이번 포스팅에서는 Data 분석 대상에 대한 부분과 이전 1, 2일차때 공부했던 데이터 파이프라인 구성시에 필요한 AWS 서비스 이외에 기본적으로 필요한 AWS 서비스에 대해서 학습한 내용에 대해서 정리해보려고 한다.
(1) Data 분석 대상
우리가 분석할 데이터는 기업의 플랫폼이 되는 웹 또는 앱에서 발생한다.
이전 포스팅에서도 이 부분에 대해서 언급을 했었는데, 이러한 데이터를 이용해서 실제 사용자가 해당 서비스에서 어떤 것을 필요로 하는지, 니즈를 파악해서 기존 서비스를 개선할 수 있다.
데이터는 웹과 앱에서 발생하는 이벤트를 통해서 취득하게 되는데, 사용자가 페이지(화면)에서 특정 카테고리를 클릭하고 어떤 경로로 또는 어떤 depth로 메뉴를 타고 들어가서 정보를 확인하는지, 이러한 일련의 네비게이션 과정에 대해서 파악을 한다.
이러한 일련의 사이클들에 대해서 파악을 하게 되면, 사용자들이 서비스에서 어떻게 메뉴를 구성했을때 주문이 많아졌는지, 그리고 어떤 부분에 관심이 많은지에 대한 파악을 할 수 있다.
더 나아가서 어떻게 데이터 파이프라인을 구성했을 때 가장 효율적으로 데이터를 수집하고 분석을 빠르게 할 수 있는지에 대한 고민도 필요하다.
데이터를 수집할 수 있는 외부 서비스에는 050 시스템, Appsflyer, Adbrix가 있는데, 050 시스템의 경우에는 상담사가 전화한 내용을 전부 Web Hook을 통해서 DB서버에 저장을 하고, 저장된 데이터를 텍스트로 변환하는 작업까지 한다.
그 외의 두 개의 서비스는 다채널 마케팅으로, 어느쪽에 광고를 실었을대 가장 효율이 좋은지 데이터적 근거를 통해 분석할 수 있다.
Google Analytics와 같은 서비스를 통해서도 데이터를 파악 및 분석할 수 있지만, 데이터를 내제화해서 데이터를 일괄적으로 모은 다음에 디테일하게 분석하기 위해서는 별도의 파이프라인 구성이 필요하다.
특정 사용자가 네이버 블로그를 통해서 앱을 설치했다고 가정하자. 사용자가 앱을 설치한 뒤에 앱을 삭제할 수도 있고, 앱을 설치하고 앱을 통해 원하는 정보를 확인할 수도 있다. 이러한 디테일한 사용자의 니즈를 파악하기 위해서는 데이터를 내제화할 필요성이 있다. 그리고 클라우드에는 이러한 데이터 내제화에 도움이 되는 여러 서비스들이 있다.
데이터 파이프라인을 위한 AWS 서비스
앞으로 할 실습에 필요한 AWS 서비스에 대해서 구체적으로 알아본다.
[EC2]

EC2는 AWS의 가상 컴퓨팅 환경 인스턴스로, 서버를 띄울 수 있는 다양한 AMI(Amazon Machine Image)를 제공한다.
(1) AMI(Amazon Machine Image) : 서버에 필요한 운영체제, 소프트웨어들이 적절히 구성된 상태로 제공되는 템플릿으로 EC2 인스턴스를 쉽게 생성할 수 있도록 도와준다.
(2) 인스턴스 타입(유형) : 인스턴스 이미지에서 위한 CPU, 메모리, 스토리지, 네트워킹 등의 여러가지 구성을 제공한다.
(3) 과거에는 아이디/패스워드로 로그인을 했던 반면에, 현재는 Key pair를 사용해서 인스턴스 로그인 정보 보호(AWS는 공용키를 저장하고 사용자는 개인키를 안전한 장소에 보관하는 방식)로 계정을 관리할 수 있으며, 웹 콘솔에서도 조작을 할 수 있다.
(3) 인스턴스 스토어 볼륨 : 임시 데이터 를저장하는 스토리지 볼륨으로 인스턴스 종료시 삭제된다.
