
이번 포스팅은 Spark에 대해서 정리를 해보려고 한다. 데이터 파이프라인 실습에서 이미 Spark interpreter를 사용해서 데이터 전처리를 하고 있다. 그런데 아직 정확히 Spark에 대한 개념적 정의가 되지 않았기 때문에 이 부분에 대해서 정리를 하고 넘어가려고 한다.
Spark ?
Spark는 거대한 양의 데이터를 합리적인 방법으로 처리하고, 더 나아가 ML이나 Graph 분석 그리고 Data streaming 등의 멋진 기능을 포함하고 있는 친구이다.
이전에 데이터 파이프라인 구축 실습에서 데이터 batch 처리(ETL)나 실시간 스트리밍 데이터를 처리할때도 모두 이 Spark라는 친구를 사용한다고 했으니, 정말 대단한 친구임에는 틀림이 없다.
이처럼 Spark의 역량과 속도는 엄청나며, Java나 Scala, Python과 같은 실제 프로그래밍 언어를 사용해서 스크립트를 작성할 수 있는 유연성을 제공하고, 복잡한 데이터를 조작이나 변형, 분석할 수 있는 능력자이다.
앞서 실습해보았던 Pig같은 기술과의 차이점은 Spark 위에는 또 다른 엄청난 생태계가 존재한다는 것이다. 그 생태계에는 ML, 데이터 마이닝, 그래프 분석, 데이터 스트리밍과 같은 복잡한 일을 해결할 수 있다. 이처럼 Spark는 강력하고 아주 빠른 프레임워크이다. 다른 Hadoop 기반의 기술처럼 확장성도 가지며, Spark는 드라이버 프로그램(작업을 어떻게 진행할지 통제하는 스크립트)의 패턴을 따른다.
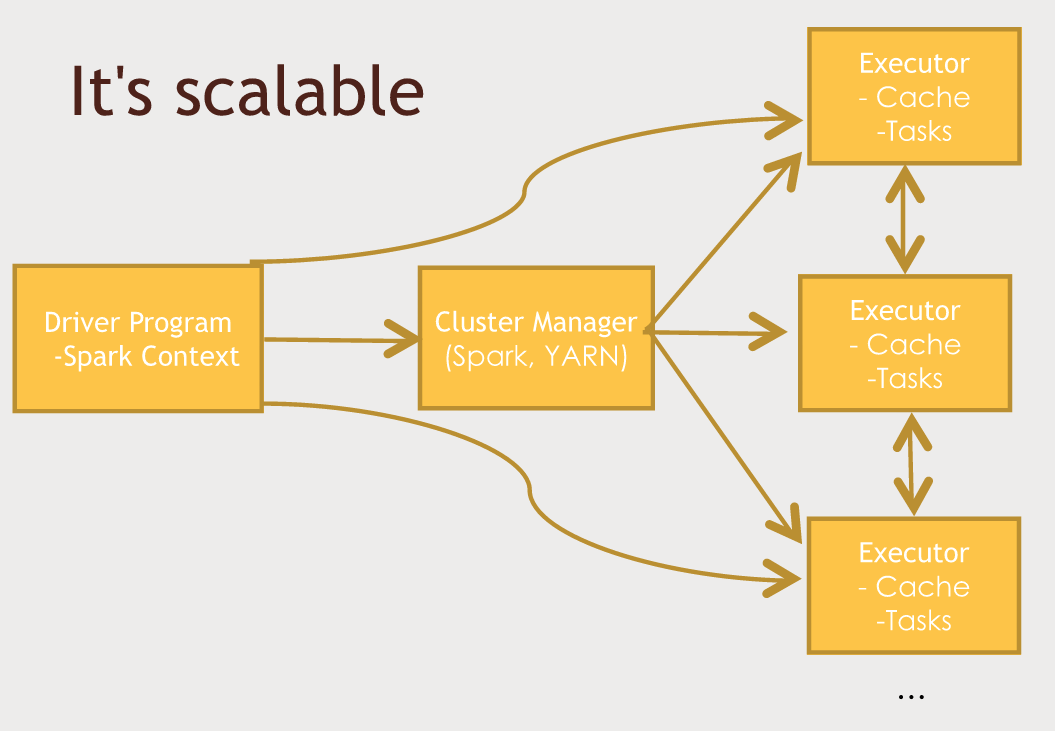
Spark는 Hadoop위에서 작동할 수도 있지만, Hadoop 위에서 반드시 동작할 필요는 없고, 내장된 클러스터 관리자를 사용하거나 Mesos라는 클러스터 관리자를 사용할 수도 있다.
