
이번 포스팅에서는 데이터 파이프라인을 구축함에 있어 어떤 방식으로 접근을 해야하는지, 그리고 고려해야되는 부분과 실무에서 예외발생이 발생하며, 대체방안으로 어떤 부부을 선택해야되는지에 대해 정리해보려고 한다.
(1) Data & AI LANDSCAPE
2015년도 Bigdata landscape에서는 서비스가 셀 수 있을 만큼의 갯수였는데, 2020년 기준으로(상단의 이미지 참조), 여러 데이터 기반의 회사가 등장하고, 대표적으로 넷플릭스가 등장하면서 분석 및 추천에 많은 공헌을 하였다. 이러한 서비스들은 오픈소스화하는 경우가 많았고, 오픈소스화된 서비스들은 클라우드 진영에서 자체 서비스화하기 위해 더욱 다양한 서비스들이 등장하기 시작했다.
최근에 페이스북, 트위터, 리프트의 기업들이 데이터 기반으로 비즈니스를 확대하면서, 여러 서비스들을 운영하기 시작했다.
[참고]Airflow는 Airbnb에서 만든 전체 플로우를 컨트롤할 수 있는 툴(workflow tool)인데 오픈소스화하면서, 이 것을 기반으로 클라우드 진영에서는 자체 서비스화하기 위해서 다양한 서비스들이 등장을 하였다.
