220424 데이터 파이프라인 스터디 13일차 (Zeppelin notebook을 사용한 분석 및 Spark로 가공한 데이터를 Amazon RDS(MySQL)에 저장)
이번 포스팅에서는 저번 시간에 이어서 Zeppelin을 사용해서 데이터를 처리실습을 한 내용을 정리해볼 것이다. Zeppelin은 Interpreter로, 다양한 Interpreter를 제공해준다고 했는데, Spark도 그 중에 하나로 포함이 되어있다. 그래서 이전 시간에 실습했던 것처럼 s3 bucket에 있는 csv format의 파일을 spark.read에 여러 option을 붙여서 DataFrame 객체로써 저장을 할 수 있었다.
이 Apache Zeppelin에서 DataFrame을 조작해보면서 느낀점은 이전에 해봤던 Pandas의 DataFrame 조작과 매우 비슷한 부분이 많다는 것이다. Spark로 만든 DataFrame 변수로는 View Table을 정의할 수 있는데, 이 임시로 정의한 View Table을 활용해서 SQL query를 실행시킬 수도 있다.
그리고 DataFrame format의 데이터를 JSON format의 데이터로 S3 bucket에 저장을 할 수 있으며, S3에 저장된 JSON format의 데이터를 spark.read.json()으로 다시 DataFrame 형식으로 불러올 수 있다.
이정도의 내용을 저번 시간에 간단하게 실습을 해보았다.
TextFile 변환
JSON, Parquet, CSV의 경우에는 기본적으로 DataFrame으로 만들기 쉬운 골격을 가지고 있는 반면에, 텍스트 파일 형태의 데이터의 경우에는 DataFrame으로 만들기 위해서 많은 작업이 필요하다. (비정형 데이터 -> DataFrame)
이제 마지막 추가/삭제되는 parameter 용도의 JSON 데이터를 제외한 부분을 DataFrame format의 데이터로 transform해주기 위한 함수를 작성해줘야 한다. 아직 scala에 대한 구체적인 문법은 모르지만, 대략적으로 현재 작성되는 코드가 어떤 부분을 위한 작업인지는 알 수 있기 때문에, 차후에 scala 문법을 배우면서 코드를 다시 작성해보기로 하자. scala로 작성되어있는 코드는 Python 코드로 작성을 해보자.
defparseRawJson(line: String) = { // '|'(pipe)를 기준으로 각 line을 split해주고, val pieces = line.split("\\|") // 각 index 요소의 값을 별도의 변수에 담아 저장한다. val adid = pieces.apply(1).toString val uuid = pieces.apply(2).toString val name = pieces.apply(3).toString val timestamp = pieces.apply(8).toString val gtmTimes =pieces.apply(7).toString //JSON Parse val jsonString = pieces.apply(9).toString implicitval formats = DefaultFormats val result = parse(jsonString)