어떤 클러스터 관리자를 사용하든지 범용 컴퓨터 클러스터 매니저(Spark, YARN)에 의해서 작업을 분배하게 되고, 데이터를 아래와 같이 병렬로 처리하게 된다.
각 작업 집행자들은 Executor프로세스라고 불리며, 각 각 Cache와 Task를 갖는다. Cache는 Spark 성능의 키(키의 일부분)이며, HDFS와 항상 접촉하는 디스크 기반 솔루션과 달리 Spark는 메모리 기반 솔루션이다. 따라서 Spark는 정보를 최대한 RAM에 유지하며 처리한다. (속도의 비결)
또 다른 키로는 방향성 비사이클 그래프인데, MapReduce와 비교하면 메모리 내에서 작동할때 최대 100배까지 빠르고 디스크 액세스에 제한되면 10배까지 빠른 속도를 낸다.
MapReduce로는 Mapper와 Reducer의 관점을 생각해야 되기 때문에 할 수 있는 일이 제한이 되지만, Spark는 프레임워크로 제공해서 이러한 고정적인 관점의 단계를 건너뛸 수 있다.
원하는 결과가 무엇인지와 프로그램에 좀 더 집중할 수 있다는 장점을 가지고 있다.
이전에 TEZ와 Pig를 같이 사용했을 때 방향성 비사이클 그래프에 대해서 언급을 했었는데, Spark에서도 같은 것이 내장되어있기 때문에 Spark도 최종 결과로부터 시작해서 거꾸로 돌아가면서 작업의 흐름을 최적화하고 최정결과에 다다르는 가장 최적의 방법을 계산한다.
거대한 데이터 세트와 현실의 문제해결
많은 거대 기업들이 거대한 데이터 세트를 활용해서 현실의 문제점들을 해결하기 위해 노력하고 있다. 이러한 노력의 과정속에서 사용되고 있는 프레임워크가 바로 Spark인데, Amazon, eBay, NASA, Yahoo등의 많은 기업들이 이미 Spark를 사용하고 있다.
Spark는 단 몇 줄의 코드만으로 클러스터에 굉장히 복잡한 분석을 할 수 있다는 매력을 가지고 있다.
RDD(Resilient Distributed Dataset, 회복성 분산 데이터)
회복성 분산 데이터란, 기본적으로 데이터 세트를 나타내는 객체이다. 그리고 RDD객체에 다양한 함수를 사용해서 이를 변형하거나 reducing하고 분석해서 새로운 RDD를 생성할 수 있다. 여기서 말하는 RDD 데이터 구조가 바로 스파크의 기본 데이터 구조이다.
따라서 입력 데이터의 RDD를 가져와서 변형하는 스크립트를 작성하는 것이 보통이다.
2016년에 최초로 출시된 Spark2.0에는 RDD위에 데이터 세트를 생성할 수 있도록 만들어졌다. SQL을 의식한 RDD개발이었지만 결국 RDD를 중심으로한 구축이 되었다.
Spark Core내의 RDD에 프로그래밍을 하면, Spark 위에 구축된 라이브러리 패키지가 있어서 함께 사용이 가능하다. Spark Streaming도 그 패키지들중에 하나인데, 데이터를 일괄 처리(Batch processing)하는 대신에 실시간(RealTime processing)으로 데이터를 입력할 수 있다.