그 외에도 데이터 예측을 위해 AI 진영에도 다양한 서비스들이 등장하였다.
(2) 데이터 파이프라인 구축에 접근하는 방법
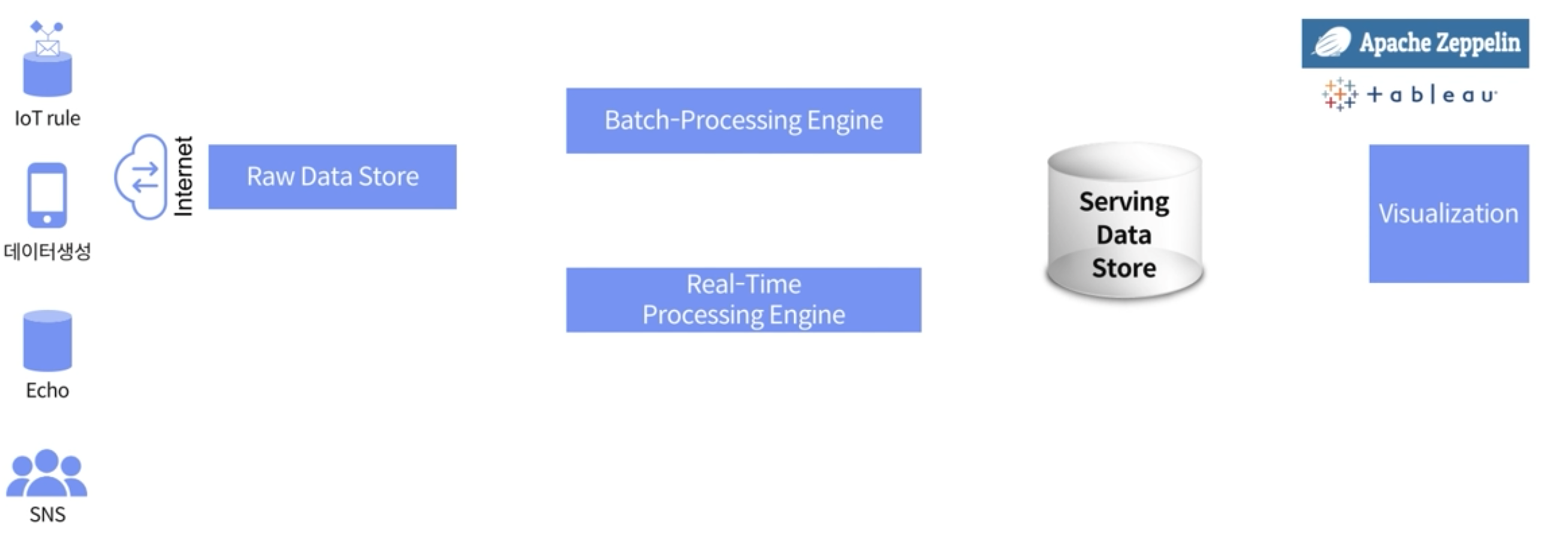
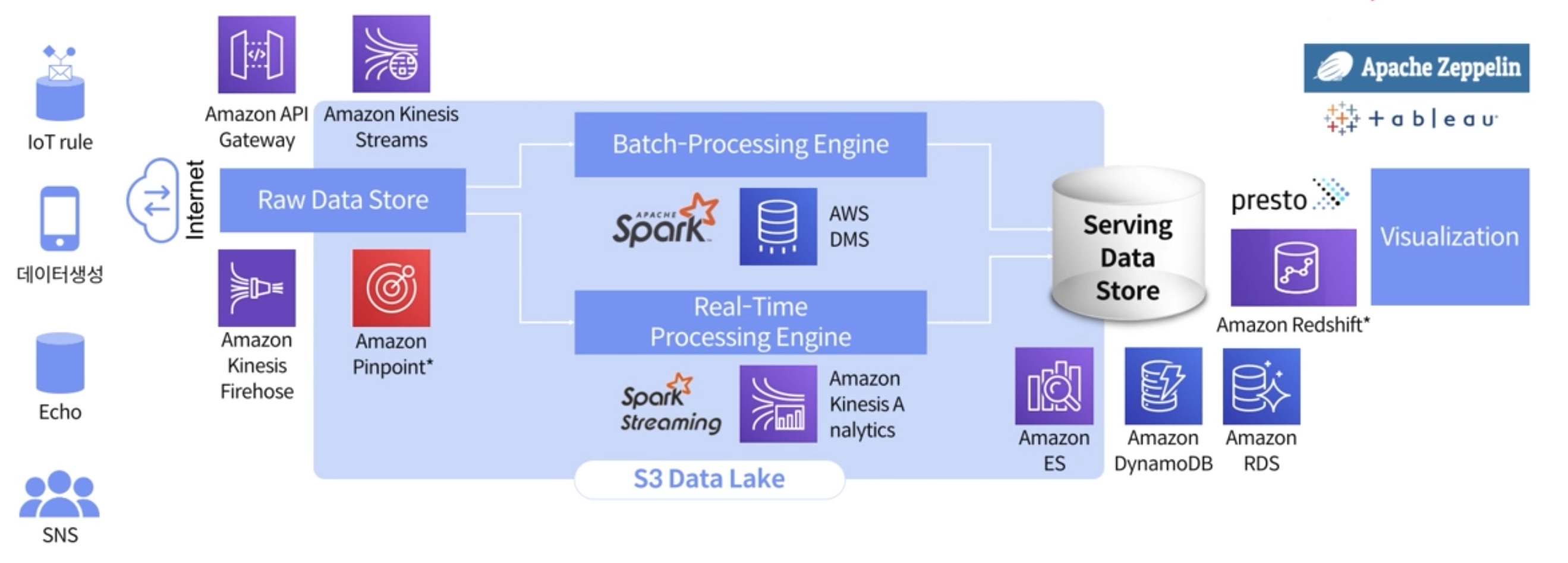
우선 많은 Architecture중에서 Lambda Architecture로 접근하는 이유는, 데이터 파이프라인 구축할때 cost측면에서 적고, 다양한 Architecture를 구성할 수 있다는 면에서 장점이 있기 때문이다.
IoT기기나 SNS, 스마트 기기로부터 모인 데이터는 Raw Data의 형태로 Raw Data Store에 저장된다. 데이터에 대한 비즈니스적 요청에 의해 Batch-Processing-Engine을 통해서 처리를 하기도 하고, Real-Time-Processing-Engine을 통해서 처리를 하기도 한다.
