이번 포스팅에서는 이전 시간에 이론적인 부분을 학습한 EMR을 직접 실행해보고 모니터링해보면서 학습한 부분에 대해 포스팅해보려고 한다.
EMR 서비스
처음 EMR 서비스 대시보드에는 아무것도 보이지 않지만, 기본적으로 보이는 클러스터 history 정보의 경우에는 default로 두 달 정도 보여주며, optional하게 노출 기간의 변경이 가능하다.
저렴하게 EMR 서비스 이용
- 고급 옵션으로 이동
- EMR은 관리형 클러스터이기 때문에 여러가지 소프트웨어를 옵션으로 설치할 수 있다.
(emr-6.x : Docker/Kubernetes를 같이 실행할 수 있는 환경을 지원)
- EMR은 관리형 클러스터이기 때문에 여러가지 소프트웨어를 옵션으로 설치할 수 있다.
- 소프트웨어 선택
- Hadoop, Ganglia, Hive, Zeppelin, Spark, Pig 선택
- cf. Zippelin : 웹 환경에서 Spark에 여러가지 command를 통해서 job을 던진다.
- cf. Livy : 어플리케이션 간에 Spark에 job을 던질때 사용되는 것이 Livy이다.
- AWS Glue catalog setting
- Glue는 S3에 저장된 정보의 meta정보를 테이블 형태로 관리하는 것을 말한다.
- 클러스터 생성
- 하드웨어 구성
- Networking
- VPC : 하나의 건물로 이해 / subnet은 각 층으로 이해 (스팟을 제공하는 subnet이 따로 있는 경우가 있기 때문에 확인 필요)
- Cluster Nodes and Instance
- Instance type : spark 자체는 메모리 기반 데이터를 분석하는 툴이다. 따라서 메로리에 좀 더 최적화된 인스턴스 타입을 선택한다. (r-> ram -> memory 기반의 인스턴스, c -> computing, g -> gpu, i -> disk 최적화(
데이터 분석시에도 고려되면 좋음))
- Instance type : spark 자체는 메모리 기반 데이터를 분석하는 툴이다. 따라서 메로리에 좀 더 최적화된 인스턴스 타입을 선택한다. (r-> ram -> memory 기반의 인스턴스, c -> computing, g -> gpu, i -> disk 최적화(
- Networking
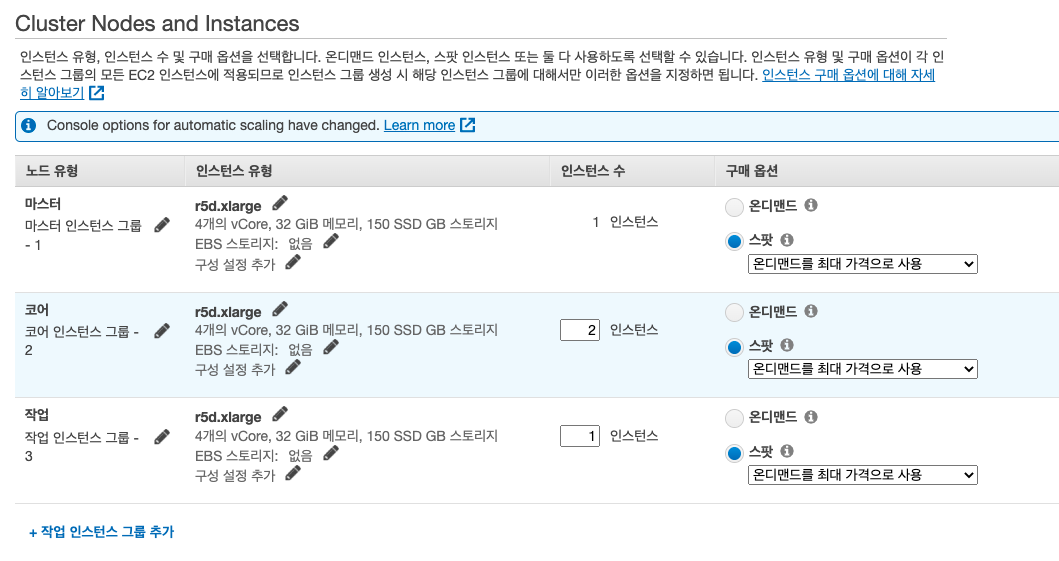
worker node(코어 + 작업 노드)의 합은 홀수가 되는 것이 좋다. job을 수행할 때 경쟁이 생기지 않게 하려면, 홀수가 되도록 설정하는 것이 좋다고 data bricks에서 recommend하고 있다.