Spark Streaming의 매력
웹 서버 여러 대가 운영 중이라고 가정해보면, 동시 다발적으로 배출되는 로그 데이터를 실시간으로 가져와서 일정 시간 안에 분석을 하고, 데이터베이스나 NoSQL 데이터 스토어에 그 결과를 저장할 수 있다.
그리고 위의 일련의 처리들을 Spark Streaming에서 단 몇 줄의 코딩으로 처리할 수 있다.
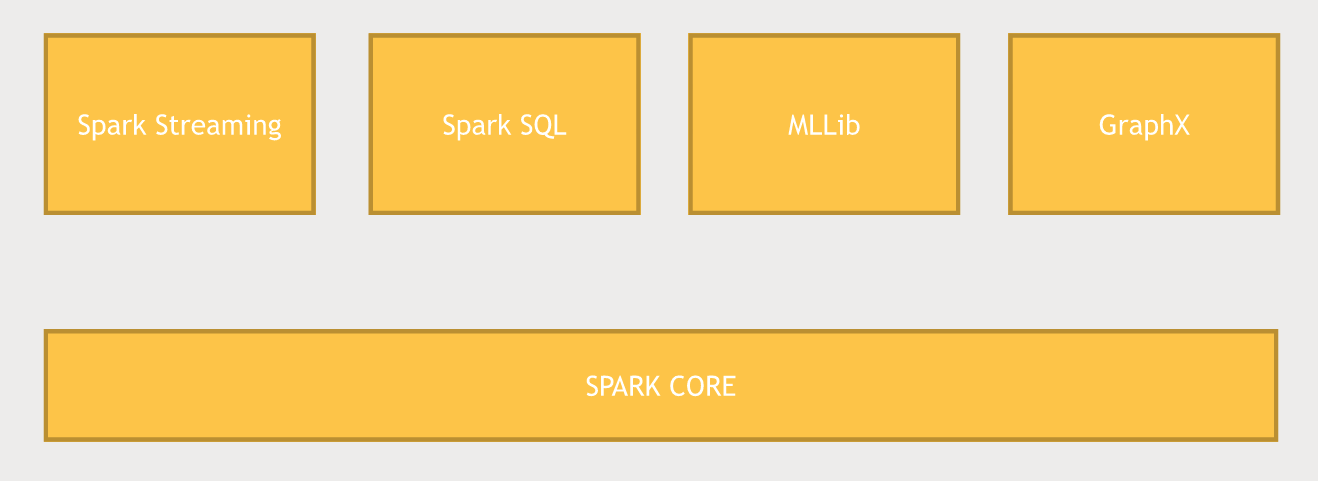
Spark SQL
Spark SQL은 Spark의 SQL 인터페이스로 데이터에 그냥 SQL 쿼리를 작성하거나, SQL 유사함수를 사용해서 Spark의 데이터 세트를 변환할 수 있다.
이것이 앞서 언급하였던 Spark의 방향성이며, Spark SQL를 활용해서 데이터 세트를 최적화를 하게 되면, 방향성 비사이클 그래프 이상의 최적화를 가능하게 한다.
MLLib
MLLib도 흥미로운 기술인데, Spark의 데이터 세트에 실행하는 ML이나 데이터 마이닝같은 도구의 라이브러리이다.
대략적인 클래스만 만들어놓으면 Spark MLLib이 데이터의 의미를 추출해서 회귀 분석이나 클러스터링 같은 머신 러닝 문제를 해결해준다. (아직은 잘 모르겠지만 일단 이런 라이브러리가 있다는 것만 알아두자)
GraphX
그래프 이론에서 사용되는 그래프인데, 사람과 사람간의 촌수 관계를 연결해서 계산을 할 수도 있고, 그 외에 재미있는 것들을 할 수도 있다.