만약 Batch-Processing에 대한 비즈니스적 요구가 있다면 Batch-Processing-Engine을 통해서 Serving Data Store에 Raw Data Store의 데이터를 저장하게 된다. (보통 이 일련의 과정을 ETL(Extract/Transformation/Load)작업이라고 한다)
만약 Real-Time에 비즈니스적 요구가 있다면 Real-Time Processing Engine을 활용해서 Serving Data Store에 저장을 하게 된다.
저장된 Serving Data Store의 데이터는 기증을 해서 Batch나 Real-Time Processing Engine을 통해 어느 수준의 데이터를 저장할지 결정을 하게 된다.
[저장된 데이터의 사용]
그렇게 저장된 데이터를 기반으로 분석이나 DW(Data Warehouse)(여러 dataset들을 관련성있는 것끼리 묶어서 저장해놓은 format)을 기반으로 DM(Data Mart)를 구성한다.
DM는 시각화 할 수 있는 장표단위로 구성을 하거나, AI와 관련된 Feature store의 개념으로 AI를 돌릴 수 있는 dataset들을 구성할 수 있다.
데이터 분석가들이 그래프를 통해서 분석을 할 수 있기 때문에, 최종적으로 데이터 시각화를 하게 된다.
[Raw Data Store -> AWS S3]
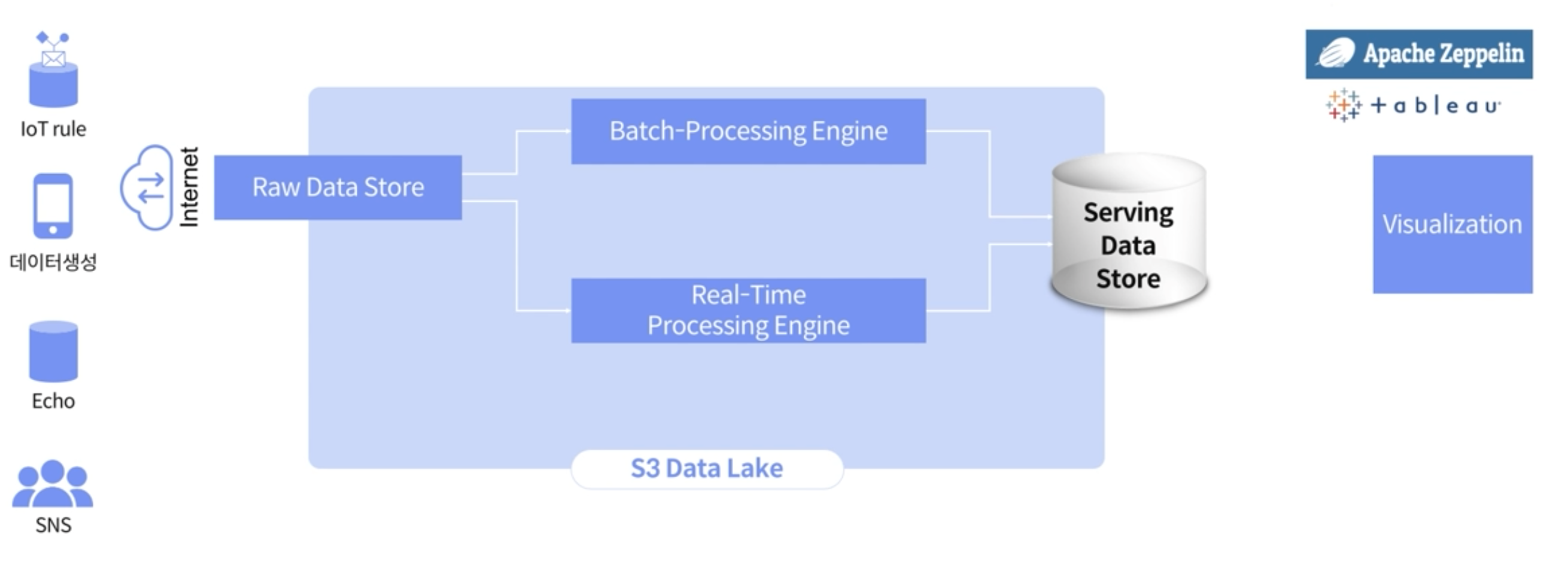
AWS에서의 Object storage인 S3 Data Lake에 저장을 하기 위해서 아래와같이 Batch-Processing Engine과 Real-Time Processing에 mapping되는 각 각의 AWS의 서비스들을 선정한다.
