이번 포스팅에서는 현재 진행중인 실습과 앞으로 하게 될 실습내용에 대한 간단한 회고에 대한 내용을 정리해보려고 한다.
이번 실습내용과 앞으로의 실습내용에 대한 이해 및 정리
우선 아직 마무리되지 않은 이번 실습과 앞으로 하게 될 한 번의 실습에 대해서 간단하게 짚고 넘어가고자 한다.
그냥 단순히 실습을 진행하는 것 보다는 왜 내가 이 실습을 하고 있는지에 대한 셀프 피드백이 필요하다. 단순히 실습을 하고 기록을 남기는 것에 그친다면 학습에 있어 방향을 잃을 수 있고, 향후에 내가 포트폴리오를 만들 때 분명 AWS 서비스 기반으로 Cloud Topologies를 구상할 것이기 때문이다. 아직 극초반이지만, 좀 더 앞으로의 큰 그림을 생각하고 학습해나가보자.
이러한 연습이 단순 포트폴리오 영역을 넘어서 나중에 업무에 있어서 빠르게 업무에 녹아드는데 도움이 될 것이라고 생각한다.
자 그럼 지금 하고 있는 첫 실습 내용과 앞으로 하게 될 실습내용을 연관지어서 한 번 정리를 해보자.
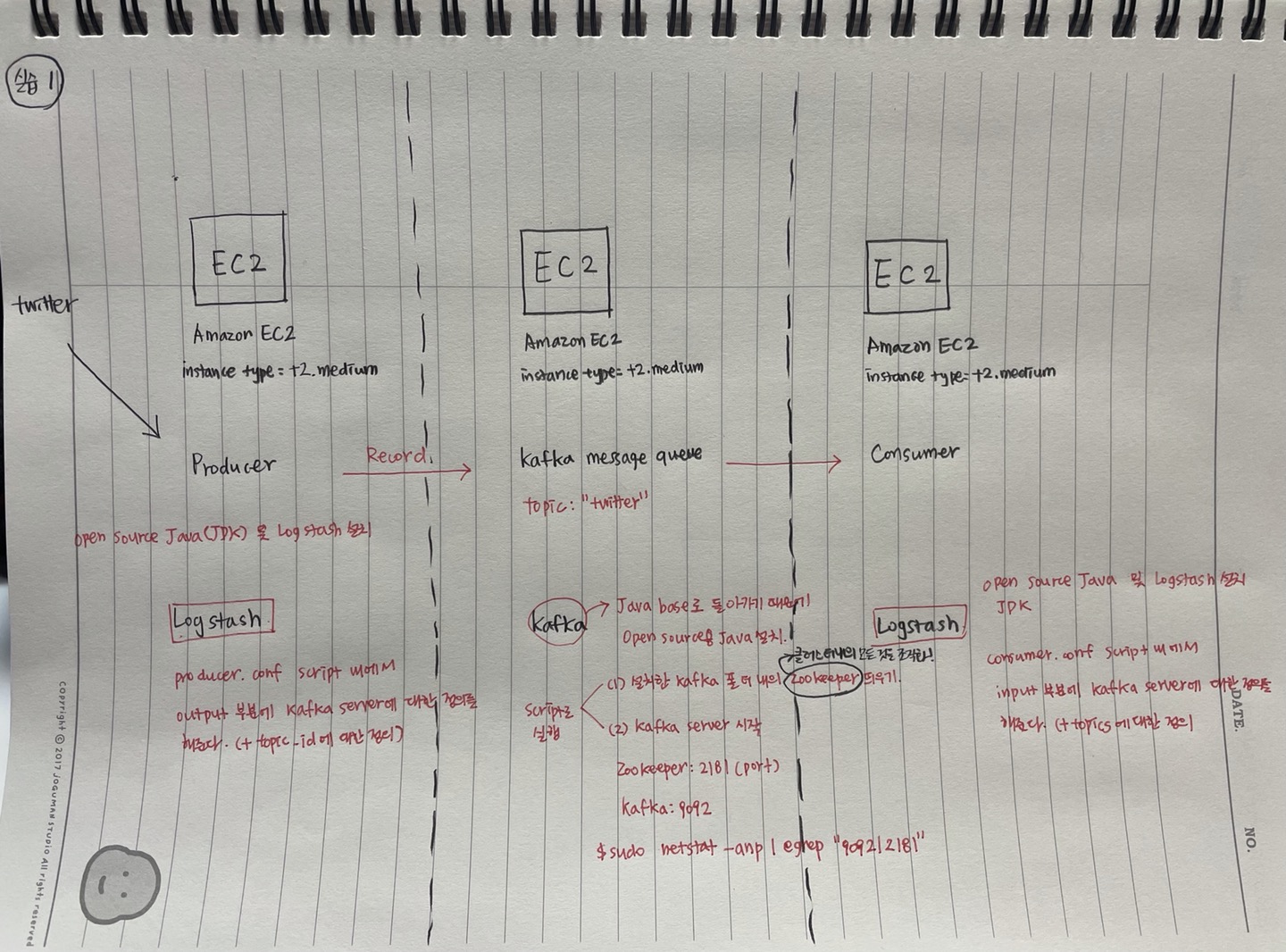
(실습1) EC2 환경에서 Kafka를 이용한 Pipeline 구성
(실습2) AWS API Gateway - Kinesis - S3 구성의 Pipeline 구축
앞선 실습1, 실습2는 모두 데이터 수집을 위한 데이터 파이프라인 구축 실습이다. 표면적으로 실습1, 실습2에서 사용되고 있는 AWS의 서비스 구성만 보더라도 실습1의 경우에는 on-premise 환경에서의 구성에 가까우며, 아직은 잘 모르지만 EC2 기반으로 했기 때문에 시스템에 대한 모니터링이 필요하다고 한다.
반면에 실습2의 경우에는 실습1에 비해 더 쉽고 빠르게 적용할 수 있다고 한다.
클라우드에서는 관리의 대상을 늘리기보다는 서비스에 집중할 수 있고, 관리적 요소가 적은 AWS 서비스로 구성하는 것이 좋다고 한다.
Kafka를 사용한 서비스 구성이 필요하다면, Amazon MSK(Managed Streaming for Apache Kafka)를 사용하는 것이 권장된다고 한다.