- on-demand : EC2를 구매해서 사용하는 형태
- spot : 각 zone에 남아있는 유효장비를 사용하고자 하는 고객들에게 bidding을 붙여서 사용하게 하는 것(70~90% 저렴하게 사용 가능)
기본적으로 Amazon EMR은 관려형 서비스이기 때문에 생성한 Master, Core, Task node의 수만큼 EC2 dashboard에 가보면 인스턴스가 생성된 것을 확인할 수 있다.
[EMR Master node 작업을 위한 EC2 키 페어 설정]
Amazon EMR 클러스터에서 작업을 할때에는 Master node에 접근을 해서 작업을 하는 경우가 많다.
모든 설정이 완료된 후에는 7 - 10분정도 후에 클러스터를 쓸 수 있는 상태로 전환이 된다.
Zeppelin에서 Spark coding을 위한 port setting
web 상에서 Zeppelin을 통해서 Spark을 coding하려면 8890 port에 접근할 수 있어야 한다. 이 부분에 대해서 Master node의 security group의 inbound rule에 새로운 규칙을 추가하도록 한다.
[보안 및 액세스 - 마스터 / 코어 및 작업 노드 보안 그룹 관리]
Master/Core 및 Task node의 security group 관리를 위해서는 클러스터 대시보드에서 요약탭의 "보안 및 액세스" 부분을 통해 관리한다.
[단계] 탭
클러스터를 구성한 이후에
클러스터를 구성한 다음에 특정 TASK(드라이브 설치 혹은 job 실행)를 실행하도록 할 수 있다.
ex) DB에 접속할 수 있는 드라이버를 자동으로 설치하고 싶은 경우, TASK 추가
[부트스트랩 작업] 탭
클러스터를 구성하기 이전에
미리 설치하기 위한 어플리케이션이나 스크립트가 있는 경우 사용
하둡 클러스터 종료
하둡이 HDFS로 구성이 되어있는데, 클러스터가 종료가 되면, 모든 데이터는 사라지게 되고, 구성했던 내용만 남게 된다.
종료되면 EC2 인스턴스가 하나씩 내려가게 된다.
2022/04/22 업데이트
Amazon EMR 모니터링
Amazon EMR 구성요소 중에서 Spark를 사용한 데이터 분석을 Ganglia를 사용해서 모니터링을 할 수 있다.
[monitoring을 통한 확인 및 판단]
- Process는 총 몇 개가 돌고 있는지에 대한 확인
- 어느경우에 scale-out / scale-in 해줘야되는지?
[EMR on EC2] - Clusters
클러스터 이력(history) 목록에서 종료된 클러스터 항목을 clone함으로써 종료된 클러스터를 재 실행시킬 수 있다. (주의해야될 점은 설정 언어가 한글인 경우에는 Cluster node instance의 구매 옵션이 spot으로 변경해서 설정한 부분이 수정되지 않은 경우가 있는데, 이 부분은 원래대로 spot으로 수정을 시켜줘야한다)
만약에 에러가 발생하는 경우에는 Cluster의 "Steps" 탭에서 새로운 Step을 추가해준다. 이미 이전에 언급했듯이, 모든 클러스터 구성을 완료된 후에 새로운 라이브러리를 추가 설치하는 과정을 위한 부분이 이 Steps 탭이다.
