이번 포스팅에서는 앞으로 진행하게 될 첫 실습내용에 대해서 개괄적으로 정리를 해보려고 한다.
실습에 사용되는 것은 AWS의 EC2, Kafka, Logstash, Twitter이며, 간단하게 말하면 EC2 가상 서버를 기반으로 설치된 Producer와 Kafka(queue), Consumer로 구성하고, Producer가 Twitter에서 발생하는 데이터를 수집해서 Kafka queue에 저장된 Twitter의 데이터를 Consumer에서 가져와서 화면에 보여주는 형태로 실습을 진행한다.
(Kafka를 온프레미스에 설치하듯이 AWS의 EC2에 설치를 해서 실습을 진행한다)
Kafka가 뭐지?

Kafaka란 메시지 큐이고, 분산환경에 특화되어 설계가 되어있다는 특징을 가지고 있다. 따라서 기존의 RabbitMQ와 같은 다른 메시지큐보다 훨씬 빠르게 처리한다.
(여기서 RabbitMQ란 커다란 바구니 안에 여러가지 공이 있는데, 공은 queue에 있는 job을 의미한다. 공들 중에서 하나를 꺼내서 job을 수행하고, 성공적으로 job이 끝나면 해당 job을 삭제하는 일련의 과정을 거친다)
Kafka가 다른 메시지큐보다 빠른 이유는 위에서 언급했듯이, 분산환경에 특화되어 설계가 되어있는데, 때문에 여러 서버 혹은 서비스에서 발생하는 데이터를 한 군데에서 수집할 수 있는 환경을 구성할 수 있다.
또한 대표적인 스트림 큐의 서비스이며, 파일 사이즈를 기준으로 설정하며, default로 1GB 정도의 데이터를 유지한다. 만약에 큐의 데이터가 1GB를 넘을 경우, 삭제처리한다.(ex. 폭포에 비유 : 사이즈를 넘는 데이터는 폭포에서 떨어지는 데이터로, 삭제 처리한다)
[특징]
LinkedIn에서 개발된 분산 메시징 처리 시스템이다.- 파일시스템을 사용하기
때문에 데이터영속성이 보장된다. 대용량의 실시간 로그 처리에 특화되어 설계된 메시징 시스템으로, 기존 범용 메시징 시스템대비, TPS가 우수하다. 이러한 이유로 최근에 가장 많이 사용하는 스트림 큐이다.
Producer & Consumer
Kafka 큐의 데이터를 중심으로 데이터를 생산하는 Producer와 소비하는 Consumer가 있다.
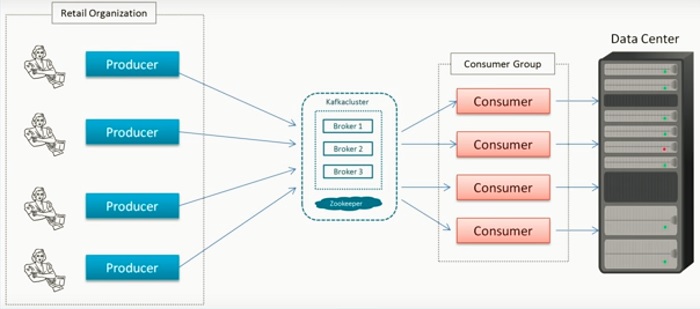
Producer는 웹이나 앱 혹은 관련 IoT 또는 회사의 시스템에서 발생하는 여러 메시지를 카프카 클러스터에서 받아서 큐에 쌓고, 쌓여있는 큐의 데이터를 컨슈머들이 가져다가 사용한다.
Producer는 메시지를 생산하는 주체이며, Consumer는 소비자로써 메시지를 소비하는 주체이다.
Consumer는 카프카(큐)에 쌓여있는 데이터를 가져다가 DB에 저장을 하기도 하고, S3에 저장, 리얼로 저장(Elasitic search, NoSQL DynamoDB에 저장)하여 대시보드에 보여주는 형태로 사용된다.
