
이번 포스팅에서는 AWS Glue라는 서비스에 대해서 배웠던 내용을 정리하려고 한다. 메타 데이터를 관리할 수 있는 서비스인데, 최근에 여러 회사에서 governance에 대한 관심과 여러 tool들이 많이 나오고 있고, data에 대한 정의(metadata)에 대해서 관심이 높아지고 있다.
이전에 데이터파이프라인에 대해서 가장 처음 전체적인 흐름에 대해서 배웠을때, 데이터 수집과 전처리의 중간 지점에 있는 관련 AWS 서비스에 Glue라는 서비스가 있다고 배웠는데, AWS Pipeline의 복잡해짐에 따라서 관리 및 운영이 어려워지고, 이러한 문제를 개선하기 위해서 등장한 친구라고 간단하게 배웠었다.
AWS Glue에는 파이프라인의 기본적인 서비스들이 추가가 되어있고, 가장 비용 효율적으로 잘 활용되고 있는 부분이 메타 스토어 정보가 포함되어있는 부분인데, meta store의 정보에는 데이터 위치, 포멧, 버전의 변경사항등에 대한 정보를 포함하고 있다고 한다.
(2022/04/27 업데이트)
Glue의 가장 큰 특징은 서버리스로, 설정하거나 관리할 별도의 인프라가 없다는 것이다. 그리고 메타 데이터만으로 ETL작업이 가능하기 때문에 원본 데이터의 변경 및 변경 데이터의 저장을 위한 별도의 저장소가 필요가 없다.(왜 데이터 파이프라인이 복잡해졌을때 Glue라는 서비스가 유용한지 이해가 잘 안됐었는데, 원본 데이터의 사용없이 메타 데이터만으로 ETL작업이 가능하다는 점에서 Glue라는 서비스는 별도의 파이프라인을 통하지 않고 메타 데이터만으로 분석이 가능하도록 해주는 아주 유용한 친구라는 것을 다시 개념정리를 하면서 알게 되었다.)
스케쥴링 기능으로 주기적인 작업을 실행하고 자동화할 수 있으며, 북마크 기능으로 작업상태를 저장하여 중단된 시점부터 작업 재개하는 것이 가능하고 작업에 대한 모니터링 또한 지원을 한다.
AWS Glue에 대해서 알아보기
기능 : ETL Workflow를 정의하고 관리할 수 있다.
[세부 서비스]
- Data Catalog : AWS Glue 데이터 Catalog는 영구적 Meta Data Store이다.(가격이 저렴)
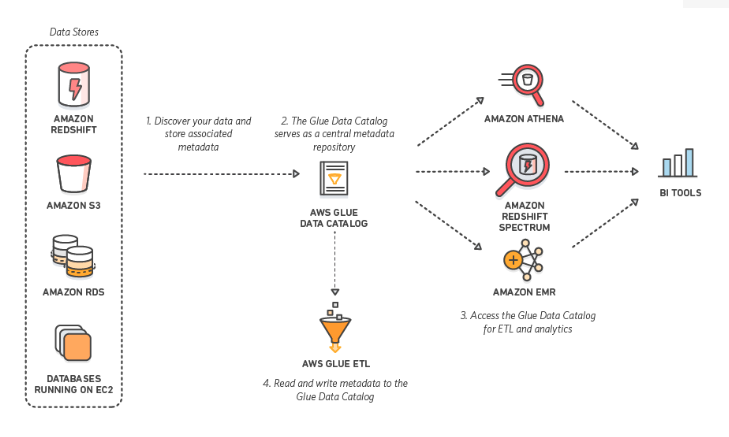
AWS GLUE Data Catalog는 Amazon Redshift, S3, RDS, EC2 기반의 데이터베이스에 저장된 데이터에 대한 metadata 정보를 담고 있다.
이렇게 담겨진 정보는 adhoc하게 분석을 할 수 있도록 도와주는 AWS Athena 분석툴이나 좀 더 심층분석이 가능한 Amazon Redshift Spectrum, Amazon EMR 서비스들을 통해서 AWS GLUE DATA CATALOG에 접근해서 ETL 분석을 할 수 있다.
- AWS Glue Crawlers : 리포지토리에서 데이터를 스캔하고 분류, 스키마 정보를 추출 및 AWS Glue Data Catalog에서 자동적으로 Metadata를 저장하는 Crawlers를 설정할 수 있다.(S3에 저장되어있는 데이터를 SQL로 분석을 한다는 것을 이해하기 위한 실습)
S3에 있는 데이터를 쉽게 분석할 수 있다는 이점이 있었지만,
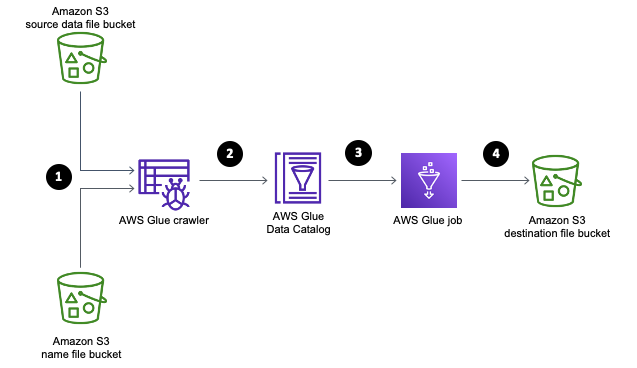
- AWS Glue ETL 연산 : AWS Glue Jobs System, Trigger 기능