(4) Amazon EBS(Elastic Block Store) : Amazon EBS를 사용해서 영구 스토리지 볼륨에 저장한다. 스토리지는 사용되지 않을때에는 중지상태로 만들어두면 저렴하게 사용할 수 있다.
(5) 인스턴스와 Amazon EBS 볼륨 등의 리소스를 다른 물리적 장소에서 액세스할 수 있는 리전 및 가용 영역
(6) 보안 그룹을 사용해서 인스턴스에 연결할 수 있는 프로토콜, 포트, 소스IP 범위를지정하는 방화벽 기능 제공 (특정 IP로 부터 접근을 허용할 수 있도록 보안정책을 넣어줄 수 있다.)
(7) 탄력적 IP 주소(EIP) : 동적 클라우드 컴퓨팅을 위한 고정 IPv4 주소
(EC2를 띄우게 되면 설정되는 Public IP의 경우에는 중지 후 재 실행시에 DHCP에 의해 Public IP가 변경될 수 있다. 이 경우에는 EIP를 설정해서 인스턴스에 할당을 해주면 Public IP가 변경되지 않는다. 다만 사용되지 않을 때 비용이 발생한다.)
(8) 태그 : 사용자가 생성하여 Amazon EC2 리소스에 할당할 수 있는 메타 데이터
모든 서비스에 태그를 할 수 있는데, 태그를 통해 비용산정/특정 서비스/특정 팀에서 사용하고 있는 리소스를 파악할 수 있다. (NAME TAG) 해당 인스턴스가 어떤 용도로 쓰이고 있는지 태깅하는 습관을 들이도록 한다.
(9) AWS 클라우드에서는 논리적으로 격리가 되어있지만, 원할때마다 고객의 네트워크와 간편히 연결할 수 있는 가상 네트워크,(Virtual Private Clouds(VPC))
[S3]

지속적으로 파일을 관리해줘야되기 때문에 생명주기를 얼마나 유지해줘야 할지 라이프사이클을 정의하고, 일정 기간이 지나면, AWS S3 Gracier(온프레미스의 테입 드라이브와 같은 서비스)서비스를 활용하여 Archieving을 해준다.cost는 저렴하고, 테입 드라이브처럼 아카이빙하기는 좋은데, 읽을때에는 느리다는 단점을 가지고 있다.
버킷
Amazon S3에 저장된 객체에 대한 컨테이너로, 모든 객체는 특정 버킷에 포함이 된다. 일종의 윈도우 폴더와 같은 개념으로 이해하면 된다.객체
Amazon S3에 저장되는 기본 객체로, 객체는 객체 데이터와 메타 데이터로 구성이 된다. 일종의 윈도우 폴더내의 파일로 생각하면 된다.키
버킷 내 객체의 고유 식별자로, 버킷 내 모든 객체는 딱 하나의 키를 갖는다. 버킷, 키 및 버전 ID의 조합이 각 객체를 고유하게 식별하기 때문에Amazon S3 = "버킷 + 키 + 버전"과 객체 자체 사이의 기본 데이터맵으로 간주할 수 있다. 그리고 형상관리 기능도 지원한다.
[RDS]
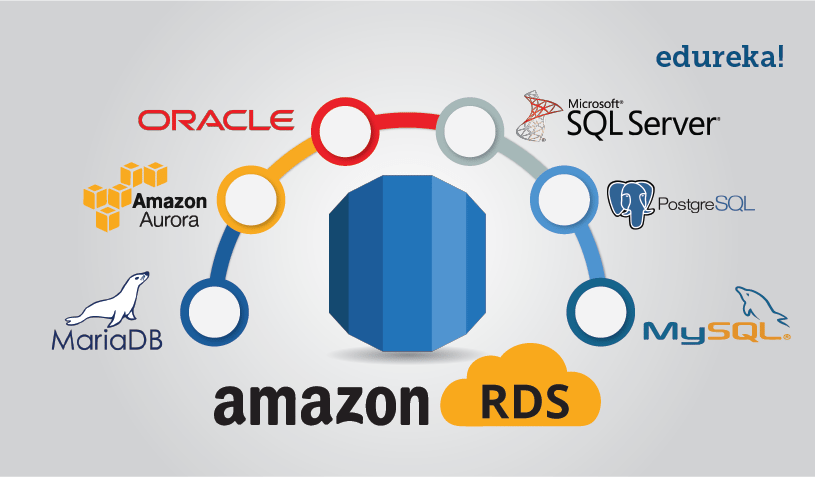
Amazon RDS는 Amazon Relational Database Service의 약자로 클라우드에서 관계형 데이터베이스를 더욱 간편하게 설정하고 운영/확장 할 수 있도록 도와주는 서비스이다.