위의 도식도를 보면 알 수 있듯이, Producer와 Consumer는 1:1 매핑이 아니며, Consumer는 데이터를 소비하며, 자기가 어느 위치의 데이터를 가져다가 처리하는지에 대한 정보를 가지고 있다.
Consumer마다 각 각 해당 정보들을 가지고 있으며, 시스템이 받쳐준다면 더 많은 컨슈머들이 존재할 수 있다.
실무예시-Producer와 Consumer가 일치하지 않는다)수집량이 25TB인데 소비하는 데이터의 양은 하루에 30TB라고 한다. 수집량과 데이터의 양은 같지 않음을 알아야 한다.
Kafka 실습 구성도
실습은 AWS의 가상 서버인 EC2에 설치를 한다.
Kafka 클러스터는 별도로 구성을 안하고, 큐 하나로써 서버에 구성을 한다.
위의 도식도에서는 Producer/Kafka/Consumer 세 개의 논리적 파트로 나눠져있지만, 실제 실습에서는 EC2 가상서버를 2대로 하고, EC2 하나에서는 Kafka queue를 구성, 다른 하나에서는 Producer를 구성해서 Producer에서는 twitter에서 발생하는 데이터를 Logstash를 사용해서 수집해서 Kafka queue로 넘겨줄 것이다. kafka queue에 쌓여있는 데이터는 Kafka Consumer로 넘겨서 최종적으로 화면에 보여주는 부분까지 실습을 진행할 것이다.
간단하게 AWS에서 지원하는 카테고리별 서비스 보기
(컴퓨팅) - EC2
(스토리지) - S3, S3-Glacier
(데이터베이스) - RDS, DynamoDB
(마이그레이션 및 전송) - DMS(Database Migration Service) 이기종 데이터를 옮길때 사용, AWS내의 DBMS의 데이터를 전송할때에는 현재 운영중인 서비스의 리소스를 적게 쓰면서 데이터를 migration할 수 있는 서비스이다.
EC2 인스턴스 생성
인스턴스 유형
c : computing
g, p : GPU 사용
m : 간단하게 사용 (CPU/GPU 반반으로 사용)
i : I/O 관련 성능을 좋게 만들어놓은 것
r : 스팟 사용시 많이 사용됨. 메모리 중심 유형
네트워크 설정
VPC(Virtual Private Cloud) :
AWS 리소스에 경계를 설정하는 데 사용할 수 있는 네트워킹 서비스이다. AWS 서비스를 사용하는 수백만 명의 고객이 존재하고, 이들 고객이 생성한 EC2 인스턴스와같은 수백만 개의 리소스들이 리소스간에 경계가 없으면 네트워크 트래픽이 제한 없이 리소스 간에 흐를 수 있기 때문에 VPC의 개념이 필요하다.NAT
Public IP
private IP
태그 설정
태그 설정은 default로 넣어주는 것이 좋다. 나중에 특정 cluster에서 어떤 instance가 사용이되었고, 사용량이 어떻게 되었는지 책정하는데 태깅을 하게 되면 유용하다.
다른 사람들과 AWS계정을 같이 사용할때에는 내가 사용하는 EC2가 무엇인지 구분하기 위해서는 필수이다.보안그룹
과거에는 서버를 구성할때 기본으로 보안 담당자가 설정을 했지만, in-bound, out-bound가 있다.
in-bound는 EC2를 띄워주는데, 어떤 port를 통해서 들어오는지 설정하는 것이고, out-bound는 EC2에서 인터넷쪽으로 나가는 방향을 설정할때 설정한다. 일반적으로 out-bound는 다 열어준다. (은행과 같이 보안이 강한 곳을 제외)
보통 in-bound 컨트롤을 많이 한다. (해킹/보안)인스턴스 시작 검토 단계에서 로그인 패스워드 설정
접속할 수 있는 RSA 방식의 *.pem 파일을 하나 다운로드 받아서 해당 파일로 접속하도록 보안이 강화되었다.
region별로 키페이가 다르기때문에
class-hglee-seoul 형태로 region명을 넣어주도록 한다.
EC2 인스턴스 구성
- 인스턴스 ID : 프로그래밍(Python, Java 등의 언어)으로 인스턴스에 접근을 해서 변경을 할 수 있다.
