이번 포스팅에서는 Amazon EMR에 대해서 알아본다. 이전 포스팅까지는 Kafka, Kinesis와 같은 message queue를 활용해서 분석할 데이터를 수집하는 것에 대해서 직접 파이프라인을 구성해보고 실습해보았다. 이번 포스팅에서는 Apache Hadoop과 Apache Spark와 같은 빅데이터 프레임워크 실행을 간소화하는 관리형 클러스터 플랫폼인 EMR(Elastic MapReduce)에 대해서 실습해본다.
분석할 대상이 되는 데이터가 요구하는 컴퓨팅 파워에 따라 클러스터를 쉽게 확장하고 축소할 수 있는 장점을 Amazon EMR은 가지고 있다. 그래서 이름에도 Elastic이 붙어있다.
이 Amazon EMR에서 파이프라인의 핵심 축이 되는 Spark의 활용법에 대해서도 집중적으로 정리를 해보자.
DataPipeline flow
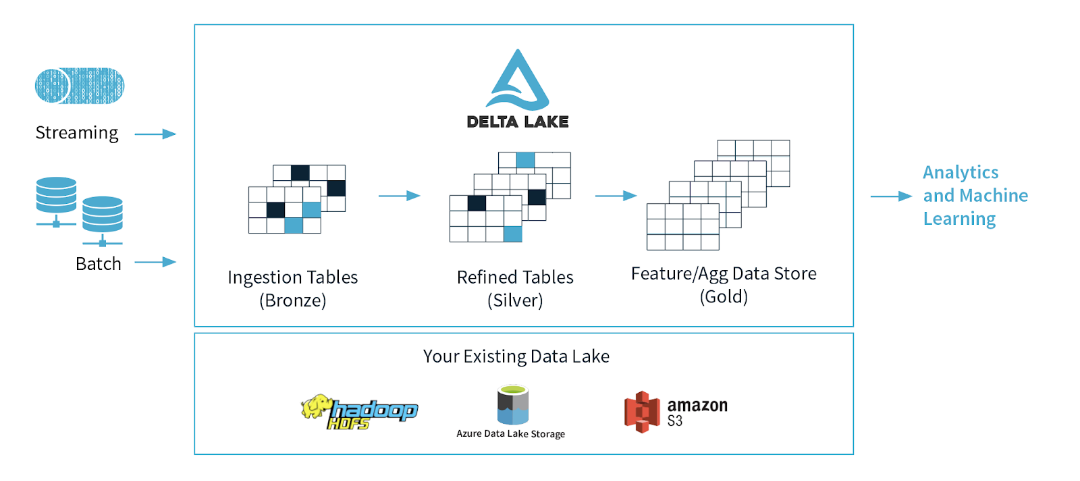
streaming이나 batch에 의해서 발생한 파일 데이터는 Bronze 데이터로써 저장이된다.
이 Bronze 데이터는 한 번 가공해서 테이블 형태로 저장을 하는데 이 데이터 형태는 DW(Data Warehouse)형태라고 하며, Sliver 데이터라고도 한다.
이 Sliver 데이터를 다른 사람이 분석하거나 시각화가 가능한 상태의 데이터로 가공하게 되면, 이 데이터를 DM(Data Mart)형태 혹은 Gold 데이터라고 칭한다.
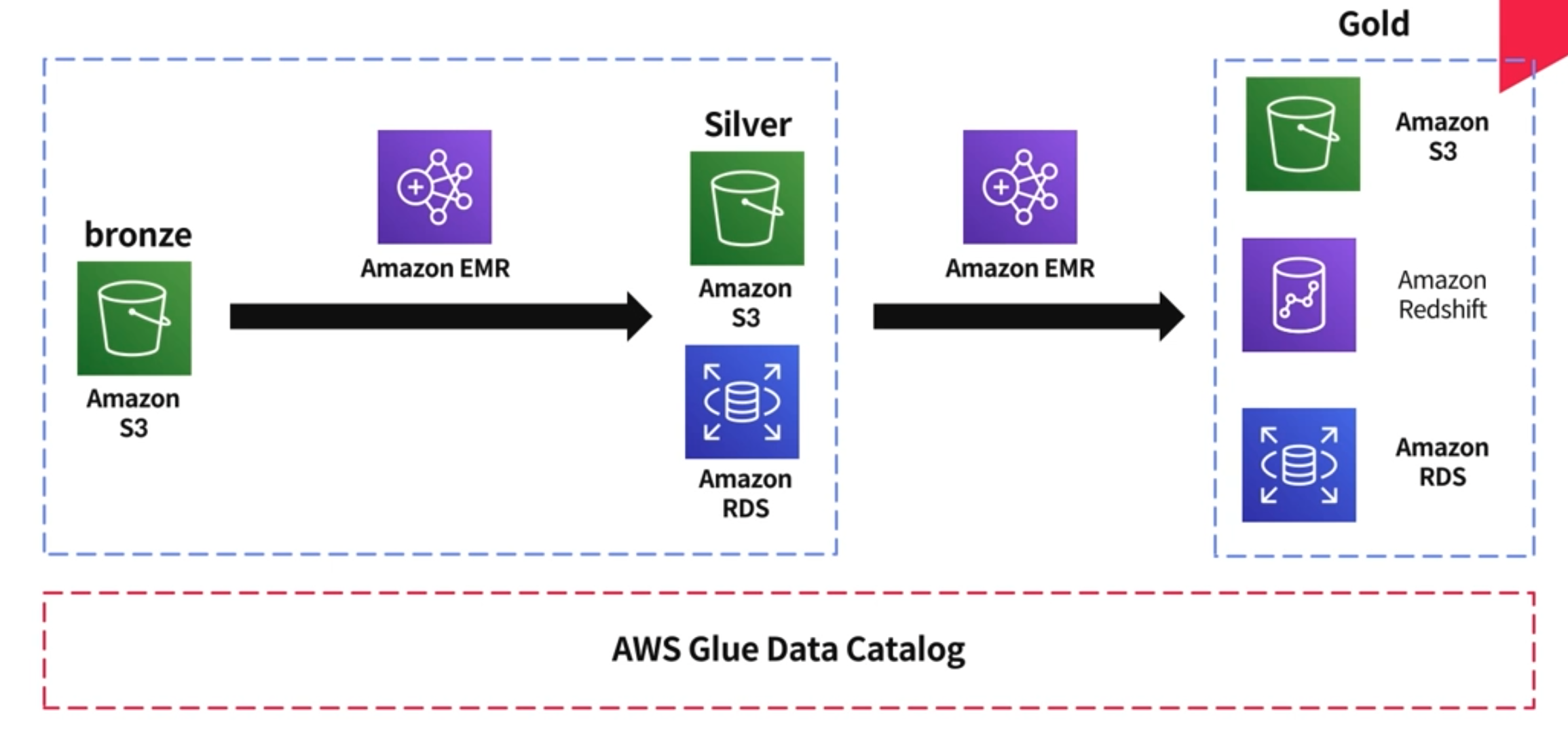
