이번 포스팅에서는 웹 서버 전용 EC2 인스턴스를 생성하고, 생성한 EC2 인스턴스에 httpd 설치 및 실행을 해보고 간단한 테스트 웹 페이지를 띄워보는 실습을 해본다.
Httpd
우선 웹 서버 전용 EC2 인스턴스를 생성한 뒤에 해당 EC2 인스턴스에 Httpd demon을 설치해줬다. 선택한 AMI가 CentOS와 비슷한 이미지를 가지고 만들었기 때문에 설치한 httpd 서비스가 EC2 lifting시에 자동으로 로드되게 하기 위해서는 서비스를 등록해야되는데, 설치하면 default로 서비스에 등록이 되기 때문에 아래와 같은 프로세스로 서비스 설치 및 시작을 하면 된다.
설치된 Httpd에 기본 Home 디렉토리(/var/www/html)가 있는데, 해당 위치에 웹 기본이 되는 파일(index.html)을 생성해서 간단하게 웹 페이지 테스트를 할 수 있다.
1 | # httpd 설치 |
위에서 index.html 파일내에 HTML 코드를 작성 후, 주소표시줄에 “연결” 메뉴에서 확인하였던 퍼블릭 DNS 주소를 웹에 붙여넣으면, 작성했던 HTML 페이지가 출력됨을 확인 할 수 있다.
이처럼 Public DNS 주소를 통해 생성된 EC2 인스턴스의 리소스에 접근을 할 수 있다는 것을 알 수 있다.
추가적으로 위의 httpd를 설치 및 서비스 시작하는 일련의 과정을 EC2 인스턴스 생성시에 고급 세부 정보 세션에서 사용자 데이터 부분에 스크립트로 넣어서 간단하게 실습해볼 수도 있다. (웹 서버 시작 부분까지)
1 | $yum update -y |
Kafka 실습 구성
이번 실습에서는 실제 Cluster까지는 구현을 안하고, 메시지가 어떻게 흘러가는지 이해할정도로만 구성하고, 메시지가 어떻게 흘러가는지 전반적인 흐름에 대해서 파악을 한다.
파이프라인을 구성할때 PC의 툴이나 연필로 직접 그려가면서 파이프라인을 구성하는 연습을 하면 완성도 높은 파이프라인을 구성할 수 있다. 아직 지식이 많이 부족하더라도 조금씩 이해하고 있는 지식들을 최대한 활용해서 연습해보도록 하자.
(Topic name : twitter)
Kafka 설치 : Kafka에 Topic을 하나 생성해서 이 곳에 데이터를 쏠 것이다.
Producer에서는 Logstash가 있는데, 이 친구는 Elastic search에서 데이터를 수집해서 Elastic search 안으로 넣어주는 프로그램이다. 데이터를 임의로 생성하기 어렵기 때문에, 트위터에서 데이터를 받아서 카프카에 넣어서 처리를 해볼 것이다.
Topic을 Consumer하는 부분까지 구성한다.
Consumer 자체에서도 Logstash를 띄워서카프카 큐에 있는 데이터를 가져와서 화면에 띄워주는 부분까지 작업
위의 실습은 마치 온프레미스 환경에서 서버 3대(EC2 3개)를 가지고 구성한다고 가정하고 실습하도록 하자.
Kafka EC2 인스턴스 생성 및 Kafka 설치
Kafka 실습 - 유형 t2.medium 이상 선택
인스턴스 세부 정보 구성 : 인스턴스 갯수 : 2 (한 번에 두 개 이상 시작 할 수 있도록 구성)
Kafka가 기본적으로 자바 베이스로 돌아가기 때문에 자바를 설치하고 카프카를 설치하면 된다. Open source용 자바를 설치 권장
1 | $sudo yum install -y java-1.8.0-openjdk-devel.x86_64 |
1 | $wget https://dlcdn.apache.org/kafka/3.0.1/kafka_2.12-3.0.1.tgz |
버전이 바뀌었을때에도 논리적 링크를 가져가기 위해서 링크를 걸어서 사용한도록 한다. (kafka 뒤에 길게 붙어있는 버전명을 신경쓰지 않아도 되는 장점이 있다)
1 | # 압축을 해제한 디렉토리를 kafka의 alias로 link를 걸어서 재사용할 수 있다. |
Zookeeper & Kafka server 시작
Zookeeper에 대해서는 이전에 Hadoop의 eco system에 대해서 전반적으로 알아보면서 정리했을때 알아보았는데, Zookeeper는 클러스터의 모든 것을 조직화하는 기술이다. 이 기술을 이용하면 클러스터내에서 어떤 노드가 살아있는지 추적할 수 있고, 여러 어플리케이션이 사용하는 클러스트의 공유 상태를 안정적으로 확인할 수 있다. (Hadoop과 치해지기 세 번째 이야기 중)
1 | # 압축을 해제한 Kafka 폴더 내에서 아래 commandline을 실행한다. |
- 외부의 서버와 통신하기 위해서는 보안그룹에서 9092 port를 열어놔야지 다른 서버에서 producer가 메세지를 넘겨줄 수 있다. 보안그룹에서 9092 port 추가 필요.
(EC2 인스턴스의 보안그룹 -> 인바운드 그룹 규칙에 9092 port 추가/kafka-producer EC2 서버에서 데이터를 넘겨줄때 해당 포트를 통해 kafka-server의 가상서버 자원으로 접근할 수 있다)
Kafka에서 Topic 생성하기
1 | # Kafka에 Topic 생성 |
메시지가 서버에 잘 쌓이는지, 서버 한 대에서 확인
1 | $./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic twitter --from-beginning |
Producer Setup
kafka를 테스트용으로 producer에서도 설치를 한다.
