이번 포스팅에서는 앞으로 실습할때 사용하게 될 AWS인 API Gateway,Kinesis Stream, Kinesis Firehose에 대해서 공부한 내용을 정리해보겠다.
두 번째 실습내용
이번 실습에서는 AWS 서비스인 Object Storage 서비스 S3를 이해하고, 대규모 데이터 스트림을 실시간으로 수집하고 처리하는 Kinesis Stream을 사용하고 이해한다.
더 나아가 이전 포스팅에서 정리한 것처럼, 1주차에 배운 데이터 온프레미스 수집방법과 클라우드상에서 데이터를 수집하는 방법의 차이를 이해한다.
(1) 실습내용 : AWS 패키지들을 이용한 데이터 수집 실습
(2) 실습 구성 : Api-Gateway, Kinesis Stream, Firehose, S3의 이해(Simple한 데이터 수집방법 / 구체적으로 왜 이렇게 파이프라인을 구성했는지에 대해 이해한다)
(3) 실습환경 설정 : Kinesis Stream, Firehose, S3 설정하기
(4) 구성한 실습환경에서 데이터 수집 : AWS 서비스에서 데이터 수집하기
개인 실습에서는 웹/앱에서 데이터를 발생시킬 수 없기 때문에 간단하게 EC2에서 웹 접속하는 것과 똑같은 환경을 구성한다. (CLI에서 curl명령을 통해서 데이터를 생성하고, 테스트용으로 만든 데이터를 S3에 저장해서 실습한다)
API Gateway
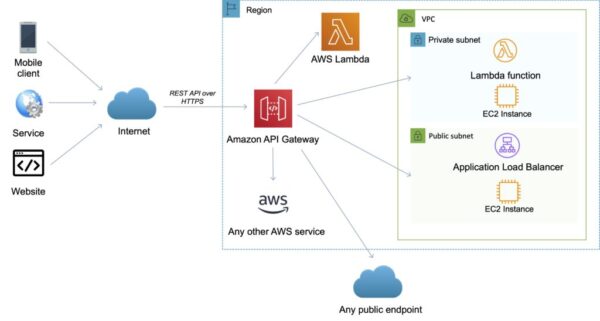
AWS에서 앱이나 웹을 개발할 경우에는 외부의 이벤트들(모바일/서비스/웹)을 AWS 서비스로 받아들이는 관문으로 이해하면 된다.
이벤트 같은 경우에는 백엔드에서 처리해도 되지만, 앱에서 발생하는 이벤트 중에서 백엔드의 자체 프로세스에서 처리되지 않는 이벤트(화면상에서 전환되는 이벤트)같은 이벤트도 처리하기 위해서 API Gateway를 사용해서 이벤트를 AWS 클라우드 안으로 받아들이도록 처리하기도 한다.
관련 서비스 050, 애드브릭스 등과 같이 최근 클라우드상에서 Parse 형태로 서비스되고 있는 서비스들이 있는데, 이벤트가 발생하면 바로 회사로 이벤트를 넘겨주는 데이터들도 있다.외부에서 발생하는 이런 데이터들을 내제화할때 사용을 꼭 해야되는 시스템으로 API Gateway가 사용된다.
모바일 및 웹 어플리케이션에서 AWS 서비스에 액세스할 수 있는 RESTFul API를 제공을 하며, 사용자는 RESTFul API를 생성, 구성, 호스팅하여, 어플리케이션의 AWS 클라우드 액세스를 지원한다.
Kinesis Stream
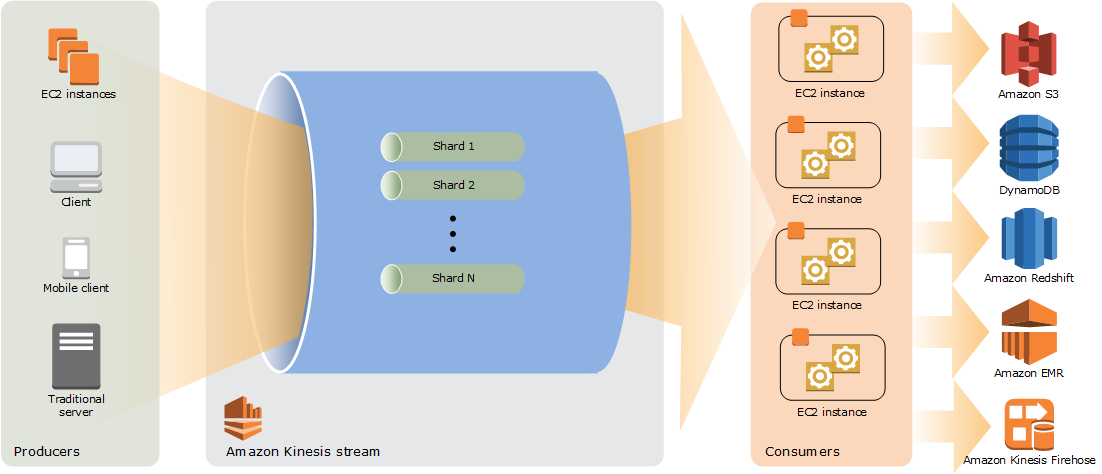
Kinesis Stream은 대규모 데이터 레코드 스트림을 실시간으로 수집하고 처리할 수 있다.
