
이번 포스팅에서는 앞서 배운 Pig Latin script 작성방법을 기반으로 Ambari를 통해서 Hadoop 클러스터에서 Pig script를 실행해보고 결과값을 확인해볼 것이다.
Ambari에서의 Pig script 실행
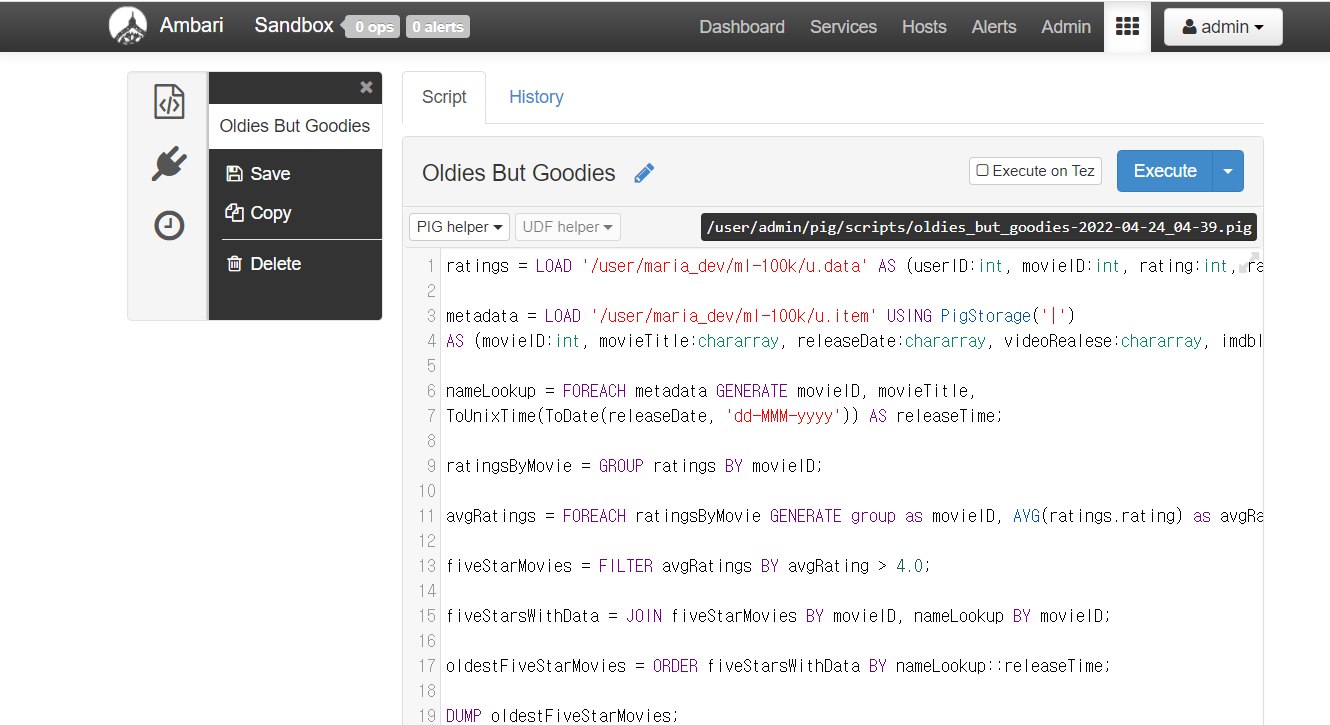
Hadoop stack을 사용해서 Pig Latin script를 실행해보았다.
결과는 Ambari에서 결과, Logs에 대한 기록, 작성한 Script Details 정보를 각 카테고리별로 분류해서 확인할 수 있었다.