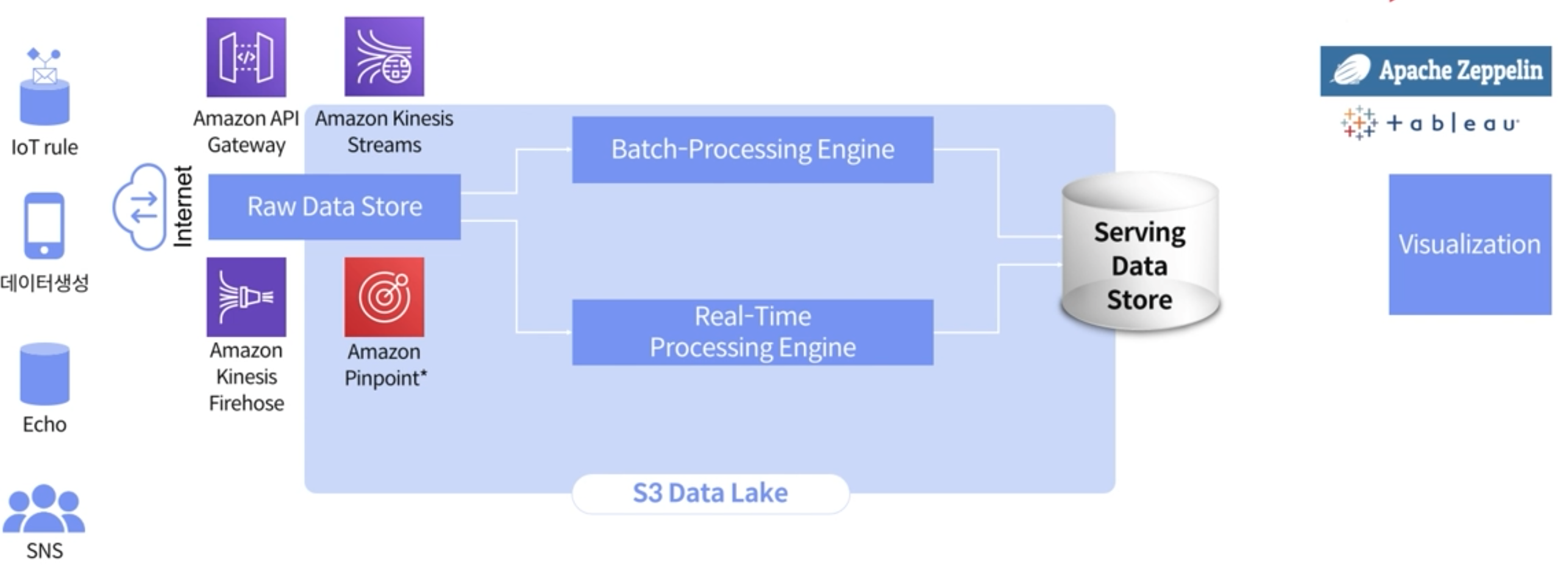
Amazon API Gateway / Amazon Kinesis Streams / Amazon kinesis Firehose / Amazon Pinpoint
위에 정리한 구성으로 접점을 잘 연결해서 파이프라인을 구축한다.
위의 AWS 서비스들을 구체적으로 알아보자.
Amazon Pinpoint는 일종의 CRM 서비스로, 특정 웹이나 앱에서 발생하는 이벤트를 통해 마케팅을 할 수 있는 툴킷이다.
실제로 Amazon API Gateway + Amazon Kinesis Streams 구성을 통해서 데이터를 수집하는 것이 가장 좋지만, Amazon API Gateway의 비용적 부담이 될 수 있다.
