이번 포스팅에서는 Kinesis Stream + Kinesis Firehose + S3 전반적인 서비스 구성하는 방법에 대해서 정리를 해보고, 구성한 수집 파이프라인에서 sample data를 발생시켜서 수집 파이프라인에서 테스트해보는 과정까지 정리해보려고 한다.
Kinesis Stream 시스템 구성
API Gateway에서 어느 스트림으로 내보낼지 설정했던 Stream이름으로 Kinesis Stream 생성시에 이름을 정의한다. API Gateway에 비해 Kinesis Stream은 매우 간단하게 구축을 할 수 있다.
Kinesis Firehose 시스템 구성
Firehose는 Delivery streams 메뉴에 정의가 되어있다.
Delivery stream 메뉴에서 [Create delivery stream]을 클릭한 뒤에 아래의 하위 선택 목록들을 설정해준다.
[Choose source and destination]
- Source:
Amazon Kinesis Data Streams - Destination:
Amazon S3
[Source settings] - Kinesis data stream
- Browse - 앞서 생성한 Kinesis data stream Name을 선택
[Delivery stream name]
- 관리하기 용이하게 앞의 Kinesis data stream의 이름과 동일하게 재정의해준다.
[Transform and convert records] - optional
들어온 데이터를 Lambda에서 처리할 수 있도록 설정할 수 있다.
(별도의 Buffer size 도달시 Lambda가 실행되도록 설정)[Record format conversion]
- AWS Glue에 데이터 카탈로그에 데이터를 생성한 다음에 JSON방식으로 데이터를 삽입할 수 있는 옵션이다.
JSON에 Key값을 기준으로 각 Column에 데이터를 넣어준다.Apache Parquet, ORC는 빅데이터용 압축형식의 데이터이다. 칼럼형태의 포멧을 가지고 있으며, 조회할때 읽기 용이하게 되어있다.- Apache Parquet : 라이브러리를 안쓰고도 쓸 수 있게 상용화되어있다.
- ORC : 속도면에서 더 좋다
- AWS Glue에 데이터 카탈로그에 데이터를 생성한 다음에 JSON방식으로 데이터를 삽입할 수 있는 옵션이다.
[Destination settings]생성했던 S3 bucket을 선택해준다.
- [S3 bucket prefix] - S3 bucket에서 저장될 구체적인 위치를 지정해준다.
rawdata/ 이벤트가 발생하면 하위 path에 YYYY/MM/dd/HH filename 포멧으로 Firehose 통해서 저장이 된다.(UTC 시간 기준이기 때문에 일 단위의 데이터를 분석할 때 2일 단위로 데이터를 쌓아서 분석한다)
[Advanced settings]
- Permission 설정 부분으로, IAM 자체를 구성하기 힘들기 때문에, 자동으로 IAM을 생성해줄 수 있다.
(Firehose S3에 데이터를 쓰는 과정(서로 다른 서비스 간에 데이터를 쓰기 위해서)에서는 IAM 권한을 부여해줘야 Firehose에서 S3에 데이터를 쓸 수 있기 때문이다. 하지만, 회사에서는 반드시 IAM을 별도로 생성해서 자동으로 생성하지 않도록 해야한다)
[Tags]
- 이름을 구분하거나 리소스에 대한 사용을 파악하기 위해 각 서비스에 대해 Tag를 달아서 사용하는 것이 좋다. (파이프라인에서 발생하는 금액에 대한 파악에도 용이)
EC2 - API Gateway - Kinesis Stream - Kinesis Firehose - S3 수집 파이프라인에서 테스트
재기동하면 Public IP가 변경되기 때문에, 왼쪽 메뉴에서 Elastic IP (사용 안할때만 비용이 발생)를 사용하면 고정 IP를 사용할 수 있다.