var screen_name = (result \ "screen_name").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") var item_id = (result \ "item_id").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val content_type = (result \ "content_type").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val item_category = (result \ "item_category").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val is_zb_agent = (result \ "is_zb_agent").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val building_id = (result \ "building_id").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val area_type_id = (result \ "area_type_id").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val agent_id = (result \ "agent_id").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val button_name = (result \ "button_name").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val status = (result \ "status").extractOpt[String].getOrElse("NULL").replaceAll("nil", "NULL") val base_date = timestamp.substring(0,10)
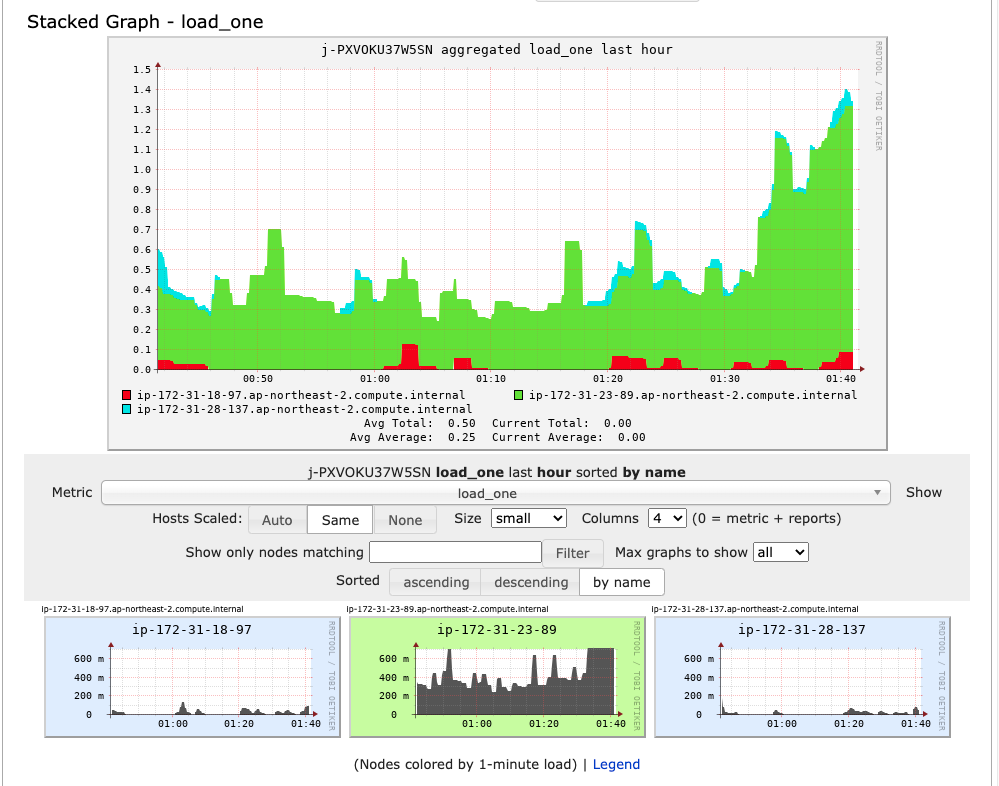
Zeppelin을 통해서 데이터 분석을 하면서도 중간 중간에 현제 workload가 어떻게 되는지, 현재 작업 노드로는 부하상태는 괜찮은지에 대해서 분석을 하면서 진행해야한다. 위의 캡처를 보면 하단에 총 3개의 노드가 실행되고 있다. Master node, Core node, Task node 각 각 1개씩 할당이 되어있기 때문에 위와같이 총 3개의 노드가 모니터링 되고 있는 것이다. 만약 클러스터의 부하에 문제가 생기면, 노드를 새롭게 추가(scale-out)해주는 등의 해결책을 내어서 문제를 해결하면서 데이터 분석작업을 이어나가야 한다.
Spark + RDS
Spark에서 가공한 데이터를 RDS의 MySQL에 저장하는 작업을 실습해볼 것이다.
