
이번 포스팅에서는 HDFS의 내부구성에 대해서 알아보고, 대용량의 파일을 어떤식으로 처리하는지에 대해서 한 번 정리해보겠다.
개괄적으로 HDFS에서 대용량의 파일을 처리하는 방법에 대해서 간단히 알아보면 대용량의 파일을 여러개의 블록 단위로 쪼개서 클러스터를 구성하고있는 각 노드에 저장을 한다.
각 노드는 같은 데이터 블록 정보를 저장하고 있기 때문에 노드 중에 한 개에 문제가 생겨도 복원을 할 수 있다.(Single point failure issue 대응)
이제 한 번 STEP BY STEP으로 HDFS(Hadoop Distribution File System)에 대해서 알아보자.
STEP1 BIG DATA의 등장과 블록단위로 쪼개고 저장하기

자, 엄청나게 큰 데이터가 주어졌다고 가정하자.
HDFS는 이러한 빅데이터를 전체 클러스터에 분산해서 안정적으로 저장해서 어플리케이션이 그 데이터를 신속하게 액세스해 분석할 수 있도록 돕는다.
좀 더 구체적으로 말하면 HDFS는 대용량 파일들을 다루기 위해서 만들어졌다. 작은 데이터는 누구든 쉽게 다룰 수 있지만, HDFS는 이런 대용량의 파일들을 작은 조각으로 쪼개서 클러스터 전체에 걸쳐 분산시키는데 최적화되어있다.
그래서 분산 파일 시스템이라고 하는 것이다.
아직 빅데이터를 안다뤄봤지만, 빅데이터와 같은 대용량의 파일은 센서나 웹 서버등으로부터 받아오는 정보의 로그 등이 될 수 있다고 한다.

이러한 대용량의 데이터를 작은 조각으로 쪼개는 과정은 그 파일을 우선 데이터 블록단위로 쪼갠다. 그 개별 블록의 사이즈도 큰 편인데, 기본값으로 128MB이다.
이렇게 블록단위로 나누게 되면, 더 이상 하드 드라이브의 용량에 제한되지 않는다. 그말인 즉, 각 하드 드라이브의 용량보다 훨씬 큰 파일의 데이터 정보를 담을 수 있다는 말이 된다.
각 노드는 자신에게 저장된 데이터 블록을 동시처리할 수 있으며, 처리되는 특정 블록이 저장된 곳이랑 물리적으로 가까운 거리에 있도록 조정을 할 수 있다. (데이터의 효율적 액세스)
블록들이 저장될 때에는 단 하나의 블록만을 저장하지 않고, 모든 블록마다 두 개 이상의 복사본을 다른 노드에 저장을 한다. 그래야지 특정 노드가 다운이 되더라도 HDFS가 해당 블록의 백업 복사본을 가지고 있는 다른 노드에서 정보를 불러올 수 있다.
HDFS Architecture
HDFS의 Architecture에 대해서 세세하게 알아보자.
먼저 HDFS는 대용량의 파일을 여러 블록으로 쪼개서 클러스터내의 여러 노드 전반에 거쳐 데이터를 분산/저장한다고 했다.
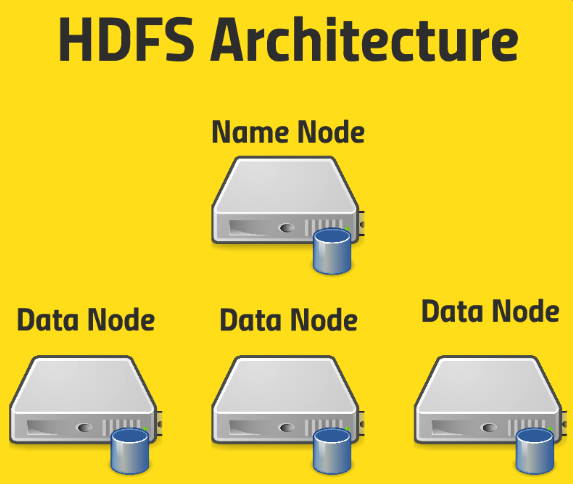
그럼 분산된 각 데이터 블록들 중에 특정 블록을 찾아서 처리하고자 할때, 어디있는지 기억하고 있는 친구가 있어야 한다. 이 친구가 바로 이름 노드(Name Node)이다.
이 Name Node는 내부에 큰 차트를 가지고 있는데, 그 곳에는 주어진 파일의 이름과 HDFS 내의 가상 디렉토리 구조 등의 정보가 있고, 파일과 관련된 모든 블록과 해당 복사본들이 어떤 노드에 저장되어있는지에 대한 정보를 기록해두고 있다.
