이번 포스팅에서는 Amazon EMR(정확히는 EMR내의 Zeppelin의 Spark Interpreter를 통해서)에서 가공한 데이터를 내보낼 target에 대한 준비가 끝났기 때문에 이제 다시 Amazon EMR에서 어떻게 전처리한 데이터를 target 지정을 해서 내보내는지에 대해서 알아보도록 하겠다.
뭔가 데이터 파이프라인 구축은 정말 말 그대로 구성할 파이프를 각 각 만들어놓고, 특정 파이프의 output을 다음 공정의 파이프의 input으로 넣어주는 과정을 만드는 것 같다는 느낌에 재미있는 것 같다. 물론 각 파이프를 구성하고 전체적인 파이프라인 구성도를 생각해내는 것은 아직도 연습이 많이 많이 필요하지만, 그래도 이런 흥미를 붙였다는 것에 앞으로의 공부에 있어 좋은 원동력이 될 것 같다.
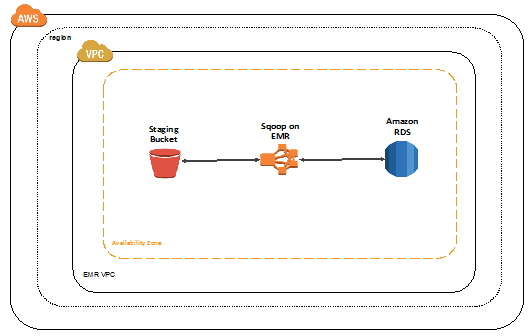
자 그럼 이제 본격적으로 Amazon RDS에 Spark로 가공한 데이터를 넣어주는 처리를 해보도록 하자.
Amazon EMR에서 전처리한 데이터를 Amazon RDS로 내보내기
과거에는 Zeppelin이 Maven의 기능을 그대로 가지고 있어서 필요한 Repo에 대한 설치를 쉽게 할 수 있도록 구성이 되어있었는데, 이 부분이 변경이 되었다. 따라서 jdbc mysql driver를 별도로 아래의 스크립트를 통해서 다운받아줘야한다.
Spark의 라이브러리에 MySQL driver를 다운받아서 설치해줘야한다. 이 부분은 EMR의 “단계”탭에 새로 스크립트가 실행될 수 있도록 새로운 단계를 추가시켜주면 된다.
1 |
|
EMR의 단계 탭에 새로운 단계를 추가해준 후에는 EMR에 적용시켜주기 위해 Zeppelin과 Spark이 접속된 Session을 재기동시켜줘야 제대로 적용된다.
Zeppelin session restart
Zeppelin은 Interpreter이기 때문에 접속 정보를 확인할 수 있는 부분이 있는데, 헤더의 최 우측 상단의 annoymous 메뉴 - Interpreter - Spark - restart
RDS 읽어오기
1 | val url = "jdbc:mysql://[AWS RDS End Point]:3306/dw?characterEncoding=UTF-8" |
DB에 쌓을 데이터 Load하기
1 | // CSV 파일을 읽어서 DataFrame 형태의 데이터로 가공한다. |
SQL Query를 돌릴 대상 view Table을 생성
1 | csvDF.createOrReplaceTempView("data_master_pq") |
Spark SQL / RDS Write
Spark SQL로 전처리한 데이터 테이블을 DB에 table로 저장한다.
overwrite : 덮어쓰기 (DBMS의 경우에는 기존의 Table을 삭제하고 다시 Table을 생성한다)append : 데이터 이어쓰기
1 | val table1 = "data_master_pq" |
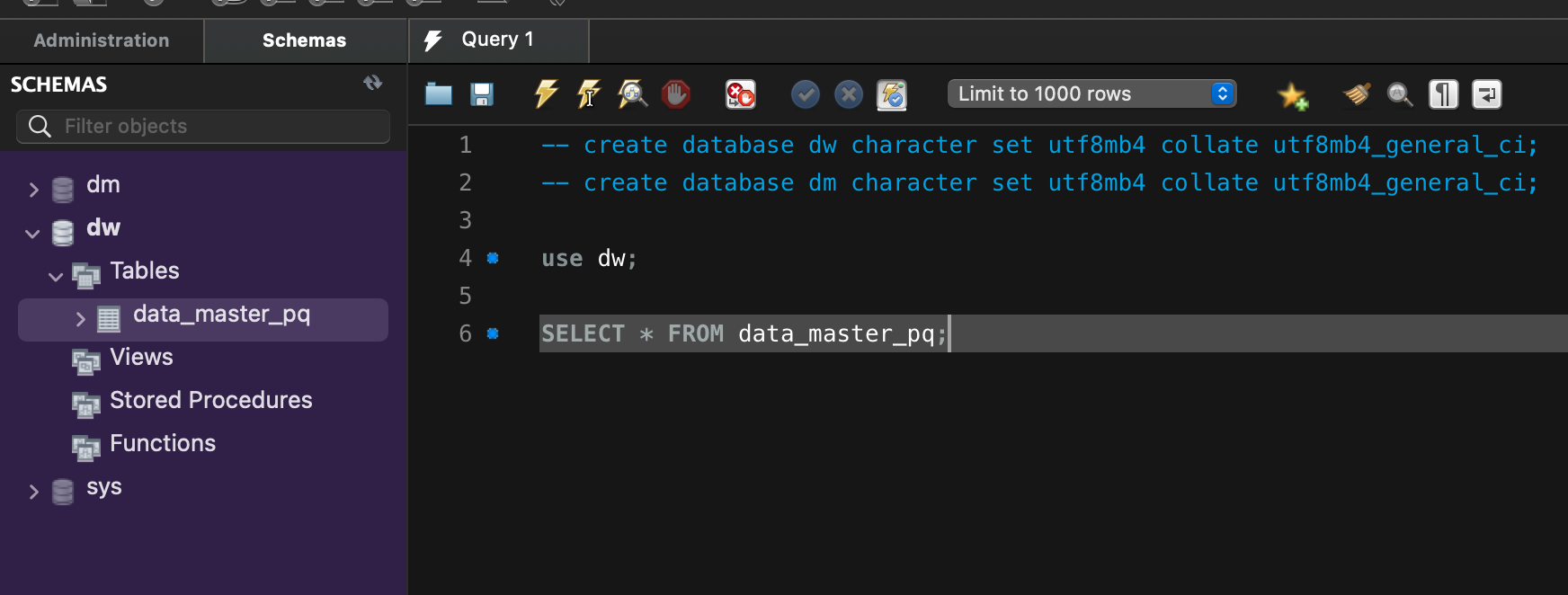
생성된 테이블을 보면, string에 해당되는 부분은 모두 text 타입으로 되어있는 것을 볼 수 있다.
(Spark에서 쓸때는 text type으로 정의해서 사용한다.
분석을 할때 column자체가 크기때문에 mysql자체가 느려질 수 있다.따라서 modify table을 통해서 column에 맞는 사이즈로 변경해주는 것을 권장한다.)
RDS로부터 읽기
Amazon RDS로부터 저장된 데이터를 읽어보자.
1 | // 반드시 alias를 붙여줘야한다. 아니면 에러발생 |