
이번 포스팅에서는 Hadoop의 생태계에서 핵심이 되는 MapReduce의 세부동작에 대해서 정리해보려고 한다.
MapReduce에 동작에 대해서 이전 포스팅에서 정리를 했듯이 Mapper와 Reducer가 하는 일은 그렇게 복잡해보이지 않는다. 다만 Hadoop의 Cluster내에서 MapReducer가 동작하는 방식이 복잡하기 때문에 이 부분에 대해서 정리가 필요하다.
이전 포스팅에서 다뤘던 내용은 입력받은 데이터를 Mapper가 Key-Value 쌍으로 데이터를 Transformation해주고, 그 결과를 MapReduce가 자체적으로 셔플과 정렬(Shuffling and Sorting)해준다.
이후에 Reducer는 구조화된 정보를 전달받아서 최종 출력물을 생산해내는 역할을 한다.
만약에 정말로 큰 데이터 세트를 가진 클러스터를 운영한다면, 아마 처리 과정을 여러 컴퓨터에 배분하거나 각 노드에서 여러 작업에 걸쳐 진행을 할 것이다.
MapReduce 작업을 세 개의 노드에 나눠서 Mapping작업을 한다고 가정한다면, 데이터에서 몇 줄은 첫 번째 노드에 보내서 처리하고, 나머지 데이터는 나머지 노드에 배분해서 처리할 것이다.
입력 데이터를 여러 파티션에 끼워 맞추고, 각 파티션에 작업 할당을 하게 되는 것이다.
바로 여기서 다른 파티션에 있는 데이터는 신경쓰지 않아도 되기 때문에 작업의 병렬화가 가능해진다.
최종적으로 각 각 작업 배분한 컴퓨터에서 작업이 끝나면 Hadoop은 정보를 잘 받아오고 마무리가 된다.
[MapReduce procedure 반복 숙지]
[STEP1 - Mapping]
클러스터의 각 노드로 대량의 데이터를 작은 블록으로 배분함으로써 key:value 쌍으로 전환하는 Mapping 처리과정을 배분할 수 있다.
[STEP2 - Shuffling and Sorting]
그 다음으로는 Shuffle & Sort작업인데, 앞서 key:value 쌍으로 Mapping하는 과정에서 복수 개의 key를 갖는 데이터가 생기기 때문에 이 과정을 통해서 같은 키 값끼리 모아서 Reducer로 보낼 데이터로 가공하게 된다. 이 과정은 MapReduce가 대신 수행을 하게 된다. 단순히 네트워크상에서 데이터를 주고 받는 형태가 아닌, 모든 정보를 merge sort하는 형태로 처리한다.
[STEP3 - Reducing]
최종적으로 Reducer 단계에서는 데이터를 Key 값을 기준으로 정렬된 세트를 Reducing하게 된다.
다시 정리하자면, Mapping단계에서는 입력된 데이터를 작은 block으로 쪼개서 클러스터 내의 여러 노드로 분산시키고, 셔플과 정렬 작업 이후에는 각 노드가 각 각의 세트를 담당하여 reducing하게 된다. 클러스터 내의 각 노드에서 reducing 작업까지 완료된 데이터들은 Hadoop에 의해 최종적으로 수집되어 마무리된다.