DataPipeline Sequence
(STEP 1) S3 bucket에 있는 데이터는 웹/앱/Batch에 의해 발생한 데이터이며, Bronze 데이터라고 한다.
상품/고객의 Transaction, 고객이 상품을 보았는지에 대한 데이터 등이 이에 해당한다.
(STEP 2) 앞서 STEP1에 있는 데이터가 한 번 가공을 해서 Silver 형태로 저장을 하게 되는데, 이때 사용되는 것이 바로 Amazon EMR 안의 Spark이다.
(STEP 3) 상품/고객 같은 경우에도 마스터성 데이터가 있다. 그 데이터를 S3에 넣고, 이벤트성 데이터는 보통 ID가 들어가있는데, ID를 푸는 작업을 한다. 그 이후에 Gold 타입의 데이터로 변화한다.
EMR 구조
Hadoop 구조를 가지고 있는 관리형 클러스터 플랫폼이다. 기본적으로 EC2 기반으로 구성을 하며, EC2에서 클러스터를 구성하기 위한 여러 서비스 요소들을 설치한다.
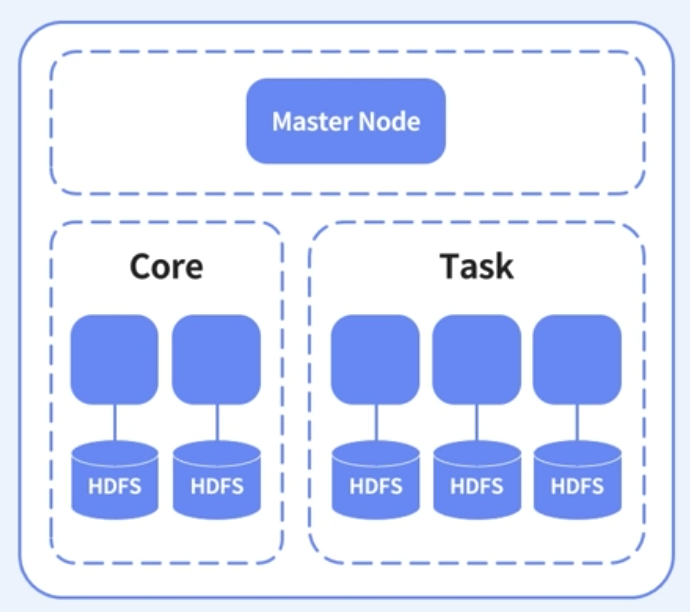
Master Node
- 클러스터를 관리
- 노드간에 데이터 및 작업의 분배를 조정
- 작업 상태를 추적하고 클러스터의 상태를 모니터링
Core Node(최근에는 Core Node없이 Master Node 자체만으로도 Jupyter notebook으로 구성할 수 있다)
- Data Node로, 클러스터의 HDFS에 데이터를 저장하는 노드이며, 하나 이상의 Core node가 있어야 한다.