그 외에도 편집로그(Edit log)가 있는데, 무엇이 생성되었고, 어떤게 수정되어서 저장되었는지에 대한 정보가 기록이 된다. 그냥 모든 변경 사항이 생기면, 이 Name Node라는 친구의 테이블에 기록이 된다고 알면 된다.
따라서 하위에 있는 Data Node에 무엇이 있는지에 대해 Name Node에 기록이 된다는 말이다.
[HDFS에서 파일읽기]
자 그러면 HDFS의 각 노드에 저장된 데이터 파일은 어떻게 읽는 것일까?
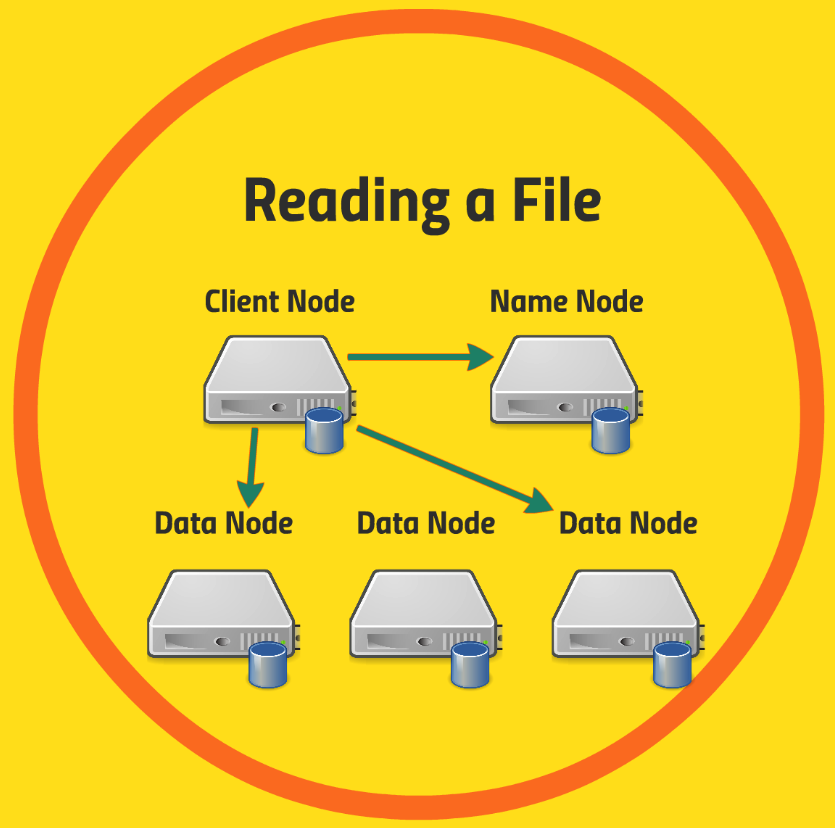
[STEP1]
어플리케이션이 HDFS에 있는 데이터에 액세스를 하고자 한다. 이 경우, 우선 Client Node에 있는 클라이언트 어플리케이션은 Name Node에 Query를 해서 "내가 지금 파일 A가 필요한데, 어디로 가야되?"라고 묻는다.
[STEP2]
그러면 Name Node는 “파일 A는 지금 Y라는 노드의 x라는 블록들에 저장이 되어있어”라고 알려준다.
[STEP3]
그러면 클라이언트 어플리케이션은 Name Node가 알려준 정보를 기반으로 찾고자하는 A라는 데이터를 가지고 있는 Data노드를 방문해서 해당 데이터를 가져와서 파일 A를 구성한다.
위에서 [STEP1] ~ [STEP3]에서 Client Node에서 Name Node에 요청을 하고, Client Node에서 Name Node로부터 받은 정보를 기반으로 Data Node로 가서 데이터를 가져와서 파일을 구성한다고 했는데, 실제로는 클라이언트 라이브러리가 사용된다.
API가 특정 Byte를 특정 파일에서 읽고 싶다고 하면, HDFS 클라이언트 라이브러리가 내부적으로 어떤 블록을 어디서 찾아야 할지 그리고 어떻게 찾아가야 되는지에 대해서 알아낸다. 위에서 설명한 내용은 내부적으로 일어나는 일로 이해하자.