1 | # json 형태의 데이터를 POST 방식으로 API Gateway END POINT로 쏴주는 명령어 |
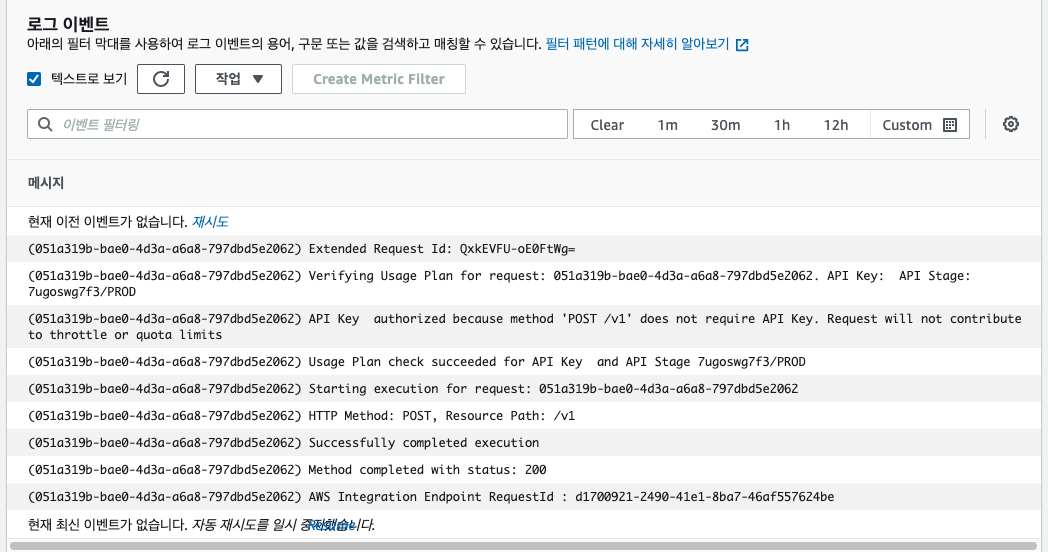
[데이터가 정상적으로 발송되었는지 CloudWatch에서 확인]
CloudWatch - [로그] - [로그 그룹] - API-Gateway-Execution-Logs
아래와같이 200코드를 받았다면, 정상적으로 API Gateway로 정상적으로 데이터가 넘어갔다는 의미이다.