이벤트가 일정하지 않고 튀는 경우가 있어서 에러가 발생하는 경우가 있어서, 이벤트성으로 로그 데이터나 서비스가 폭주하는 경우에는 Kinesis를 사용하는 것이 좋다.
하나의 통로에 여러 병렬처리를 할 수 있도록 제공하는 것이 Shard이다. Kinesis Stream은 Shard를 늘릴때 숫자만 바꿔주면 병렬처리될 수있게 늘려줄 수 있고, 거기에 쌓인 데이터를 Kinesis Firehose를 통해서 위에 있는 Amazon S3, DynamoDB, Amazon Redshift, Amazon EMR 서비스로 보낼 수 있는 장점이 있다.
실무에서는 하루에 2500만건 발생을 하고, 이벤트는 하루에 한건 이상 발생을 하고, 이벤트 발생 포함해서 2500만건 데이터를 처리할때, 2개의 Shard가 사용이 되었다.
비용은 200불정도 소모되었다. (kinesis + Firehose 포함 비용)
Kinesis Firehose
Queue에 있는 데이터를 S3에 쉽게 저장할 수 있도록 도와주는 AWS 서비스이다.
Kinesis Firehose는 자체적으로 큐(Queue)의 기능을 가지고 있지만, 큐(Queue)라기보다는 버퍼(Buffer)이다. 버퍼사이즈가 그렇게 크지 않기 때문에 대규모 서비스에 사용하기에는 무리가 있다. 따라서 앞단에 kinesis stream을 두고 뒷 단에 Kinesis firehose를 사용한다.
이벤트가 크지 않은 경우에는 특정 버퍼링도 가능하기 때문에 firehose만으로도 가능하다.
Firehose가 나오기 전에는 Lambda를 통해서 S3에 저장을 하거나, DynamoDB나 MySQL DB에 저장을 하는 서비스를 운영하였다.
Lambda의 경우에는 정상처리 코드(200)가 떨어지지 않으면 4번까지 re-try를 하기 때문에 데이터 중복이 발생할 수 있기 때문에 데이터 중복에 대한 가정을 하고 파이프라인을 운영하는 것이 중요하다.(클렌징 작업 필요(주의))
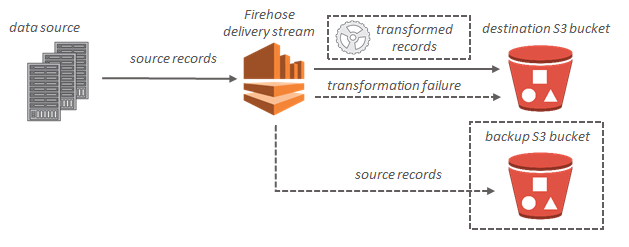
Amazon S3 대상인 경우에는 스트리밍 데이터가 S3 bucket으로 전송되고, 데이터 변환이 활성화되면 선택적으로 소스 데이터를 다른 S3 bucket으로 백업할 수 있다.