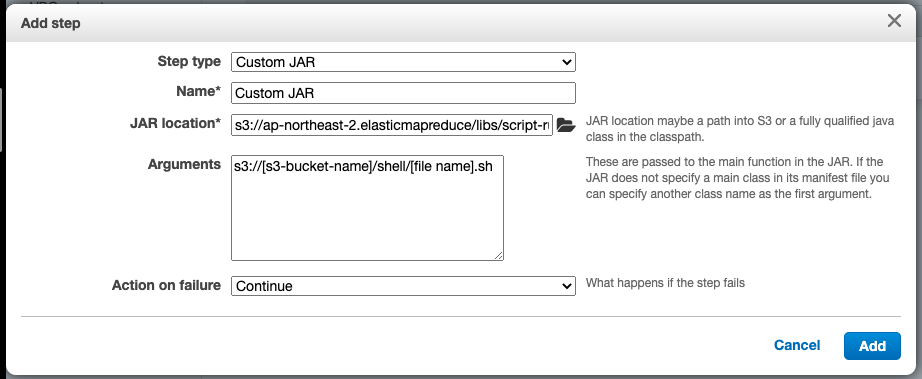
아래는 Ganglia에 접속이 안될 경우 해결을 위한 script이다. deny를 allow로 설정을 바꿔주고 httpd서비스를 재구동한다. (아래 스크립트는 위의 Arguments의 S3 Bucket내의 *.sh파일의 내용이다)
1 | if [ -f "/etc/httpd/conf.d/ganglia.conf" ]; then |
JAR 위치는 아래와 같이 region에 대한 값을 제외하고 주어진다.
SHELL을 실행할 수 있게 해주는 script-runner.jar 파일에 대한 정의부분이다.
1 | s3://<region>.elasticmapreduce/libs/script-runner/script-runner.jar |
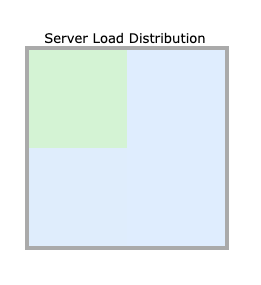
Ganglia 모니터링
Ganglia에서 좌측의 Server Load Distribution 부분에서 서버가 과도하게 과부하가 걸리게 되면, 주황색이나 빨색으로 바뀌게 되는데 scale out을 통해서 순조롭게 돌도록 구성을 해주면 된다. Spark같은 경우는 중간에 노드를 늘리더라도 그 노드의 마스터 노드가 Task를 저압을 가지고 있다면 새로 생성된 노드에 작업할당을 해주기 때문에 중간에 클러스터를 scale out을 해줘도 괜찮다.
Apache Zeppelin
이전에 하둡과 친해지기 네 번째 이야기 블로그 포스팅에서 외부 데이터 스토리지 관련 내용에 대해서 정리를 하면서 잠깐 Apache Zeppelin에 대해서 언급을 했었다.Apache Zeppelin은 클러스터와의 상호작용과 사용자 인터페이스를 노트북 유형으로 접근하는 새로운 관점을 채택했다는 내용이었는데, 이 부분에 대한 실습을 해보았다.
Spark, DB, Presto와도 연동이 가능하다. 말 그대로 Zeppelin은 interpreter이기 때문에 Spark CLI에서 처리해야되는 부분도 손쉽게 웹 기반으로 처리할 수 있도록 도와주는 친절한 녀석이다.
- Python, Scala, R 등의 언어를 섞어가며 분석코드를 표현할 수 있고, 바로 실행하여 결과를 볼 수 있을 뿐만 아니라 생성된 데이터를 그래프로 시각화하여 볼 수 있다.