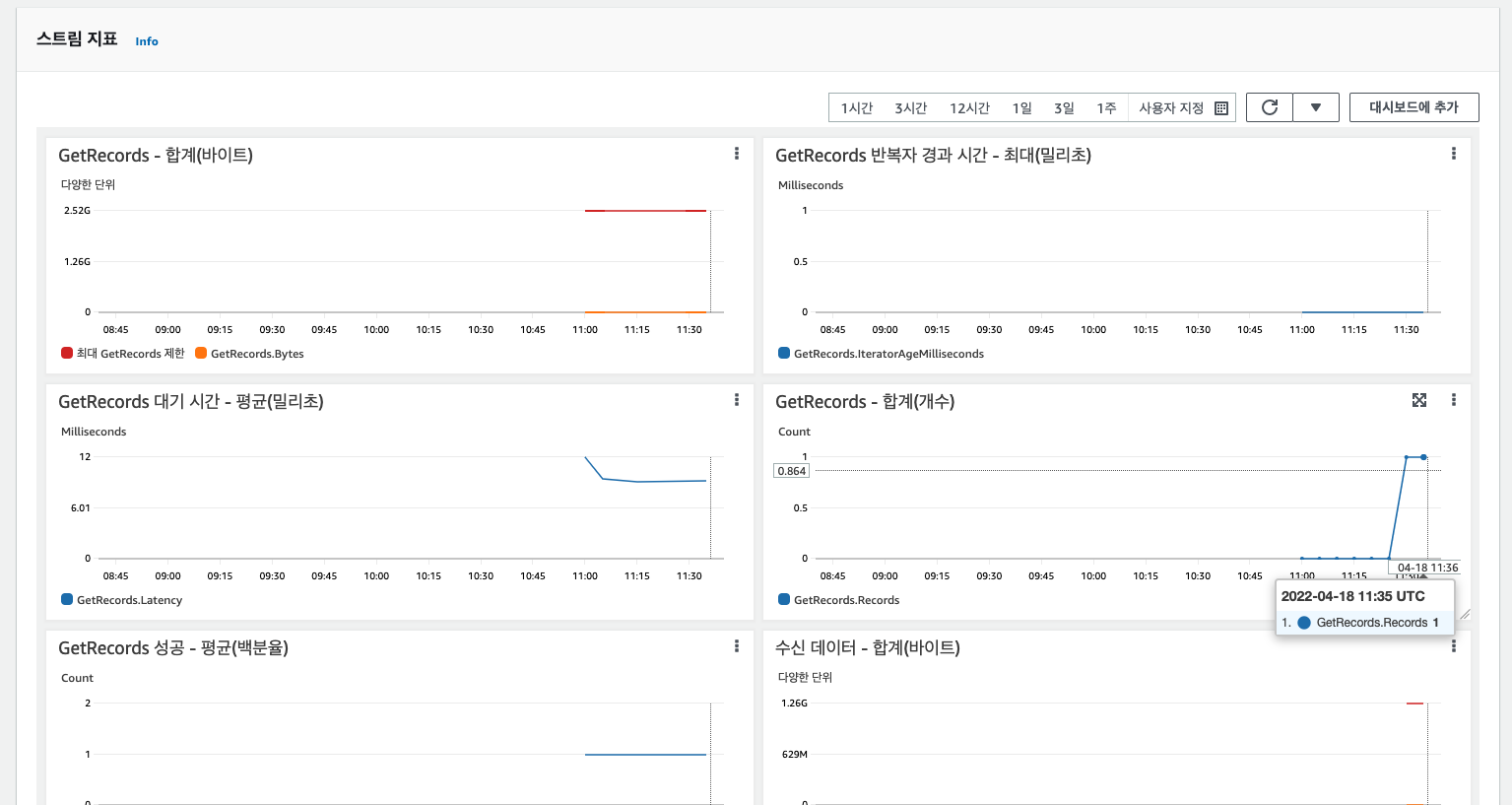
[Kinesis Stream에서 메시지 데이터가 전달되었는지 확인]
데이터 스트림 선택해서 API Gateway로부터 넘겨받은 메시지 데이터 확인
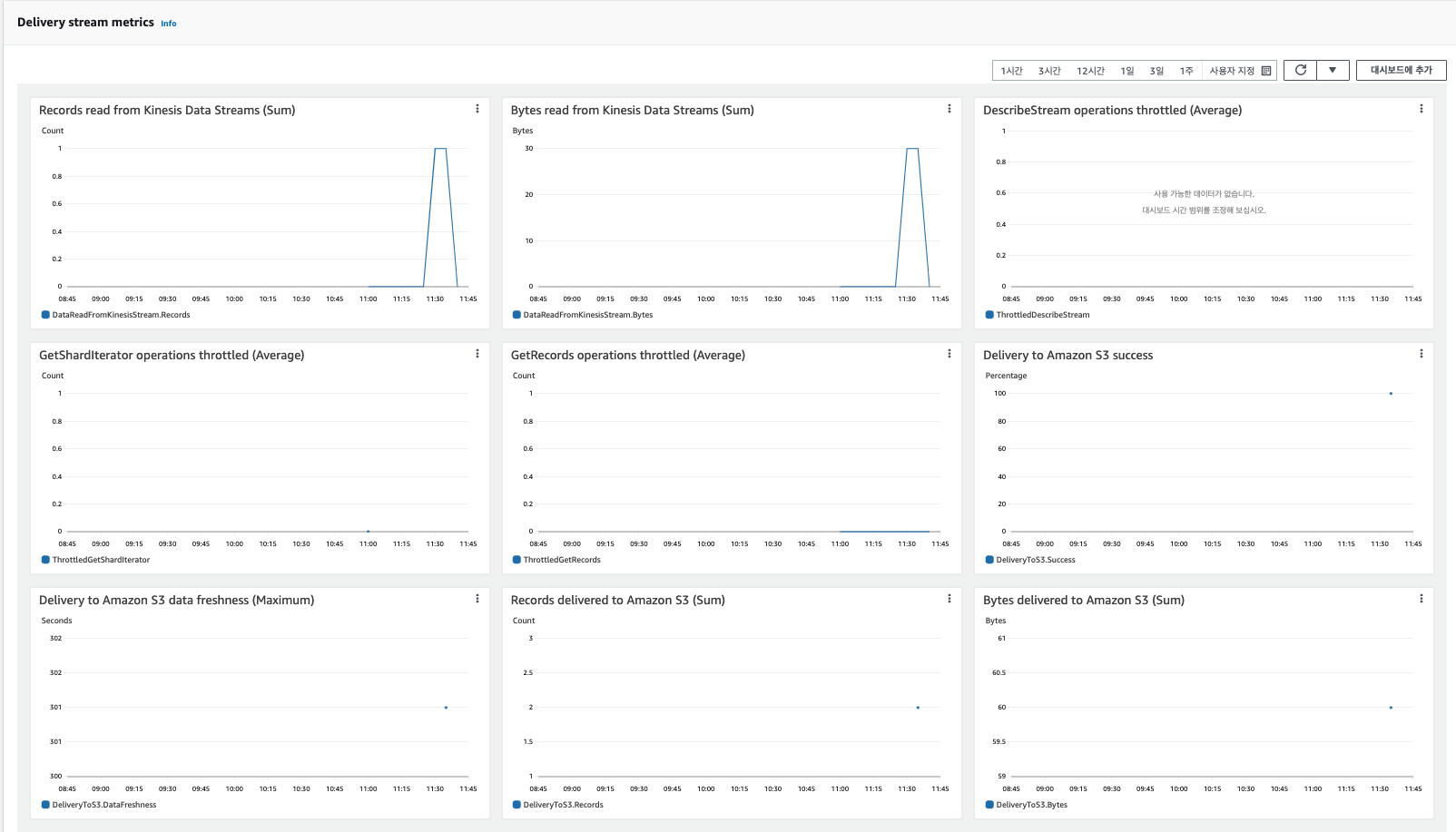
[Kinesis Hose에서 메시지 데이터 전달되었는지 확인]
Kinesis hose에서는 총 1개의 데이터 스트림을 받고, S3 object storage에는 2개의 데이터가 전달되었다는 것을 알 수 있다.
[S3(Destination)에 데이터가 제대로 전달이 되었는지 확인]
Kinesis stream에서 전송 스트림(kinesis hose)메뉴에 보면, Destination source로 이동할 수 있는 링크가 있는데, 이동하면 S3로 이동한 최종 데이터 파일을 확인할 수 있다.
파일명 format을 보면 알 수 있듯이, UTC 기준으로 시간이 되어있기 때문에, 시계열 그래프를 그리게 되면, 그래프가 짤리게 된다.(우리나라는 UTC+9) 따라서 2일 분의 데이터를 기준으로 시계열 그래프를 그려야한다.