- Private IP
- Public IP
항상 Private과 Public이 쌍으로 구성되어있다. 해당 EC2 인스턴스 자체가 SUBNET VPN자체가 Public으로 구성이 되어있어서 두 개가 쌍으로 구성되어있다.
내부에서의 네트워크를 할 경우에는 Private IP/Domain을 사용해서 통신을 한다.
- AMI ID
- 키 페어 이름 (키 페어 이름으로 인스턴스를 검색할 수 있다)
EC2 인스턴스 연결
EC2 인스턴스 리스트에서 "연결"을 클릭하면, 인스턴스 ID, 퍼블릭 IP 주소, 사용자 이름 정보가 표시되는 탭이 표시가 되는데, 이 부분은 브라우저에서 바로 접속할 수 있게 지원해주는 서비스이다. GCP쪽에서는 기본적으로 브라우저에서 접속이 가능하도록 지원해주는데, AWS에서도 지원을 해준다.
한글입력으로 인해 SSH 클라이언트 탭을 통해 접속을 해보도록 한다.
SSH 클라이언트 탭에 나와있는 설명대로, 이전에 EC2 인스턴스 비밀번호 생성시에 다운받았던 *.pem 파일의 권한모드를 변경시켜주고, 권한모드를 변경한 *.pem파일을 퍼블릭 DNS를 사용하여 인스턴스에 연결해준다.
1 | $chmod 400 class-hglee-seoul.pem |
위의 commandline 명령을 실행하면, 아래와같이 *.pem 파일 경로와 동일 경로에 사용자 초기화 파일들이 생성이 되는 것을 확인할 수 있다.


Git에 있는 소스코드/분석에 진행할 로그 데이터를 다운로드 받기 위한 Git 설치
1 | # CentOS 환경에 Git 설치 |
Git에서 다운받은 실습용 로그 데이터를 분석을 위해서 S3로 이전
s3-cli명령어 s3-sync 명령어 사용해서 이전 서비스와 서비스 간의 권한을 획득해서 다른 서비스를 사용하기 위해서 access key, security key를 사용해야했다.
서비스와 서비스간의 권한주기위해서는 access key와 security를 사용해서 해킹을 당하는 경우가 생겨서, 권한을 부여해서 사용하는 것을 권장하게 되었다.
AWS console에서 IAM에서 권한을 줄 수 있게 되어있다. (사용자 역할 및 정책)
IAM 대시보드에서 사용자에대한 역할 및 정책을 컨트롤할 수 있으며, 보안자격증명에 가보면, Accesskey키와 Security키를 확인할 수 있다.
잃어버린 경우에는 비활성화 시킨 뒤에 재생성하면 된다.
서비스 <-> 서비스 간의 권한을 만들어서 하는 방식으로 실습진행한다.
권한을 탈취될 경우가 적기때문에 역할을 만들어서 실습을 하도록 한다.
EC2 역할 생성
IAM > 역할 > 역할 생성 (일반 사용사례에서 EC2 선택)
권한 정책 연결에서 AdministratorAccess 권한 추가해준다.
AdministratorAccess를 추가해주게되면, EC2에서 다른 어떤 서비스에도 접근할 수 있는 권한을 주게 된다.
역할 이름 및 태그도 어떤 EC2 인스턴스에 적용을 할 것이지 정확히 명시해주도록 한다.
생성한 EC2 역할을 EC2 인스턴스에 적용
EC2 인스턴스 리스트에서 적용하고자하는 EC2 인스턴스를 체크한 다음에 인스턴스 시작 왼쪽의 드롭다운 박스에서 생성한 IAM 역할을 선택한다.[보안]-[IAM 역할 수정]-[EC2Admin]을 선택한다.
EC2에 적용된 역할 확인(aws cli 명령) 및 S3 Bucket 생성
1 | # s3를 읽어서 확인 |
생성한 S3 Bucket에 분석용 로그파일 복사
1 | # .git/* 하위의 파일들을 제외하고 s3에 새로 생성한 버킷에 현 위치에 있는 폴더를 복사한다. (sync 명령어 사용) |