[HDFS에서 파일쓰기]
클라이언트 어플리케이션이 HDFS에 새로운 파일을 만들려고 할때,
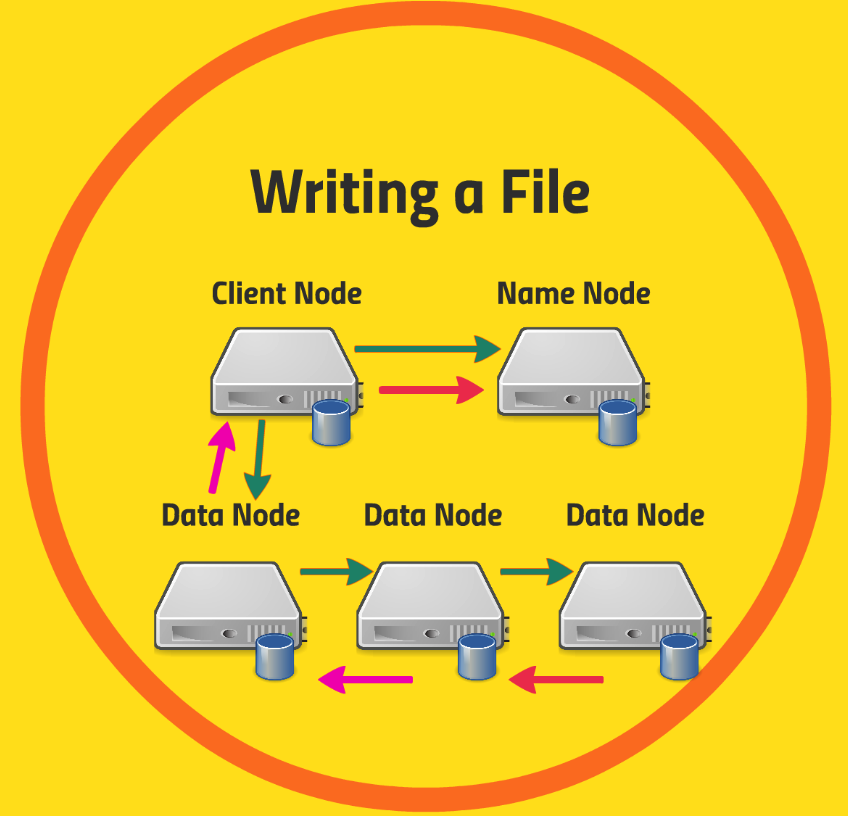
[STEP1]
우선적으로 블록의 위치를 추적하는 Name Node라는 친구에게 우선 물어본다.
[STEP2]
그러면 Name Node는 새로운 파일 항목을 확인하고, 그 블록의 위치를 정해서 Client Node에게 특정 Data Node에 가서 새로운 파일 항목을 저장하라고 알려준다.
[STEP3]
그러면 Client Node는 지명받은 특정 Data Node에 가서 파일을 건내준다. 그러면 해당 Data Node의 주변 다른 Data node에 복사본을 전달하고 또 전달을 한다.(Broadcasting)
[STEP4]
최종적으로 데이터가 저장이 되면, 잘 받았다는 신호를 Client Node를 통해 Name Node에 전달을 한다.
그러면 Name Node는 새로운 파일의 블록과 복사본의 위치를 테이블에 기록을 해서 기억한다.
Name Node의 Single Point Failure

자 앞서 살펴보았듯이 Data Node가 여러 개인 것에 반해 Name Node는 한 개였다.
그래서 우려되는 점이 바로 Single Point Failure(단일 실패 지점)이다.
만약 한 개만 존재하는 Name Node가 만약에 문제가 생기게 된다면, Client Node에서 찾고자하는 파일 블록의 위치에 대해서 물어볼 수 있는 곳이 없어지기 때문에, Name Node의 Single Point Failure에 대한 해결이 필요하다.
Name Node Resilience
메타데이터를 지속적으로 백업한다. Name node가 편집 로그를 Local Disk와 NFS(Network File System)에 동시에 저장하도록 구성을 하는 것이다. 이때 NFS는 다른 랙이나 데이터 센터의 백업 자장소와 연결이 되어있기 때문에 나중에 Name Node가 죽어도 NFS 백업에서 편집 로그라도 살릴 수 있으며, 새롭게 Name Node를 만들어서 되살린 편집 로그를 사용해서 boostrap할 수 있다. 하지만, 백업 데이터를 다시 작성하는데에는 렉이 좀 걸리기 때문에 어느 정도의 정보 손실은 감수해야한다. 하지만, 데이터를 완전히 잃어버린다는 것은 아니다. 약간의 다운타임이 있어도 괜찮은 상황에서는 메타데이터를 지속적으로 백업해서 Name Node의 Single Point Failure 문제를 예방하는 방법으로 괜찮다.Secondary Name Node를 운영한다.
Secondary Name Node는 메인 Name Node와 동시에 운영하지 않는다. 즉, 동적 백업(hot backup)상태가 아니다.
이 Secondary Name Node가 하는 일은 Main Name Node의 편집 로그의 복사본을 유지하는 역할을 한다. 이렇게 유지된 편집 로그 복사본을 사용해서 Name Node의 복구가 필요한 상황에 사용된다.HDFS 연합(Federation)은 이름에서 유추되는 것과 같이, 단일 이름 노드를 확장한다는 개념이 아니다.