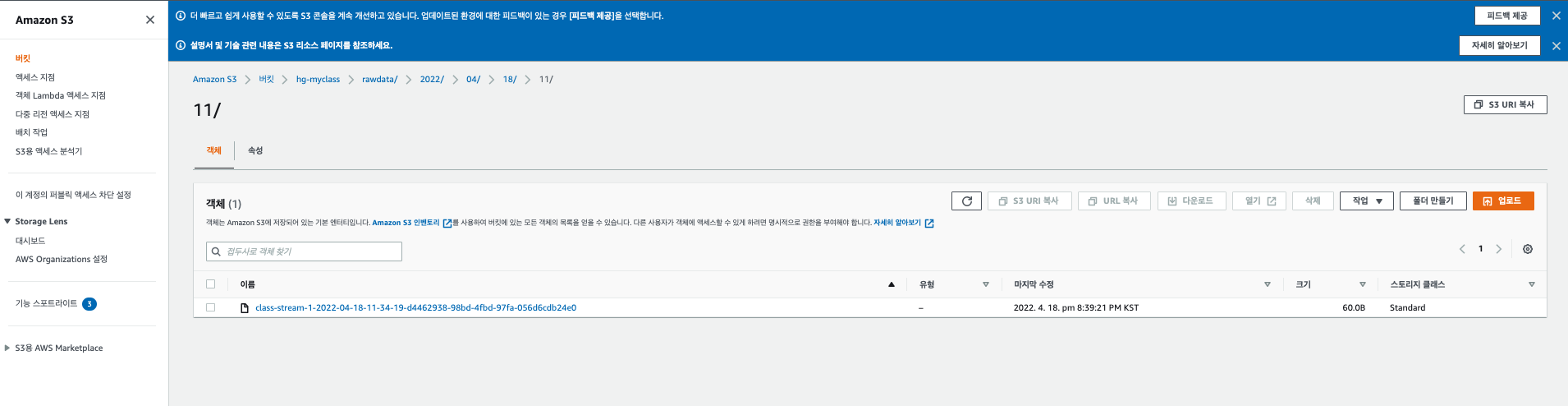
[S3(Destination)에서 파일 다운받아서 열기]
해당 데이터 파일을 클릭해서 열기를 클릭하면 브라우저상에서 다운로드가 되는데, 다운받은 파일을 열면 아래와 같이 전송한 연속된 두 개의 문자열 데이터가 쌓인 것을 확인할 수 있다.
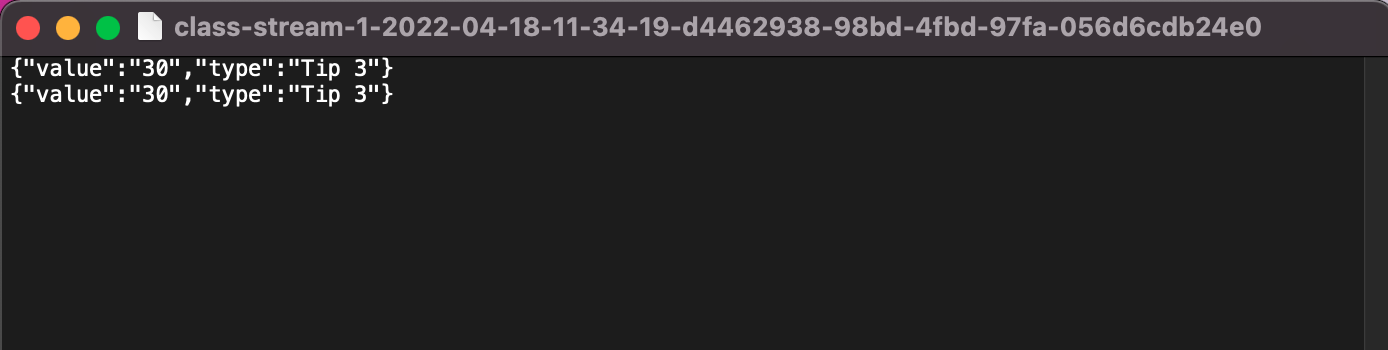
[테스트 파일을 활용해서 sample data 전송해보기]
실제로 대량의 데이터를 전송하는 경우, 비용이 많이 발생하기 때문에, 소량의 데이터로 테스트를 해본다.
(\*.jar 파일을 어떻게 작성하는지 한 번 공부해보기)
1 | java -jar sendPost.jar -f ../ods/danji_master.csv -u https://xxxxxxxx.execute-api.ap-northeast-2.amazonaws.com/PROD/v1 |