MapReduce의 세부 동작
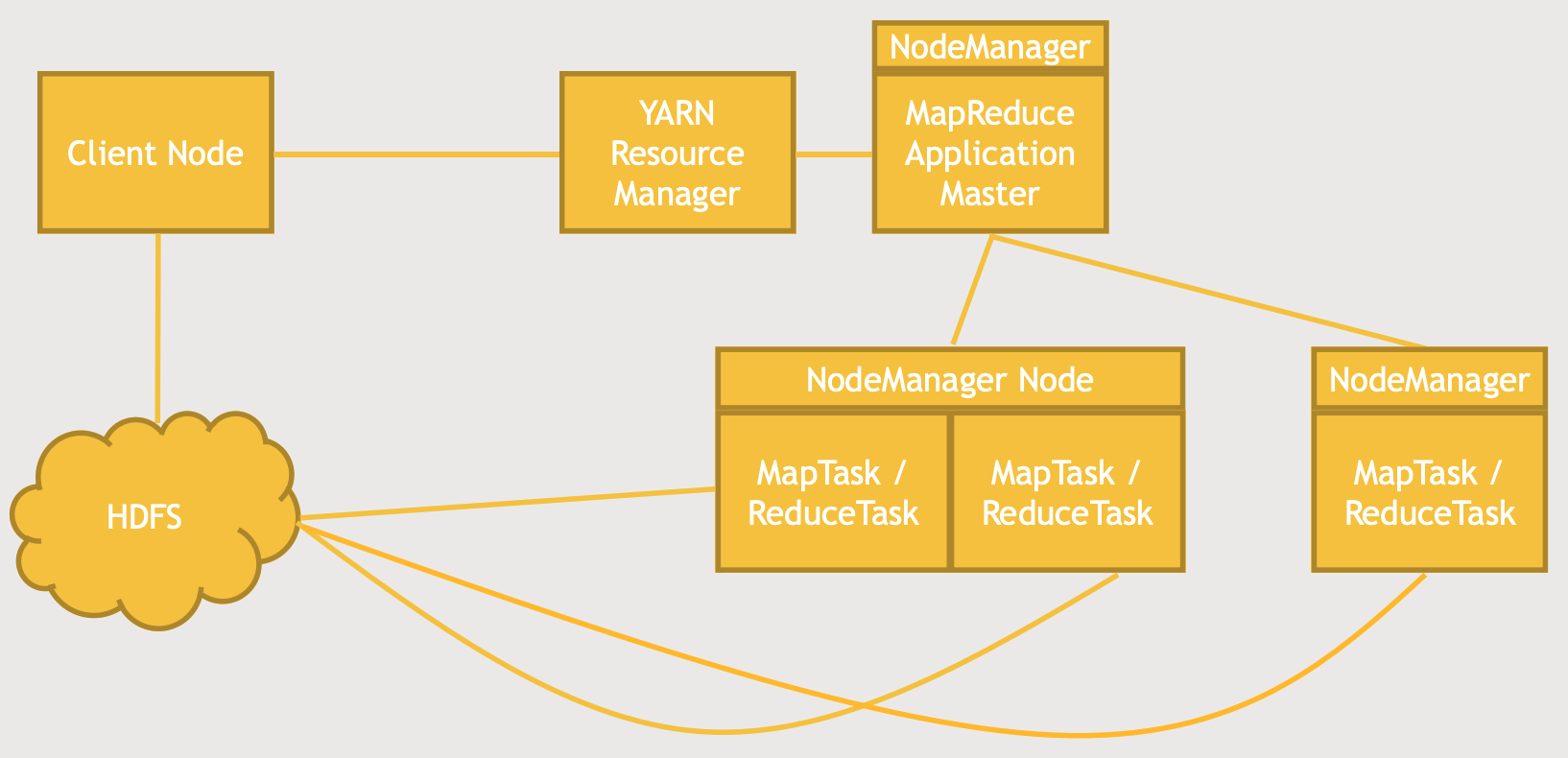
MapReduce 작업의 내면을 자세하게 살펴보자.
[MapReduce Sequence]
(1) MapReduce 작업은 Client Node(Terminal prompt)가 작업을 지시한다.
(2) Client Node는 먼저 YARN Resource Manager와 이야기를 한다. 이전에 하둡과 친해지기 관련 포스팅(세 번째 이야기)에서 언급했듯이, YARN(Yet Another resource Negotiator)은 또 다른 리소스 교섭자의 의미로 데이터의 처리 부분을 담당하며, HDFS는 데이터의 저장부분을 담당했다. YARN은 HDFS에 저장된 데이터를 처리하기 위한 일종의 데이터 관리자의 역할을 해준다. YARN은 어떤 노드가 추가 작업을 할 수 있는지 없는지 그리고 클러스터를 작동하는 심장박동과 같은 역할을 한다.
그 외에도 어떤 노드의 성능은 얼마인지 등의 정보를 기억하고 있기 때문에 Client Node는 YARN Resource Manager와 먼저 상담을 하는 것이다.
그 결과, Client Node는 YARN Resource Manager에게 이러이러한 MapReduce 작업이 필요하다고 전달을 하게 된다.
(3) 그러는 동시에 필요한 데이터를 HDFS에 복사를 한다. 이 작업들을 수행하는 노드들이 데이터에 접근할 수 있도록 데이터를 복사하는 것이다.
(4) MapReduce Application Master가 작동하기 시작하는데, NodeManager 하위에 있다. 기본적으로 MapReduce가 작동하는 모든 것은 NodeManager가 관리한다고 볼 수 있다. *NodeManager는 어떤 노드가 무엇을 하고 사용가능한지, 그리고 작업중인지에 대한 정보를 관리한다.Application Master는 개별 Mapping과 Reducing 작업을 주시하고, YARN과 협업해서 작업을 클러스터에 걸쳐 배분을 한다.
상단의 구조도와 같이 YARN과 Application Master를 제외하고 두 개의 노드가 있다고 하자. 둘 다 Mapping 작업을 하고 있고, 서로 다른 컨테이너이지만 JVM(Java Virtual Machine)에서 실행이 되고 있다. 하지만, 같은 노드 관리자를 두고 있기 때문에 Application Master와 서로 소통을 하면서 어떤 노드가 어디서 무엇을 하는지 추적할 수 있습니다.
(5) 이러한 Mapping과 Reducing 작업이 진행되는 동안에 HDFS 클러스터와 소통을 하면서 필요한 데이터를 받고, 작업이 다 끝나면 결과 데이터를 HDFS 클러스터로 출력을 하게 됩니다.