Task Node
- Core Node와 비슷한 역할을 한다.
- Task Node는 HDFS가 없으며, 오직 compute resources만을 가진다. 따라서 Scale In/Out하기에 유용하다. (Optional)
HDFS로 S3를 사용하면 좋은점
- Computing Node와 Data Node를 서로 독립된 객체로써 운영함으로써 좋은 Architecture를 구성할 수 있다.
- 기존 HDFS의 경우에는 용량이 부족한 경우에는 용량에 대한 확인을 해서 확장을 해줘야했는데, S3의 경우에는 확장에 대한 신경을 쓰지 않아도 된다.
- 높은 내구성을 가진다.
- 유연하게 클러스터 내(S3)에서 필요에 따라 노드를 추가하거나 삭제할 수 있다.
- 클러스터를 종료 후에 다시 클러스터를 구성해도 기존의 데이터를 다시 읽을 수 있다.
- 여러개의 클러스터 서비스에서 데이터를 읽을 수 있다.(운영 EMR과 분석용 EMR에서 모두 사용 가능)
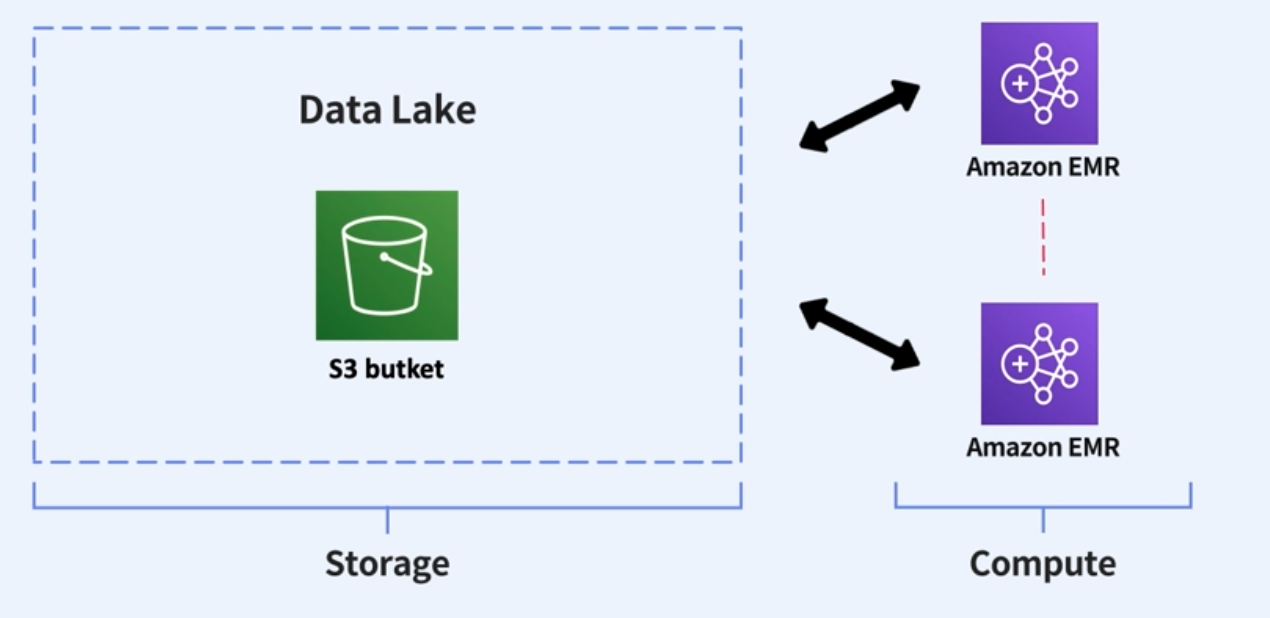
Storage 부분과 Compute 부분을 분리함으로써 복수 작업자간의 종속성 분리
- Storage 부분과 Amazon EMR(computing part)을 활용해서 Storage의 데이터에 Spark을 활용해서 동시에 접근을 해서 처리하는 형태로 구성을 할 수 있다.
(이전에는 큰 서버에 여러 분석가들이 접속을 해서 작업을 했었다. 그래서 큰 작업을 하는 작업을 하는 사람이 있는 경우에는 부하가 걸려서 다른 작업자에게 영향을 주었다. 하지만 위와같이 Storage와 Compute영역을 분리를 시키게 되면, 각 각의 작업자간의 종속성을 분리시킬 수 있다)
Amazon EMR(Elastic MapReduce)내의 다양한 서비스들
Amazon EMR 내에는 데이터 전처리 및 분석을 위한 여러 서비스들이 존재한다. 대표적으로 아래의 서비스들이 존재하며, 시간이 될때 찾아서 각 서비스들의 특징에 대해서 살펴보도록 하자.
- Presto
- Ganglia
- Hue
- oozie
- mahout
- TensorFlow