따라서 Pinpoin의 경우에는 SDK를 가지고 웹이나 앱을 배포하게 되면, 우선 저장하는데까지의 비용은 크지 않기 때문에, 다음과 같은 구성으로 Amazon Pinpoint -> Amazon Kinesis Stream -> Amazon Kinesis Firehose -> S3 로 구성하는 것이 상대적 비용적 절감을 가져올 수 있다.
이처럼 비용적 측면을 고려하여 수집에 대한 또 다른 아키텍처를 만들 수 있다.
(AWS 자격증을 이제 막 공부하는 입장이지만, 왜 비용적 부분에 대한 공부도 필요한지에 대해서 이제 알게 되었다. 서비스 운영에 있어 cost측면에서의 고려는 중요하다.)
S3 Data Lake에 데이터 저장된 이후
S3에 데이터가 저장이 되면, 텍스트나 JSON 형태로 데이터가 저장이 된다.
그 기반으로 데이터적 요구사항에 따라서 데이터를 처리하게 되는데, 가장 일반적으로 Batch Processing Engine을 통해 데이터를 처리한다.
통상적으로 현재시간-1일 기준의 데이터를 가지고 처리한다.
저장된 데이터를 가지고 이제 ETL과정을 진행한다. 데이터를 트랜스폼해서 저장을 하는데, AWS에서 저장할때는 T1,T2이라는 용어를 사용한다. (회사마다 사용되는 용어 상이)
저장된 데이터를 DM 데이터로 저장하는 이 3가지 스탭이 보통 일반적인 과정이다.
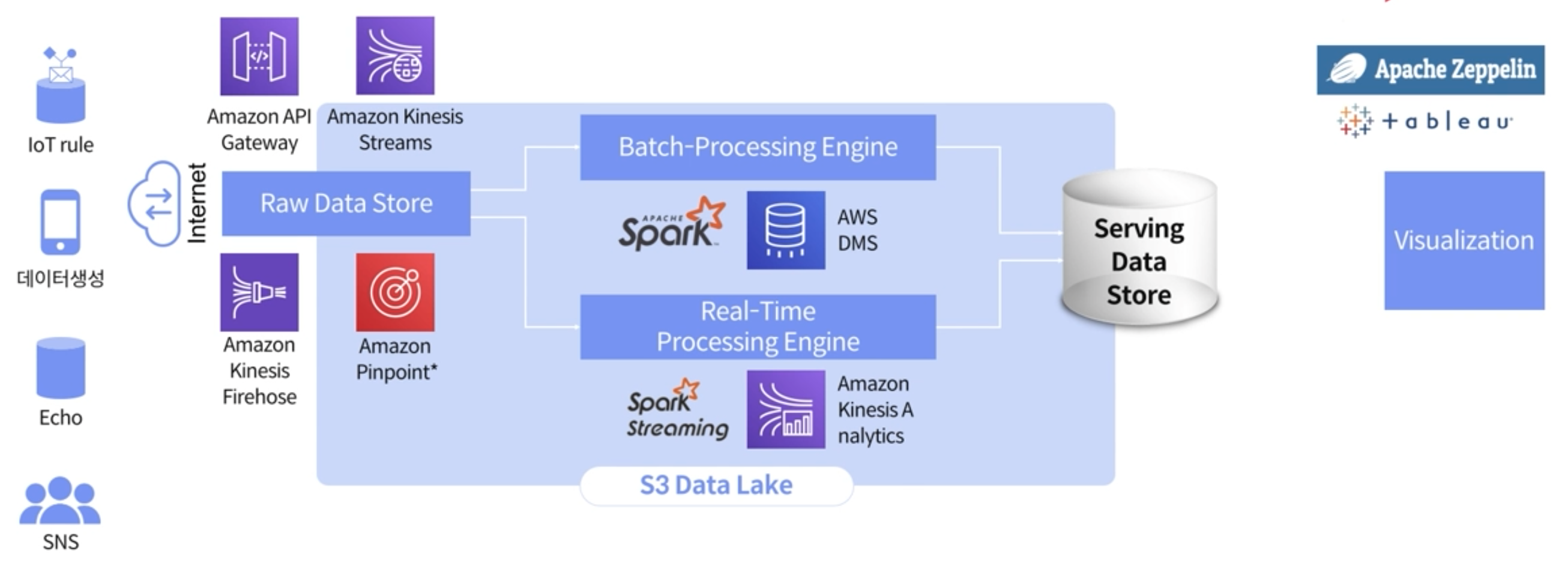
S3 Data Lake에 저장된 데이터 전처리
S3 Data Lake에 저장된 데이터는 일련의 데이터 전처리 과정을 거쳐야한다. 전처리를 위해서 사용되는 AWS 서비스에는 Batch-Processing시에 Spark/AWS DMS이 필요하며, Real-time Processing시에는 Spark streaming/Amazon Kenesis Analytics가 있다.