1 | # Java 설치 |
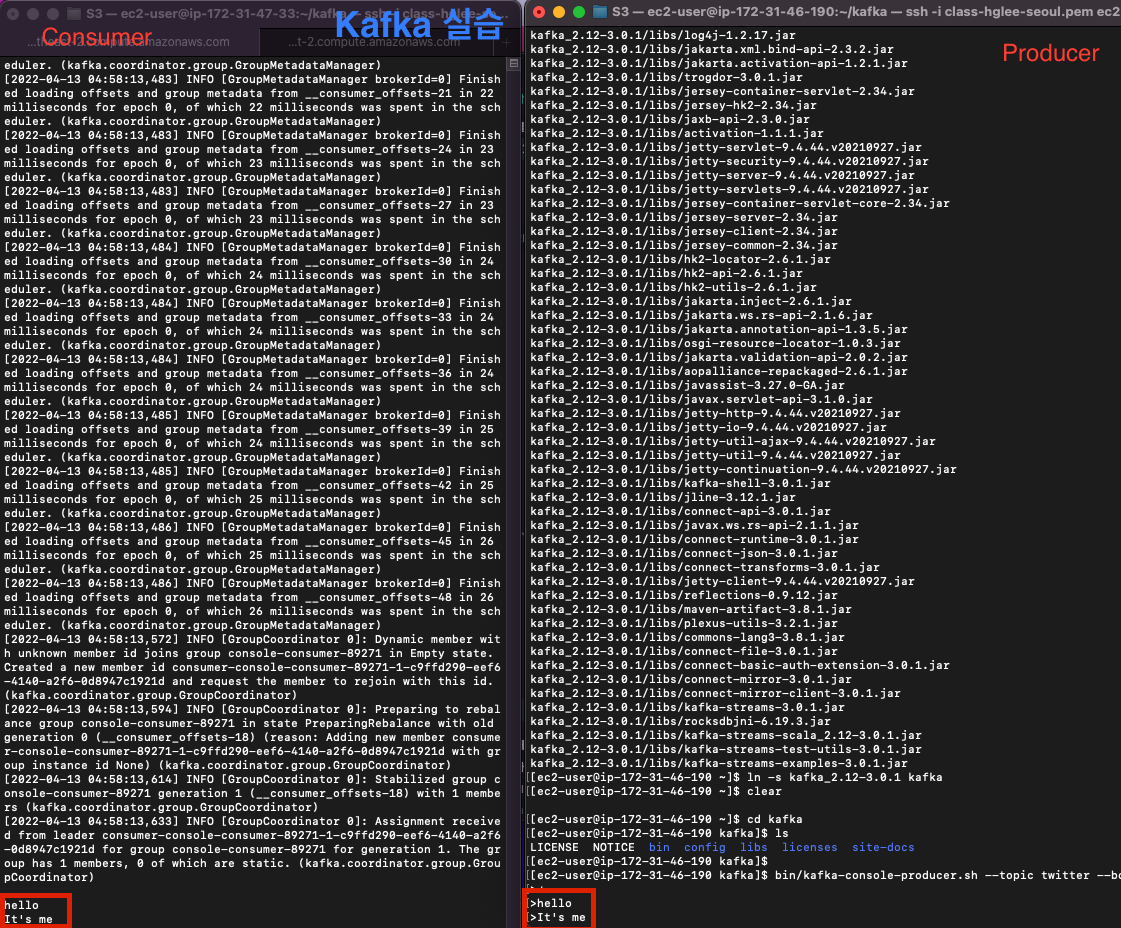
위의 설정이 다 끝나고 Producer 역할의 EC2에서 메시지를 입력하면, Consumer 역할을 하는 EC2의 Terminal에 출력이 되는 것을 확인할 수 있다.
하나하나 파이프라인을 만들때마다 중간 체크를 확인해가면서 파이프라인을 구축해나가는 연습을 해야한다.
ctrl+d : 신호를 보내는 것이 아닌, 특수한 바이너리 값을 나타내며, EOF(End Of File)을 의미
cf)
ctrl+c: 중단 명령 (프로그램의 실행을 강제로 중단)ctrl+z: 중단 명령 (작업이 끝나지 않았으므로, 프로세스에서 끊긴 상태를 유지. fg/bg 명령을 사용하여 프론트나 백스테이지의 작업을 이어나갈 수 있다)
[Producer side] Logstash 설정 및 twitter 연결하기
[Logstash 설정하기]
1 | $wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.0.tar.gz |
logstash같은 경우에는 접속 정보나 hump라는 파일을 구성하는데 어느 폴더의 위치에서나 Logstash를 실행시키기 위해서 .bash_profile에 path를 추가해준다.
1 | $ vi ~/.bash_profile |
Twitter 개발자 페이지에서 필요한 key들(consumer key, consumer secret, oauth token, oauth token secret)을 발급받아 사용하는 과정에서 에러가 발생해서 시간이 많이 지연되었다. 결과적으로 아래의 Twitter log를 Producer로부터 취득해서 가져올 수 있었고, 내일부터는 Producer로부터 취득한 Log 데이터를 Kafka의 message queue에 담아보는 작업부터 이어서 해봐야겠다. 쉬운게 없다…
1 | { |
[Kafka message queue에 Twitter로부터 가져온 로그정보 넘겨주기]
1 | input { |
위의 스크립트를 실행하면 producer가 twitter로 받은 log정보를 Kafka message queue로 쌓아주게 된다. 그 다음 STEP은 Kafka message queue에 쌓인 message들을 Consumer에서 읽어서 소비하는 작업을 처리한다.