Bronze data —-(Amazon EMR)—-> Sliver data
Amazon S3에 적재되어있는 Bronze 데이터를 Amazon EMR을 활용해서 Sliver 데이터로 convert하는 작업
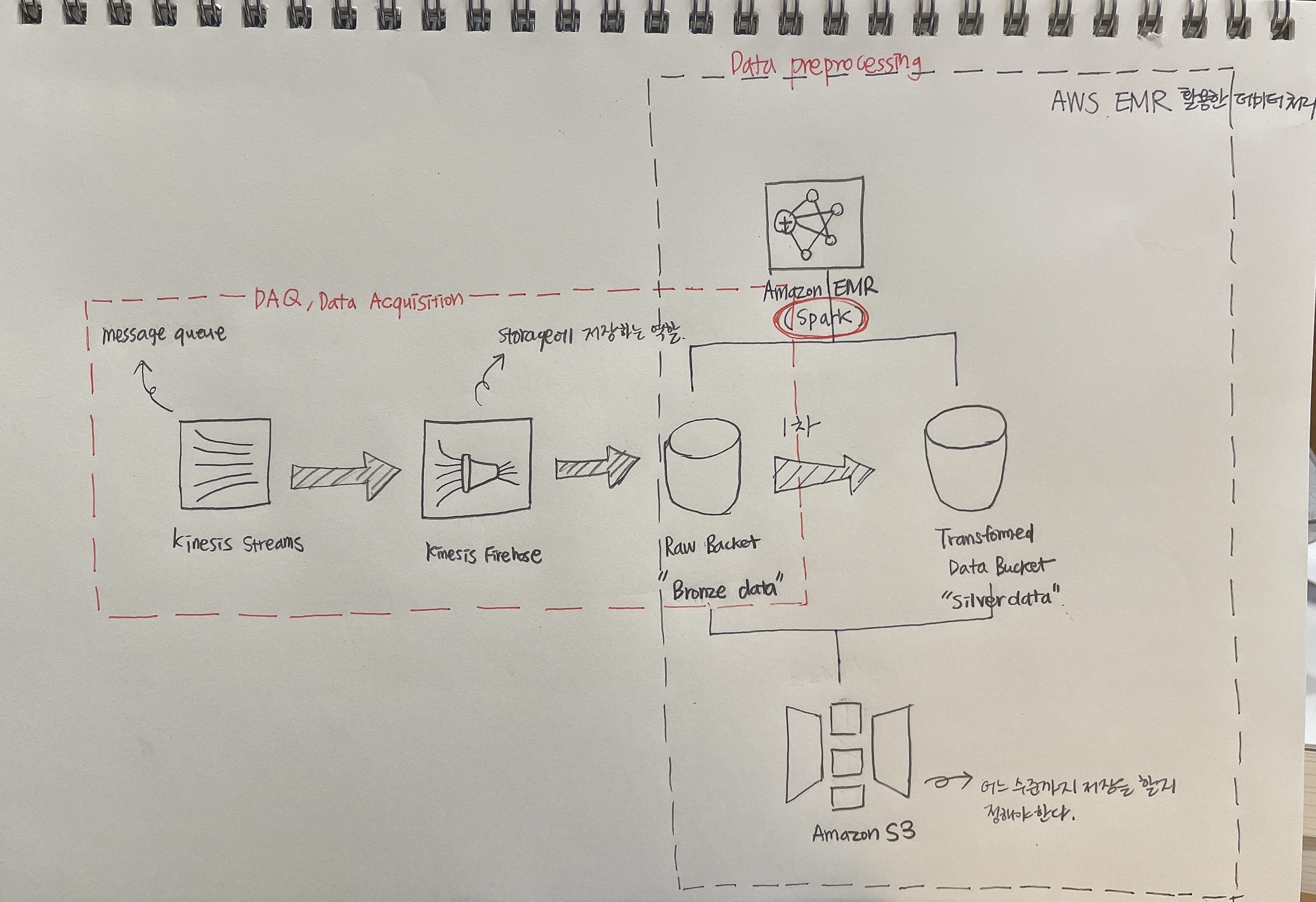
파일 분석시 데이터 포멧
온프레미스의 DBMS 데이터도 CSV 포멧으로 내려받고 DataFrame으로 convert하면, Spark SQL로 분석을 할 수 있는 환경이 된다. CSV 파일 여러개인 경우, 각 각을 테이블로 보고 조인을 해서 분석을 할 수도 있다.
결과는 RDBMS Data로 쓸 수 있고, Json Data, CSV Data 등의 데이터로 write할 수 있다.
- Parquet Data format : 칼럼 정보 뿐만 아니라 데이터가 가지고 있는 속성/타입도 줄 수 있다. 더 나아가 압축도 제공하며, 빅 데이터를 빠르게 분석할 수 있게 연구하는 단계에서 발생한 압축 파일이며, Zip파일에 비해서 떨어지지만, Spark에서 데이터를 읽을때 성능이 좋다.
Zeppelin Syntax 및 Analysis Error
SQL의 경우에는 둘 다 Runtime에서 검사를 해주며,DataFrames는 Syntax Error의 경우에는 Compile Time에서 검사를 해주고, Analysis Error는 Runtime에서 검사를 해준다.Datasets의 경우에는 둘 다 Compile Time에서 검사를 해준다.