하드웨어 프로비저닝(=설치), 데이터베이스 설정, 버그 패치 및 백업과 같은 시간 소모적인 관리 작업을 자동화하면서 비용 효율적이고 크기 조정이 가능한 용량을 제공한다.
지원 가능한 데이터베이스 엔진으로는 위의 첨부한 그림에서와 같이 Oracle, MySQL, Microsoft SQL Server, PostgreSQL, MariaDB, Amazon Aurora (MySQL, PostgreSQL 두 오픈소스의 약점을 보완)를 제공한다.
[API Gateway]

최근에 마이데이터 서비스로 인해서 API Gateway service도 많이 언급되고 있다. 한 유저가 특정 데이터를 A사이트 -> B사이트로 이전해달라고 요청시, RESTFul Application이 되어있으면, API를 통해서 데이터 이전을 해줄 수 있다.AWS 서비스 내의 서비스를 연결시켜주는 관문적인 역할을 해준다.
서비스와 리소스명이 들어오면, 해당되는 리소스로 switching해주는 Proxy의 역할도 해준다.
어떤 규모든지간에 개발자가 API를 생성/게시/유지 관리/모니터링 및 보호할 수있도록 해주는 AWS의 서비스이다. 모바일 및 웹 어플리케이션에서 AWS 서비스에 엑세스할 수 있는 일관된 RESTFul Application Programming Interface(API)를 제공한다.
사용자는 RESTFul API를 생성, 구성, 호스팅해서 어플리케이션의 AWS 클라우드 자원에 액세스를 할 수 있다.
[CloudWatch]

서비스도 중요하지만 서비스별로 모니터링할 수 있도록 만들어진 서비스이다.
지금은 많이 개선되었지만, 각 이벤트마다 형식이 서비스마다 다르기때문에 모니터링에 있어서 어려움이 있다. 따라서 이에대한 고민이 필요하다.
- Amazon Web Service(AWS)리소스와 AWS에서 실시간으로 실행중인 어플리케이션을 모니터링한다.
- 리소스 및 어플리케이션에 대해 측정할 수 있는 변수인 지표를 수집하고 추적할 수 있다.
- 경보는 알림을 보내거나 정의한 규칙을 기준으로 모니터링하는 리소스를 자동으로 변경한다.
이전 학습에 배웠던 Amazon EMR, Amazon ES, Amazon Kinesis, Amazon Athena, Amazon Lex, Amazon Forecast등의 이벤트 로그들을 Amazon CloudWatch를 통해서 실시간으로 모니터링 할 수 있으며, delay time은 2-3분정도 된다고 한다.
리소스가 부족할때에는 프로그램으로 리소스를 확장할 수도 있고, 경보나 알림을 이메일이나 SNS로 푸쉬알람을 줄 수 있는 기능을 줄 수도 있다.
데이터를 핸들링하는 부분에 있어서는 리소스가 부족한 부분이 생길 수있다. 예를들어, Kinesis와 같은 큐도 제한(LIMIT) 용량을 가지고 있는데, CloudWatch가 모니터링을 하고있다가, 용량의 70-80%가 차는 경우, 샤드를 늘려줄 수 있도록 프로그램을 짤 수 있다.
이를 통해, 로그를 수집하고 있을때 loss가 없게 파이프라인을 구성할 수 있다.
CloudWatch는 1 Service - 1 Monitoring 지원을 한다.