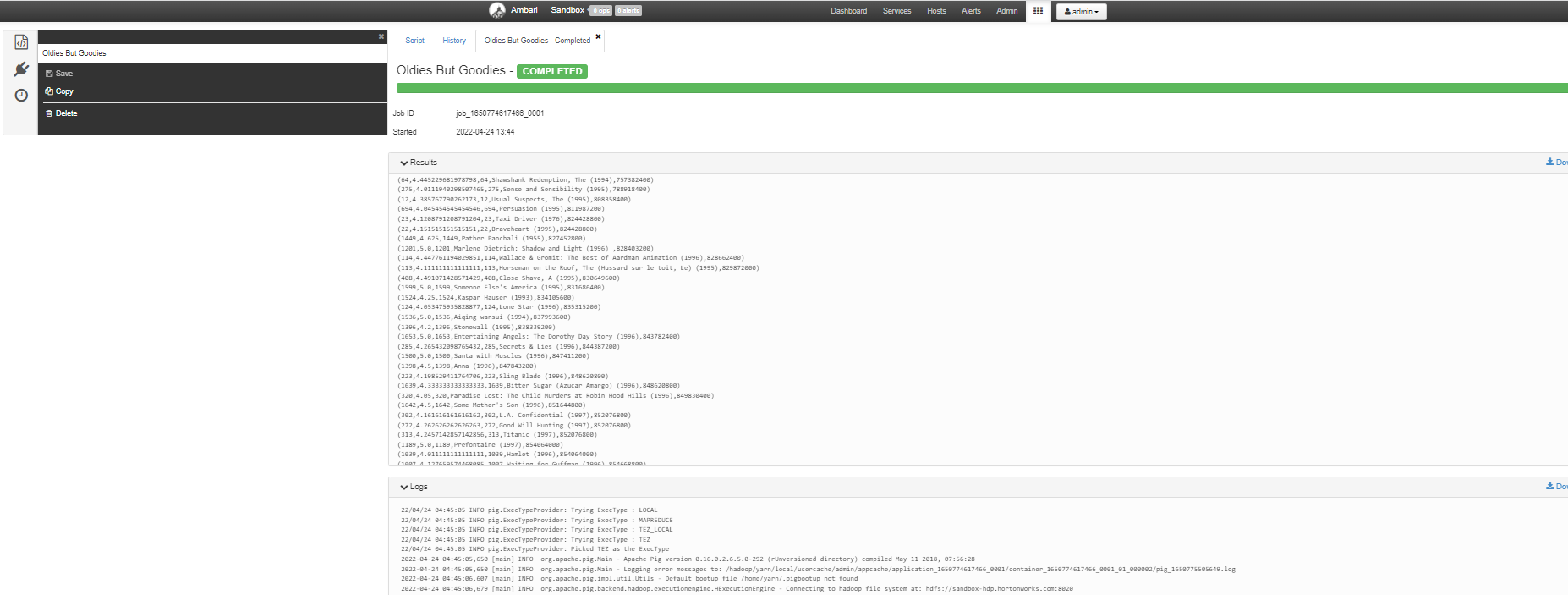
[TEZ를 기반으로 Pig script 실행]
이전 포스팅에서 하둡의 생태계에 대해서 배울때 배웠듯이, Pig는 MapReduce를 사용하지 않고, TEZ를 사용해도 된다. TEZ는 비정형 사이클 그래프를 사용해서 여러 단계의 상호관계를 분석해서 최적의 경로를 찾아낸다.
최종 경로부터 역순으로 각 단계의 종속성으로부터 가장 최적의 경로를 찾아낸다.
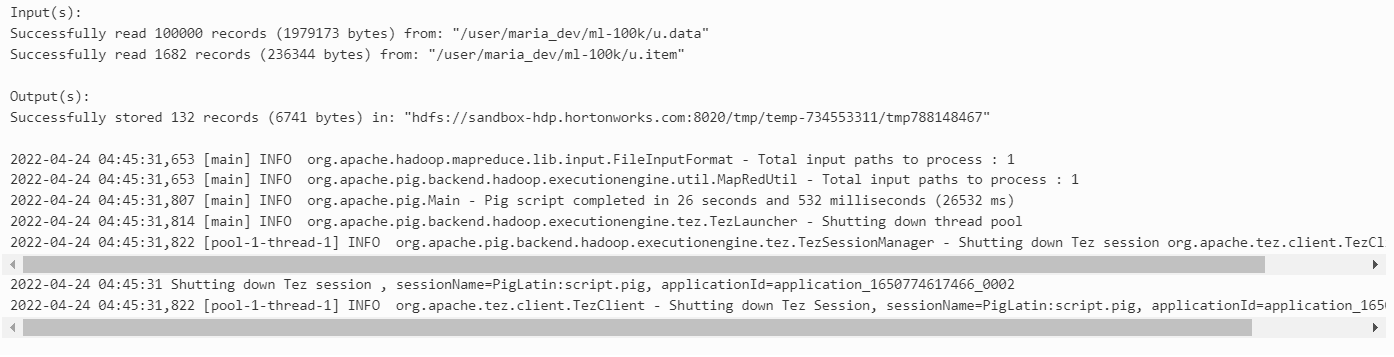
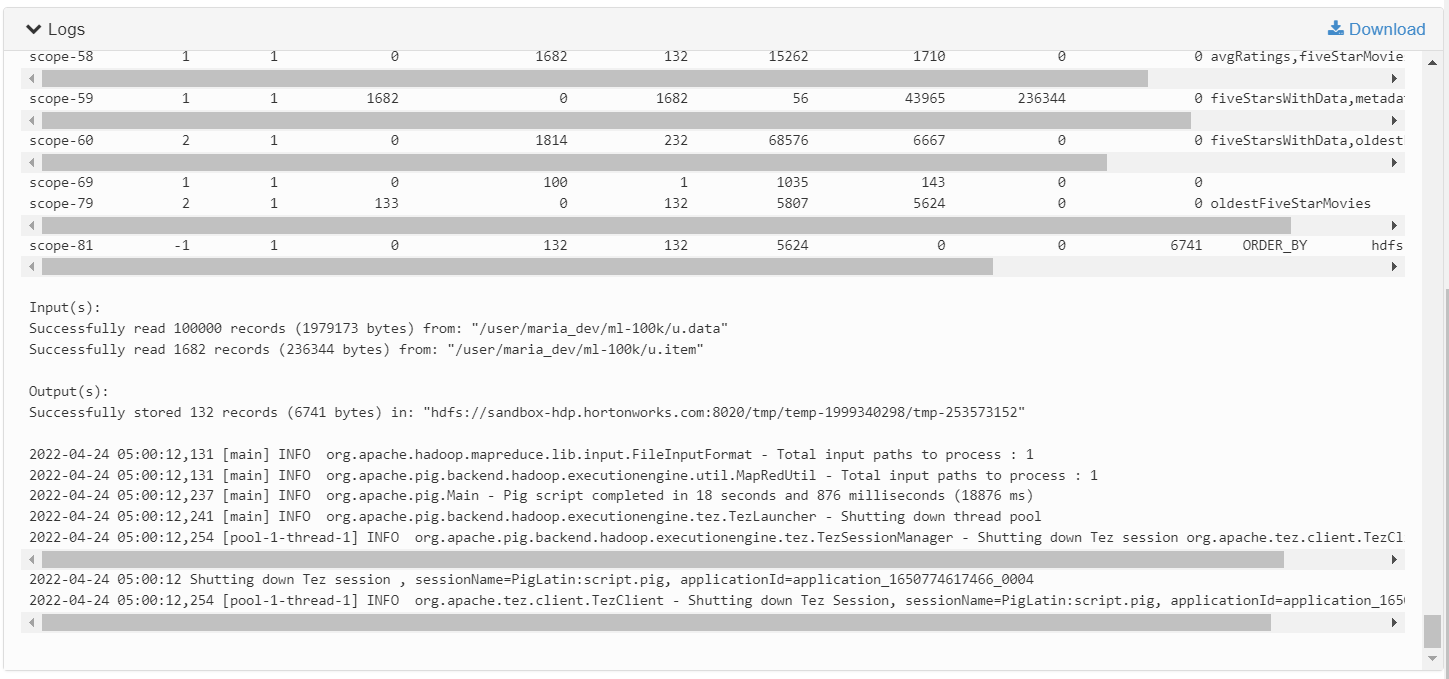
결과적으로 보았을 때, Pig script를 MapReduce보다는 TEZ 기반으로 실행했을때 약 2배정도 처리 속도가 빨랐음을 알 수 있었다.
이처럼 하둡의 생태계에는 여러 기술들이 집약되어있는데, 어떤 기술과 어떤 기술을 조합해서 사용하느냐에 따라서 다른 퍼포먼스를 보여준다.
Pig Latin script에 대해서 더 알아보기
STORE 관계성 이름 INTO 파일이름 USING PigStore('[delimiter]');
FILTER DISTINCT FOREACH/GENERATE MAPREDUCE STREAM SAMPLE
- MAPREDUCE : Pig와 MapReduce를 따로 사용하지 않고 혼합해서 사용
- STREAM : Pig의 결과물을 STREAM 형태로 출력
JOIN COGROUP GROUP CROSS CUBE
ORDER RANK LIMIT
UNION SPLIT
DIAGNOSTICS