[중요]
여기서 중요한 내용은 YARN이 Mapping이나 Reducing작업을 최대한 데이터와 가까운 곳에서 실행을 한다는 것이다. 다시말해, YARN은 입력 데이터에 대한 Mapping작업을 웬만하면 그 데이터 블록을 가지고 있는 노드가 수행하도록 조율을 한다는 것이다. 만약 그것이 불가능하다면, 네트워크상에서 최대한 가까이 두도록 한다. 이 말은 불필요한 네트워크 전송을 최대한 줄이려고 한다는 것이다.
MapReduce의 생김새
MapReduce는 원래 Java로 작성이 되어있고, Hadoop도 Java로 작성이 되어있다.
만약 MapReduce 어플리케이션을 직접 작성하고 싶다면, Java를 사용해서 필요한 Mapper와 Reducer가 있는 jar 파일을 만들어야한다.
Streaming은 Pyton과 같은 간단한 언어로 MapReduce를 사용할 수 있게 하기 때문에 Python을 사용해서 MapReduce를 작성할 수 있다.
MapReduce의 Streaming을 사용하면, 표준 입/출력을 사용해서 Mapping작업을 시작할 수 있다. 진행중인 프로세스와 소통하며 Mapper와 Reducer를 실행할 수 있다.
Java에 Mapping, Reducing function을 작성하는 대신에 Python이나 컴퓨터 클러스터 노드에서 작동하는 프로세스에 대신 작성하고 표준 입출력을 사용해서 소통을 하는 것이다.
(표준 입/출력을 통해 데이터 받기 -> Mapper 실행 -> 표준 출력으로 key-value pair 받기)
MapReduce와 Hadoop의 Single Point Failure
Hadoop은 범용 PC로 구성된 거대한 클러스터로, 단점으로 범용 하드웨어들이 종종 다운될 수 있다는 점이다. 작업을 관리하는어플리케이션 마스터가 특정 작업물에서 오류를 발견하면 간단히 그 작업을 재 시작할 수 있다. 이처럼 어플리케이션 마스터는 리소스 관리자에 의해서 작동을 한다.
따라서 어플리케이션 마스터가 다운되면 YARN이 어플리케이션 마스터를 재시작한다.
하지만, 리소스 관리자가 다운이 되면 어떻게 될까? 고가용성 MapReduce라는 것이 있는데, 이것을 이용해서 이전에 다뤘던 Zookeper를 사용해서 동적얘비 리소스 관리자를 유지하는 것이다.
이렇게 되면, MapReduce는 먼저 ZooKeeper와 이야기를 해서 어떤 리소스 관리자를 생성할지 결정하게 되고, 리소스 관리자 사용을 결정 및 다운이 되었다면 Zookeeper는 자동으로 두 번째 백업 리소스 관리자를 가릔다.
나중에 개인적으로 더 찾아 볼 하둡의 개념들
(1) 카운터(counter) : 클러스터 전반에 걸쳐 공유된 총 수 를 유지하는 기능
(2) 컴바이너(combiner) : Mapper Node를 줄여서 최적화해 간접비를 줄여준다.
최근 MapReduce의 입지
요즘에는 MapReduce를 예전만큼 많이 사용하지 않고 있다. 클러스터에 SQL Query를 허용하는 Hive나 Spark같은 고수준 도구로 대부분 대체가 되었기 때문이다. MapReduce는 Hadoop의 필수 요소로써 이해해야 할 중요한 가치를 가지고 있지만, MapReduce를 직접 사용하는 것보다는 MapReduce가 어떻게 작동하는지 실제로 코딩을 해보면서 이해해보는 것이 중요하다.
[실습]영화 평점에 따른 영화 편수 분류
주어진 영화정보 데이터에는 userID, movieID, rating, timestamp 정보가 있다.
이번 실습에서는 각 영화의 평점별 영화의 분포를 분류해보고자 한다.
[Mapper]
1 | def mapper_get_rating(self, _, line): |
[Reducer]
1 | # Shuffle & Sort 과정은 MapReduce에서 별도의 처리를 해주는 부분이기 때문에 바로 Reduce에 대한 작성을 한다. |
[Python MapReduce Code]
mrjob은 Python package로, MapReduce를 작성하기 위해 사용된다. Streaming Interface를 다루는 복잡함을 희석시켜주는 역할을 해준다고 이해하면 된다.
여기서 Streaming Interface에서 Streams란 file과 같은 객체라고 이해하면 된다. I/O module에서 정의하고 있는 툴을 사용해서 객체를 읽고 쓸 수 있으며, 모듈들은 interface를 제공해주기 때문에 만약 정의하고 싶은 stream 객체가 있다면 제공해준 interface를 implement해주면 된다.
아래 코드에서 mrjob을 사용한 이유는 앞서 정의한 stream object를 정의해서 사용하기 위함이다. mrjob.job의 MRJob을 상속받아서 steps 메서드를 재정의(method overriding)하고 있는데, 이 메서드에서 maper와 reducer역할을 하고 있는 method에 대해서 정의를 해주고 있다.
다음에 자바로 작성한 MapReduce 코드도 같이 비교해서 살펴보자.
1 | from mrjob.job import MRJob |