이 부분에 대해서 미리 짚고 넘어가는 것은, 간혹 실습하는 것에 집중한 나머지 본질을 잊는 경우가 생겨서이다. 현재 진행중인 실습과 앞으로 진행하게 될 실습은 위에서 언급한 중요한 내용에 유념하면서 진행해보도록 하자.
2022/04/15 업데이트
Consumer 전용 EC2 생성
이전에 Producer, Kafka Server 전용 EC2 instance를 생성했다. Producer에서는 Twitter로부터 로그정보를 받아서 Kafka server 전용 EC2 instance의 topictwitter로 받은 로그 정보를 방출해주고, kafka message queue는 받은 로그 정보를 queue에 쌓아준다.
이번 마무리 실습에서는 consumer.conf 파일에서 input 부분에 Kafka server에 대한 정의를 topic에 대한 정보와 함께 해줌으로써 queue에 쌓인 정보를 Consumer에서 받아서 console에 출력해줄 수 있다.
최종적인 구성도는 아래와 같다.
첫 번째 데이터 파이프라인 실습 회고
이번 첫 번째 데이터 수집관련 파이프라인 구축 실습을 하면서 좋았던 부분은 기본적인 AWS 서비스를 좀 더 알아가면서 실습 할 수 있었던 부분이었다. 이전에 프론트엔드 관련 사이드 프로젝트를 할 때 잠깐 AWS 관련 서비스를 만져본적은 있는데 겉훑기식으로 알고 만들어서, 많이 아쉬웠었는데, 이번 기회가 많이 도움이 되었다.
그래서 이참에 AWS의 가장 기초가 되는 AWS Practitioner 자격증 공부도 같이 병행을 하고 있다. 지금 공부한지 한 6일정도 되어가는데, 공식 사이트에서 제공하는 시험관련 콘텐츠를 지금 모듈5 부분을 공부하고 있다. 공부를 하면서 물론 만져보지 못한 AWS 서비스도 많지만, 이번 데이터 파이프라인 구축 실습을 하면서 만져보았던 AWS 기본 서비스 관련 내용도 많이 나와서 이론 공부와 실습을 같이 병행한 느낌이라 많이 도움이 되었다.
앞으로 남은 실습들도 같이 열심히 진행하고 학습한 내용을 토대로 반복하면서 연습을 해봐야겠다.