- (1) DESCRIBE : 관계성의 스키마 출력
- (2) EXPLAIN : 주어진 쿼리를 어떻게 실행할지에 관한 설명 출력
- (3) ILLUSTRATE : 관계성에서 표본을 가져와서 각 데이터 조각들을 가지고 무엇을 하는지에 대한 것을 출력
Pig 내부적으로 무슨 일이 일어나는지 구체적으로 알고 싶은 경우에는 (2)EXPLAIN과 (3)ILLUSTRATE를 사용하고, 테이블의 관계성 스키마를 확인하기 위한 목적에서는 (1)DESCRIBE를 사용하도록 한다.
UDF(User Define Function)
REGISTER: UDF가 포함된 jar 파일을 가져오는데 사용DEFINE: 함수에 이름을 부여해서 Pig 스크립트 내에서 사용할 수 있도록 정의하는데 사용IMPORT: Pig 파일의 매크로를 호출하는데 사용 (재사용 가능한 Pig 코드를 매크로로 저장한 경우)
그 외 함수들과 로더들
AVG, CONCAT, COUNT, MAX, MIN, SIZE, SUM
PigStorage
TextLoader
JsonLoader
AvroStorage
ParquetLoader
OrcStorage
HBaseStorage
[Challenge] 1점을 가장 많이 받은 최악의 영화 찾기
- (1) 평균 평점이 2.0 미만인 모든 영화를 찾는다.
- (2) (1)에서 출력한 영화 리스트를 총 평점 수를 기준으로 정렬한다.
1 | ratings = LOAD '/user/maria_dev/ml-100k/u.data' AS (userID:int, movieID:int, rating:int, ratingTime:int) |