이번 포스팅에서는 이전에 작성했던 Python으로 작성한 MapReduce 코드를 HDP 2.6.5 환경에서 구동시켜볼 것이다. Hadoop을 사용하지 않고, local에 copy된 dataset을 가지고 로컬에서 실행해보고, Hadoop을 기반으로 실행해보는 두 가지 방법으로 실습을 해볼 것이다.
HDP2.6.5에서 MapReduce 실습환경 구축
[STEP1] 가장 먼저 VirtualBox에 올린 HDP2.6.5 OS Image를 구동시킨다.
[STEP2] Putty를 사용해서 가상 OS환경에 접속한다.
[Putty host/port configuration]
1 | host: maria_dev@127.0.0.1 |
[STEP3] PIP 설치를 위한 SETUP
1 | # root 계정으로 switch |
[STEP4] 실습에 필요한 DATASET 및 Python source code 준비
1 | # nano editor 설치 (or vi editor 사용해도 됨) |
[STEP5] MRJob프레임워크를 사용해서 MapReduce 실행하기
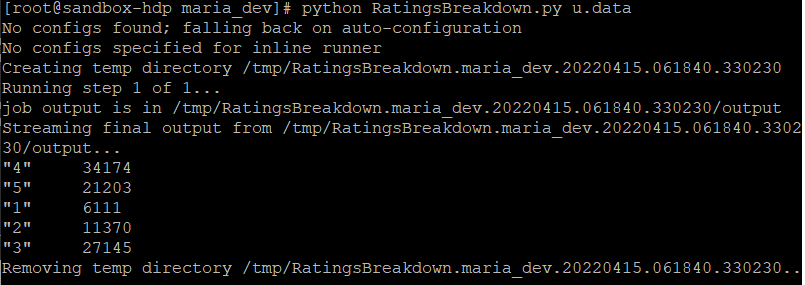
MRJob 프레임워크를 사용해서 MapReduce를 실행하는 방법에는 총 두 가지가 있다.첫 번째는 Hadoop을 전혀 사용하지 않고 로컬에서만 실행하는 방법이다. MRJob 프레임워크를 사용해서 MapReduce를 시뮬레이션한다. 개인 PC에서 여러가지를 테스트하기에 유용한 방법이다.
Hadoop 클러스터에서 개발하는 대신에 텍스트 에디터(nano, vi 등)를 사용해서 데스크톱에서 개발을 할 수 있다. 아래는 로컬 환경에서 MRJob 프레임워크를 사용해서 MapReduce를 실행하는 방법이다.
1 | # 스크림트 파일과 입력 데이터 파일을 입력 |
(개인 PC에서 실행하는 경우에는 방대한 데이터 세트 전체를 사용하지 않고, 때때로 테스팅이나 개발 목적으로 데이터의 부분집합을 만드는 것도 좋은 방법이다.)
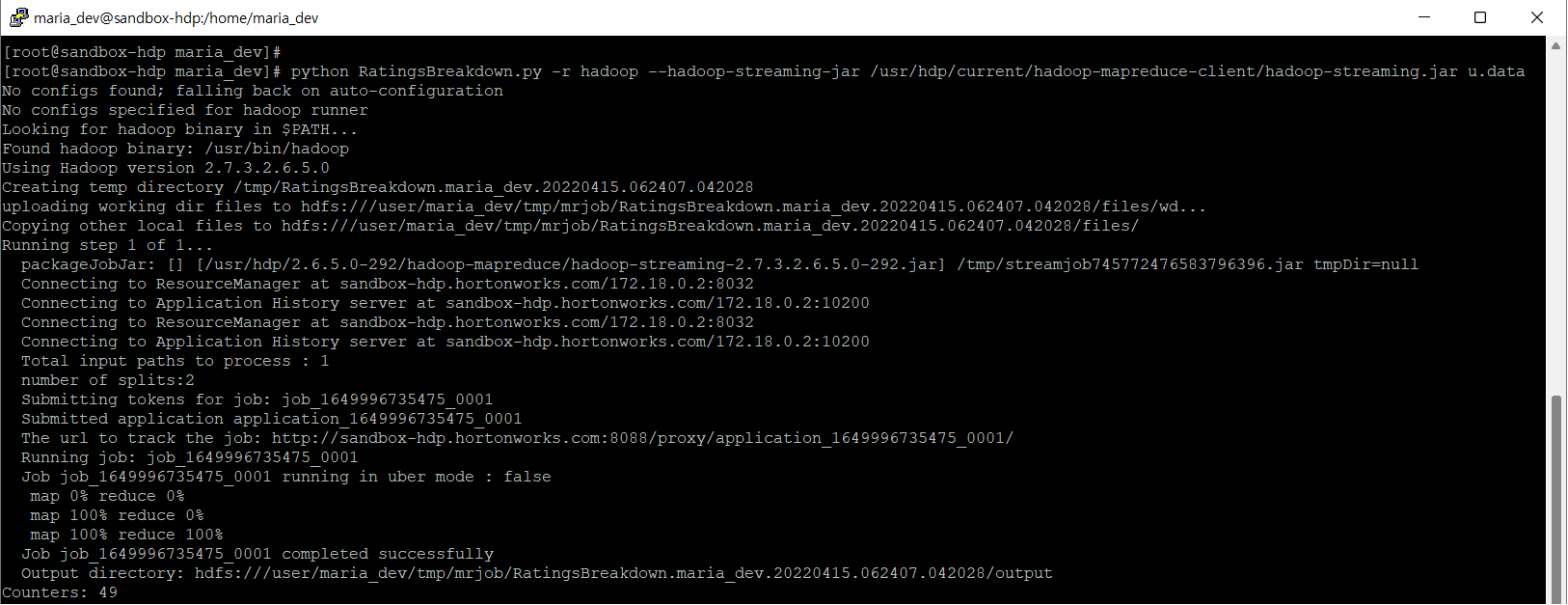
두 번째는 Hadoop에서 MapReduce를 실행하는 방법이다.
1 | $python MostPopularMovie.py -r hadoop --hadoop-streaming-jar |
위의 commandline에서는 local file을 HDFS에 복사를 하고, 복사한 파일 데이터를 여러 노드에 걸쳐서 분배가 된다. 하지만 현재 실습하고 있는 dataset의 경우에는 아주 작은 작업이고, Virtual Machine도 한 개만 존재하기 때문에 HDFS에 복사해서 다른 여러 노드들로 분배하는 과정을 진행하지 않을 것이다.
이를 Uber Job이라고 불리는데 모든 걸 하나의 인스턴스에서 작동하는 작업을 말하는 용어이다. 데이터가 작기 때문에 가능한 이야기이다.
[Uber job]
Uber job이란 Mapper나 Reducer container를 생성하기 위해 RM(Resource Manager)와 서로 소통하기 보다는 MapReduce ApplicationMaster내에서 작업들이 실행되는 것을 말한다.
앞에서 말했듯이 처리되는 데이터가 작은 경우에는 별도로 Map/Reduce 처리를 위한 container를 생성해서 처리할 필요가 없기 때문에 AM(ApplicationMaster) 자체 내에서 Map과 Reduce 작업을 전반적으로 처리한다. 이러한 것을 Uber job이라고 한다.