Python과 Scala
Python은 테스트용으로 사용하기에 무난하지만 결국 Scala로 옮겨가게 될 것이라고 한다. Spark를 개발한 언어가 바로 Scala이고, Spark의 작동방식을 구성한 기능적인 프로그래밍 모델이기 때문이다.
Scala는 훨씬 빠르고 안정적인 성능을 가지고 있는데, Python처럼 오버헤드가 필요가 없으며, Scala는 Java의 바이트 코드에서 바로 컴파일을 하기 때문에 효율적이다.
Python code
1 | nums = sc.parallelize([1,2,3,4]) |
Scala code
1 | val nums = sc.parallelize(List(1,2,3,4)) |
RDD
RDD는 Resilient Distributed Dataset의 약자로, Spark 내에서 발생하는 클러스터내에서의 작업 분산과 작업 중간에 발생하는 실패에 따른 회복이 가능함을 나타내는 용어이다.
실제 사용자에게는 데이터 세트로 출력을 해주기 때문에 사용자가 고려할 것은 많지 않으며, RDD 객체는 키-값 정보나 일반적인 정보를 저장하는 수단이며 클러스터가 알아서 작업을 해준다.
RDD의 생성
(1) 드라이버 프로그램이 SparkContext라는 것을 생성
SparkContext는 Spark 환경 내에서 드라이버 프로그램이 작동하는 환경이자 RDD를 만드는 주체이다.
(2) 새 RDD에 데이터 텍스트파일 호출
텍스트 파일을 호출하면, RDD의 모든 행을 입력 데이터로 가진 텍스트 파일을 갖게 된다.
1 | # file://, s3n://, hdfs:// |
(3) hiveContext 사용
hiveContext를 사용해서 SQL 쿼리를 사용할 수 있는데, 아래와 같은 형태로 할 수 있다.
1 | hiveCtx = HiveContext(sc) |
(4) 그 외 convert 가능한 data format들
- JDBC
- Cassandra
- HBase
- Elasticsearch
- JSON, CSV, sequence files, object files, 다양한 압축 포멧들
(5) RDD Transforming하기
- map
- flatmap
- filter : RDD에서 데이터를 빼낼때 사용
- distinct
- sample : 무작위 표본을 만들때 사용
- union, intersection, subtract, cartesian
RDD 조작 예시
map 예시
1 | rdd = sc.parallelize([1,2,3,4]) |
RDD actions
(1) collect: RDD의 데이터를 가져와서 Python 객체를 반환하고 Python 드라이버 스크립트를 사용해서 출력하거나 텍스트 파일로 저장하는 등의 작업을 할 때 사용(2) count: RDD에 얼마나 많은 행이 있는지 세어준다.(3) countByValue: 각 각의 고유 값이 RDD에 얼마나 있는지 총계를 내준다.(4) take: 특정 시점에 RDD에 뭐가 있는지 재빠르게 확인하거나 디버깅할 때 유용하게 사용된다.(5) top: 예) 상위 10개의 결과를 구하는데 사용된다.(6) reduce: MapReduce에서 Reducing작업처럼 각 고유키와 관련된 값들을 집계하는 함수들을 정의한다.… and more …
Spark에서는 위의 명령어가 호출되기 전까지는 아무 일도 일어나지 않는다. 다시말하면,RDD에 이 함수를 호출하기 전까지 드라이버 스크립트에서 아무것도 실행하지 않는다는 것을 의미한다.
스크립트가 실행되면 비로소 종속성 관계를 통해 가장 빠른 경로를 찾아내고 그 후에 가장 빠른 경로를 찾아낸다.
그 다음에 최종적으로 클러스터에서 작업을 시작한다.
평균 평점이 제일 낮은 영화 찾기
1 | # SparkConf와 SparkContext를 불러와서 RDD를 생성하고, 작업하는데 필요한 것을 준비 |
1 | #spark-submit shell을 사용하면 Spark환경을 구성하고 |