HDFS는 많은 수의 작은 파일보다는 대용량 파일을 다루는데 최적화되어있다.
하지만 다수의 작은 파일만 있는 상황이 올 수 있는데, 이러한 경우에는 Name Node는 한계점에 다다를 것이다. 그말인즉, 단일 Name Node만으로는 충분하지 않은 시점이 올 수 있다는 것을 의미한다.
위와같은 이유로 HDFS Federation은HDFS 파일 구조 내에 namespace volume이라고 불리는 서브디렉터리마다 분리된 이름 노드를 지정한다. 그러면 각 볼륨마다 데이터 파일을 읽거나 쓸 때 어떤 이름 노드와 이야기해야 하는지 알 수 있고, Name Node의 업무를 분담할 수 있다.
Name Node 중에서 하나가 다운되면 적어도 데이터의 일부분만 잃어버린다는 것이다. Single Name Node가 다운되어 전체 HDFS 클러스터가죽는 것만큼 재앙적인 상황이 아니다.클러스터에 어떠한 경우에도 다운타임이 허용되지 않는 경우,HDFS High Availability를 사용해서Hot Standby Name Node를 운영한다.
Hot Standby Name Node는 공유되는 편집 로그(Shared edit log)를 활용하는데, Name Node가 HDFS가 아닌 다른 안전한 공유 저장소에 편집 로그를 작성한다.
그리고 Name Node에 문제가 발생하여 다운이 되면,Hot Standby Name Node가 바로 업무를 이어받는다. 이전에 하둡 에코 시스템에서 살펴보았던Zookeeper가 어떤 Name Node가 활성화되어있는지 파악을 하고,Client Node는 우선적으로 Zookeeper와 이야기해서 어떤 이름의 노드와 소통을 해야하는지 알아내고,Zookeeper는 모든 클라이언트들이 한 번에 하나의 Name Node만 사용하도록 통제한다.예를들어 두 개의 Name Node가 동시에 작동할 수 있다고 가정하자. 이렇게 되면, 쓰기 요청을 받을때 한 Name Node는 그 데이터가 어디에 있는지 알고, 다른 Name Node는 모를 수 있다. 그 외에도 읽기 요청이 각 각 다른 Name Node로 전달되는 경우에도 안좋은 경우가 발생한다.
따라서 이러한 상황을 미연에 방지하기 위해서HDFS High Availability는 극단적인 조치를 취하는데, 한 번에 하나의 Name Node만을 사용하도록 사용되지 않는 Name Node의 전원을 물리적으로 차단시켜서 이 노드와는 소통하지 못하도록 한다.
위와같은 처리를 위해서는 많은 구성이 필요하다.
HDFS를 사용하는 방법
HDFS는 어떻게 사용하는 것일까?
(1) 유저 인터페이스를 사용하는 방법
단순히 파일을 복사하고 HDFS의 디렉토리 구조를 시각화하고 싶을 때 사용한다.(마치 HDFS를 거대한 하드 드라이브처럼 활용하는 케이스)
HDFS는 클러스터의 수 많은 컴퓨터에 걸쳐 분산되어 있고, 실패 회복력과 큰 가능성이 있다. 결국에는 파일 시스템을 갖춘 거대한 하드 드라이브인 것이다.
HTTP로 HDFS를 다루는 방법
직접적으로 HTTP로 접근하거나 Proxy 서버를 통해서 할 수 있다. Proxy 서버는 HDFS 머신과 Client 사이에 위치해있으며, 데이터를 분석하기 위해 스크립트를 작성하거나, 어플리케이션 개발을 위해 이 Proxy 서버에 웹 인터페이스도 구성할 수 있다.
이 인터페이스를 구성하는 것이 매우 중요하며, HDFS는 대부분 자바로 코딩되어있고, 자바 인터페이스를 사용한다.
대부분의 언어들은 자바 코드와 소통할 수 있기 때문에 C, Python, Scala등을 사용해도 무관하다. 결국에는 HDFS의 내장 Java 인터페이스와 내부적으로 소통을 할 수 있다.
NFS 게이트웨이를 이용하는 방법
NFS 게이트웨이를 사용해서 HDFS를 사용할 수 있다.
NFS는 네트워크 파일 시스템으로, 원격 파일 시스템을 서버로 마운트한다. NFS를 통해 파일 시스템을 서버에 연결하듯이 NFS 게이트웨이를 통해 HDFS를 리눅스 박스에 연결시킬 수 있다.
그러면 하드 드라이브에 또 다른 마운트 지점이 생기게 되고, HDFS와 전혀 관련없는 다른 프로그램들도 사용할 수 있게 된다.
NFS 게이트웨이를 사용하는 다른 프로그램에게는 그냥 어떤 파일 시스템의 또 다른 파일처럼 보이게 된다는 의미이다.