(format이 JSON 형태일때에는 Redshift나 Elasticsearch에 저장이 가능하다)
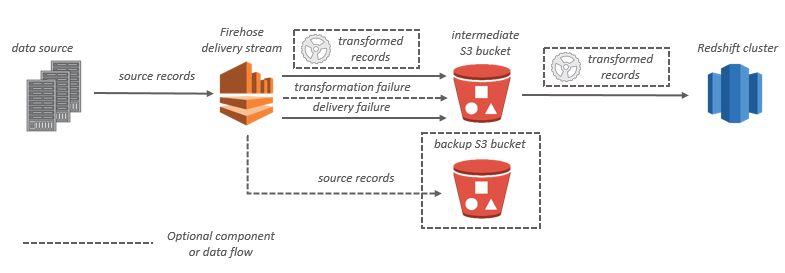
Amazon Redshift 대상인 경우에는 스트리밍 데이터가 먼저 S3 bucket으로 전송이되고, 그 다음에 Kinesis Data Firehose가 Amazon Redshift 발행 Copy 명령을 사용하여 S3 bucket의 Amazon Redshift 클러스터로 데이터를 로드한다. 데이터 변화이 활성화되면, 선택적으로 소스 데이터를 다른 Amazon S3 bucket으로 백업할 수 있다.
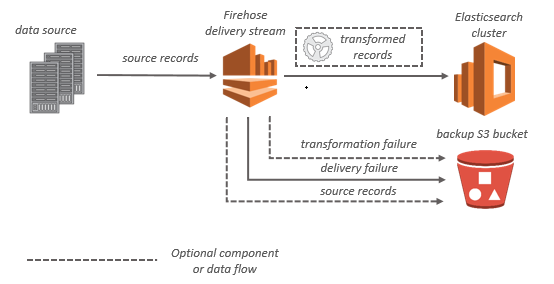
Elasticsearch cluster 대상인 경우, 스티리밍 데이터가 Elasticsearch cluster로 전송이 되며, 동시에 선택적으로 S3 버킷에 백업을 할 수 있다.
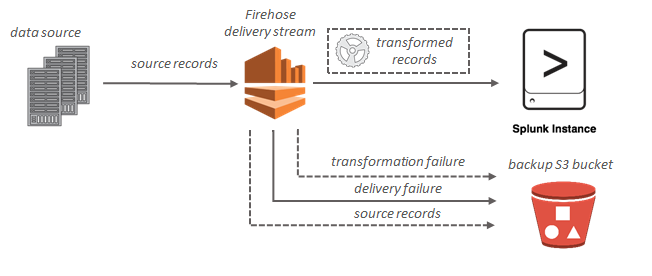
Splunk 대상인 경우, 스트리밍 데이터가 Splunk cluster로 전송이 되며, 동시에 선택적으로 S3 버킷에 백업할 수 있다.
(2022/05/10 업데이트)
참고)splunk란 모든 소스의 머신 데이터(machine data)를 실시간으로 수집하고 분석하는 가장 뛰어난 운영 인텔리전스 플랫폼이다.
수집하는 데이터의 비즈니스 유형에는 제약을 두고 있지 않으며, 모든 장비/모든 서버/모든 장치에서의 정형/비정형 데이터를 수집할 수 있다. 수집된 데이터를 규칙에 따라 분석하고, 분석된 자료를 기반으로 시각화하여 사용자에게 객관적인 지표를 제공할 수 있다.데이터 수집부터 보고까지 전 과정을 제공하며, 수십 TB까지 다양한 규모의 데이터 처리가 가능하다. splunk는 빅데이터를 통해 인사이트를 얻을 수 있도록 도와준다.
모니터링 툴이나 third part tool과의 연동도 많이 지원을 한다. Third part tool과 연동을 할때에도 백업은 S3에 한다.
[출처] : https://docs.aws.amazon.com/ko_kr/firehose/latest/dev/what-is-this-service.html
저장 Architecture
- 저장 용량이 무제한 (S3)
- 요청에 의한 데이터 파이프라인을 쉽게 구성하고 데이터 수집 및 저장이 가능
- 요청이 많아져도 Kinesis Stream의 Shard 조정만으로 빠른 scalability 처리
- 데이터 유실에 대한 kinesis Stream에서 기본적으로 24시간의 데이터보존기능
- S3에 반 정형화된 JSON 형식의 데이터로 저장하므로, 가변적 값의 데이터 수집(Query Parameter 값이 변화에 대해서)에 대한 유연한 분석이 가능
(이벤트가 발생하는 데이터를 저장할때 저장하는 포멧을 JSON으로 저장하자. 데이터 분석가와 같이 일을 하면, 앱에서 발생하는 이벤트 중에서 특정 이벤트에 데이터를 같이 넘겨줬으면 하는 요구사항이 있는 경우가 있다.(혹은 삭제) JSON 형태로 저장을 한다면, 손쉽게 데이터 조작이 가능하다. (과거에는 테이블 형태로 관리되어 데이터 조작이 어려웠다) - Serverless의 운영비용 감소