
이번 포스팅에서는 sample 데이터를 활용해서 HDFS를 실제로 다뤄보는 실습을 해본다.
Ambari
Ambari는 Hadoop Eco System에서 구조상 최 상위에 위치해있는 어플리케이션으로, Hadoop과 관려된 서비스들 전체를 모니터링할 수 있는 웹 인터페이스 환경을 제공한다.
웹 인터페이스를 사용해서 HDFS 다뤄보기
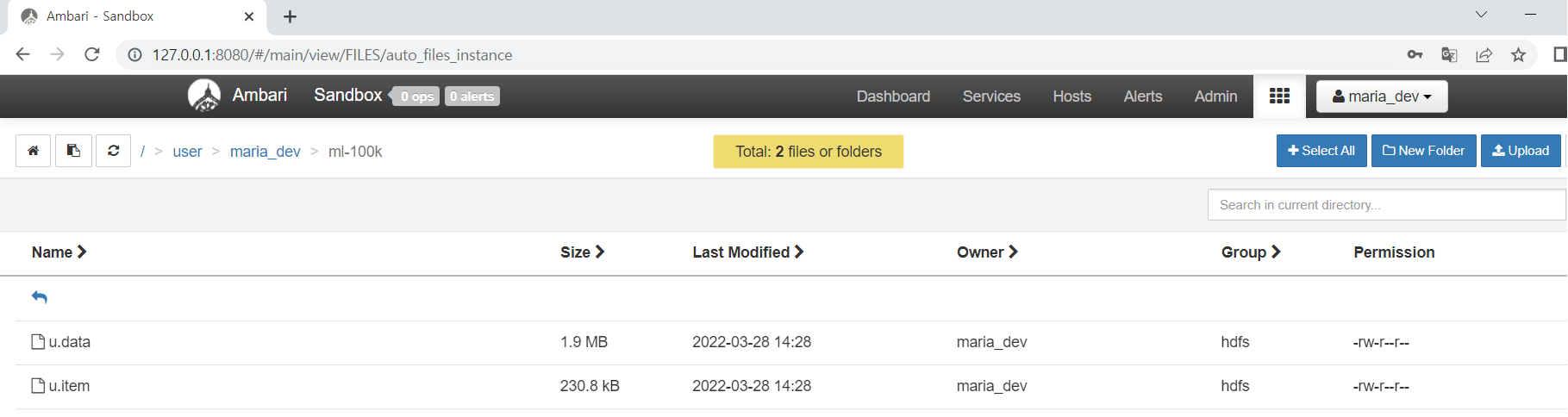
HTTP 인터페이스로 간단하게 HDFS에 파일을 업로드, 로컬 디스크에 다운로드, HDFS에 업로드한 파일들을 삭제해보았다.
HDFS에 파일을 업로드할때에는 단순히 파일을 업로드 되는 것처럼 보이지만, 실제로는 파일을 올릴때 HDFS 내부의 Name Node에 어느 Data Node에 저장을 할지 확인하는 절차를 통해 클러스터내의 특정 Data Node에 저장을 하고, 정상적으로 저장이 완료되면 Name Node에 결과를 알려줘서 Name Node가 관리하고 있는 저장 데이터와 관련된 메타 데이터 테이블에 새롭게 저장된 데이터 정보를 추가하게 된다.
(내부적으로 이러한 일련의 과정을 거치고 있다는 것을 인지한 상태에서 계속해서 학습을 이어가도록 하자)
Hadoop 클러스터와 연결된 명령 프롬프트의 명령줄을 활용해서 HDFS 다뤄보기
master node, client node에 접근해서 HDFS를 읽는다.
가상머신의 OS INSTANCE를 PUTTY로 원격 연결
1 | Host Name : maria_dev@127.0.0.1 |
HDFS를 linux host commandline으로 조작
$ prompt의 뒤에 hadoop fs -{linux commandline}의 형태로 command라인을 작성해주면 된다.
1 | $hadoop fs -ls |