RDS
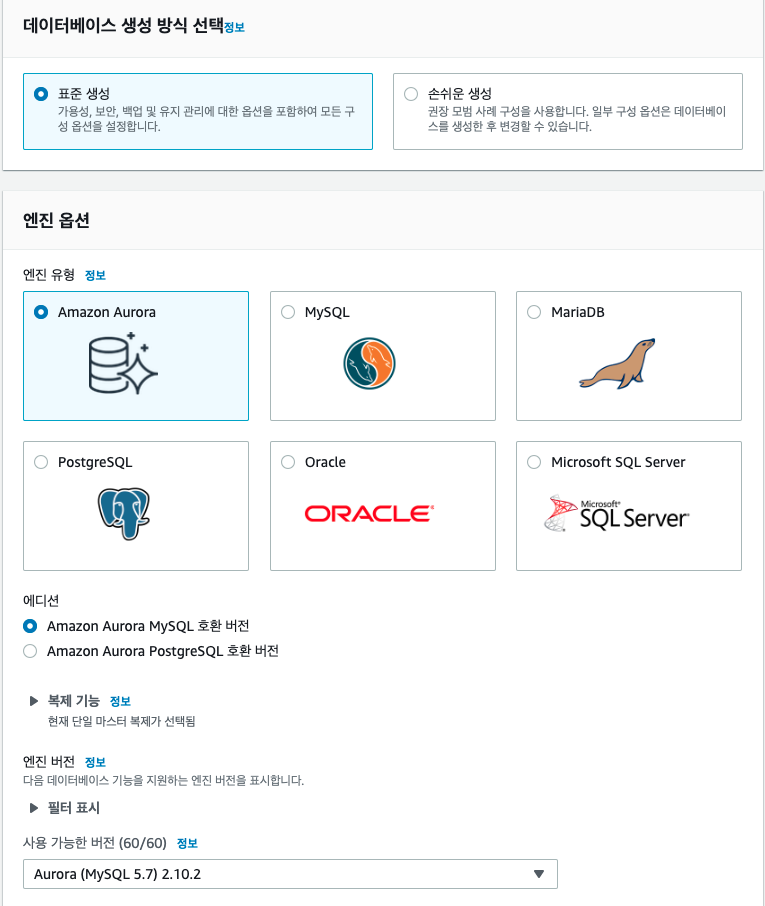
Amazon Aurora MySQL 생성
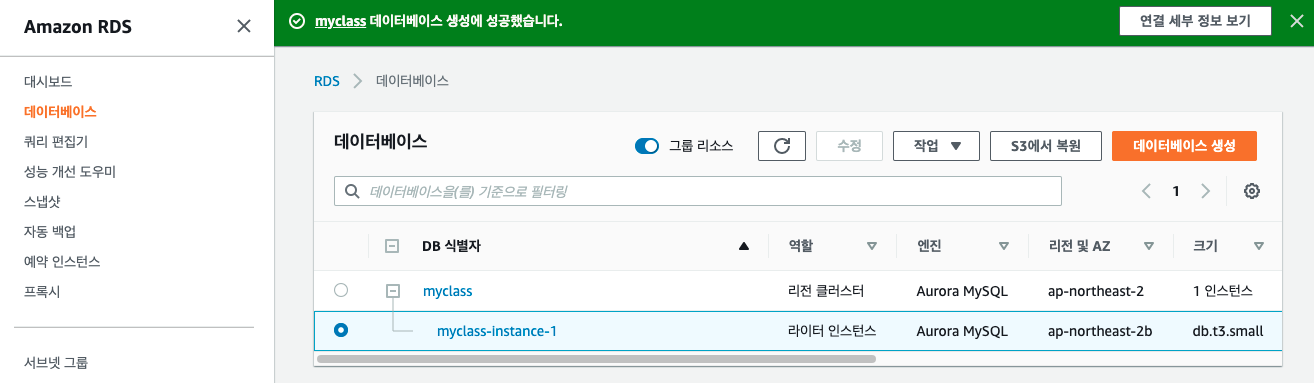
데이터베이스 인스턴스를 생성하게 되면, region cluster 하위에 writer instance가 하나 생성이 됨을 확인할 수 있다.
생성된 database의 writer instance의 엔드포인트를 사용해서 Spark를 사용해서 전처리한 데이터를 RDS 데이터베이스에 저장을 할 수 있다.
이제 생성한 Amazon RDS EndPoint를 host로 해서 client program에서 cloud의 RDS DB에 접속을 한다. 접속을 한 뒤에 DW(Data Warehouse) 개념의 DB 저장소를 하나 만들고, DM(Data Mart) 개념의 DB 저장소를 하나 만들어서 기본 환경구성을 해놓는다.
이제 Amazon EMR에서 가공한 데이터를 내보낼 target에 대한 setting이 끝났기 때문에 이제 다시 Amazon EMR에서 어떻게 전처리한 데이터를 target 지정을 해서 내보내는지에 대해서 알아보도록 하겠다.