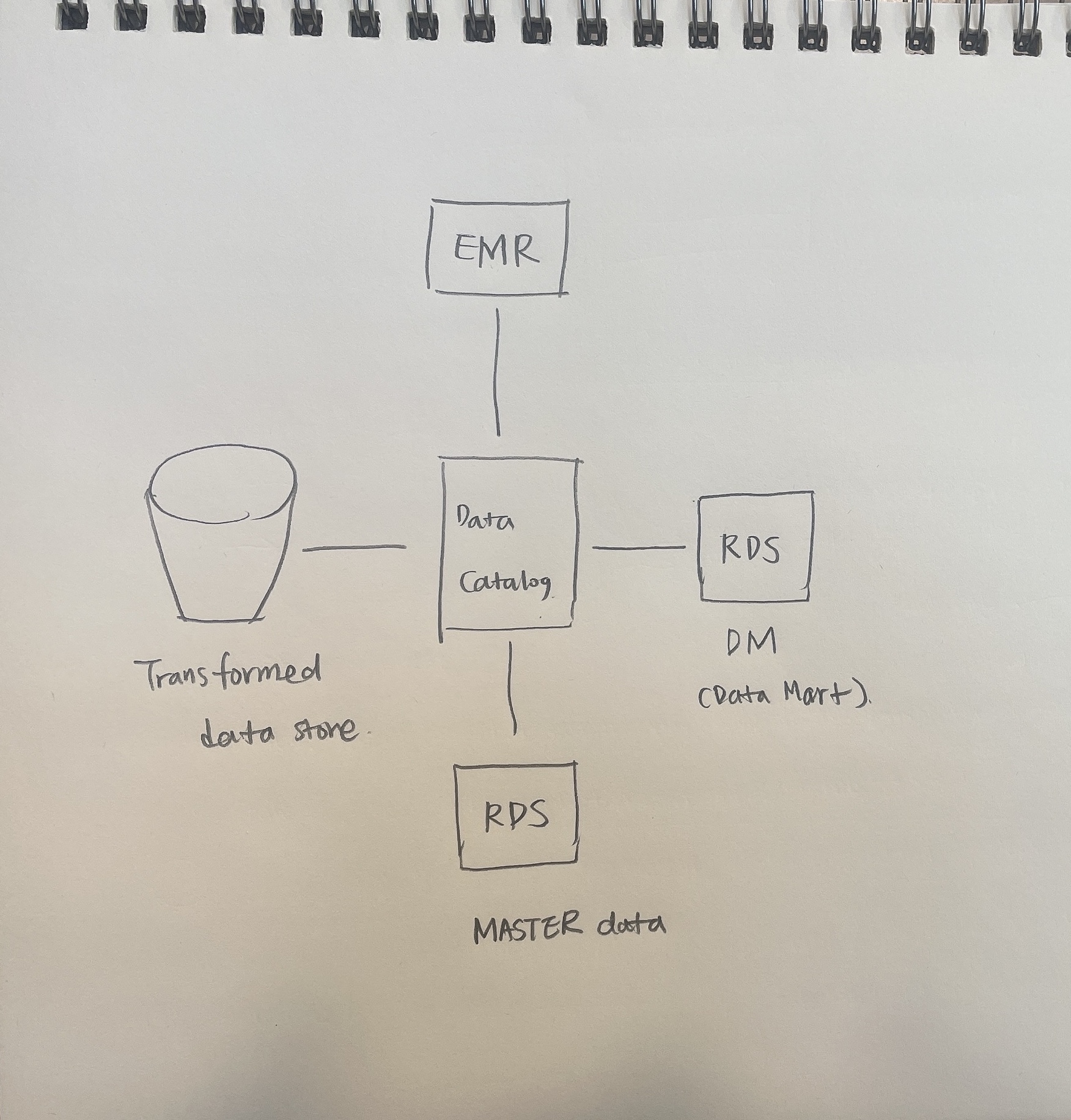
RDS에 Gold 데이터를 저장
1 | val localDF = sqlContext.sql(s""" |
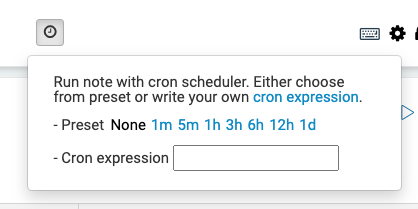
특정 시간에 Zeppelin notebook을 실행시켜줄 수 있도록 설정(cron job)
우선 어플리케이션은 기본적으로 master node에 설치가 되어있기 때문에 master node로 접속을 한다.
1 |
yum update를 하게 되면 라이브러리가 업데이트가 되서 문제가 될 수 있으니, 업데이트 하지 않는 편이 좋다.
1 | $cd /usr/lib/zeppelin/conf |
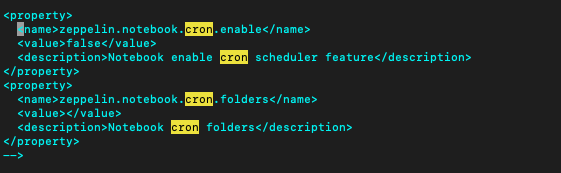
이제 Zeppelin 노트북에서 노트북 파일을 열면 우측 상단에 시계모양의 아이콘이 보이게 되고, 해당 아이콘으로 cron 설정을 해줄 수 있다.정해진 시간 간격으로 Zeppelin notebook에 작성한 script를 통해서 데이터 분석을 실행 할 수 있다.