앞선 포스팅에서도 이미 정리를 했지만, AWS에는 EMR이라는 하둡 Eco System과 관련된 전반적인 서비스가 설치되어있는 서비스가 있다. 배포하는데 10분 내외로 매우 짧기 때문에 손쉽게 Batch-Processing을 할 수 있다.
AWS의 DMS(Data Managing Search)는 이기종 데이터를 트랜스폼하는데 사용한다. 웹이나 앱을 OLTP하기 위해 현재 서비스에서 활용되고 있는 DB를 가져와야되는 경우가 있다. 예를들어, 고객 및 상품 데이터의 마스터분석을 위해서 현재 운영중인 서비스의 데이터베이스에서 그대로 데이터를 가져와야한다. 이 경우에 DMS를 사용한다.
SPARK에서 현재 운영중인 서비스의 디비를 가져올 수도 있는데, 이 경우에는 서비스에 부하를 줄 수 있다. 이러한 이유때문에 AWS DMS를 사용하도록 한다.
AWS의 서비스를 선택할때에는 서버부하와 코스트면을 고려해서 선택해야한다.
Real-Time Process선택시에도 AWS의 EMR을 사용해서 간단하게 Spark streaming가 설치된 환경을 구축해서 사용할 수 있으며, Spark streaming을 사용하는데 있어, 단점은 항상 켜놔야되는 점이 있고, Amazon Kinesis Analytics를 통해 실시간으로 데이터를 분석할 수 있다.
전처리 이후에 Serving Data Store와 관련된 AWS 서비스
전처리 이후에 Serving Data Store와 관련된 AWS 서비스에는 Amazon ES(Elastgic Search)/Amazon DynamoDB/Amazon RDS가 있다.
Amazon ES(Elastic Search)
Amazon ES는 데이터량이 지속적으로 많아지는 서비스에는 부적합하다. 계속 컴퓨팅 및 스토리지 영역을 확장해야되는 필요성이 있기 때문이다. 이로인해 지속적인 운영으로인해 비용이 발생한다.그럼 어떤 경우에 Amazon ES가 적합할까? 신규 서비스를 런칭했을때 들어오는 서비스 태깅, 가입, 페이징에 대한 분석을 빠르게 하기 위해서 활용할때 유용하다.
데이터 유지는 보통 2주정도하고 여유가 있다면 한 달정도 잡고 분석하기 좋은 서비스이며,
Amazon DynamoDB, Amazon RDS(MySQL과 같은 DBM포함)가 있다.
Amazon Redshift
Amazon의 Redshift는 칼럼 베이스의 분석툴로, 온프레이스 오라클의 대표적인 서비스들을 포함한다. 데이터 분석에 많이 사용된다.
그외에도 AWS 내에 포함되어있는 presto 서비스를 사용해서 SQL을 활용해서 데이터베이스를 분석할 수 있으며, 어플리케이션 중에서 제일 괜찮아서 활용도가 높고, 쉽게 시각화도 가능하다.
이런 일련의 데이터 파이프라인적 접근을 이해하고, 람다 아키텍처의 구성을 이해하고 있다면, 나중에 CSP(Cloud Service Provider)가 바뀌었을 때에도 이런 서비스들을 맵핑하고 데이터의 인풋과 아웃풋 포멧을 정의한다면 쉽게 파이프라인을 구축할 수 있다.
ML/DL에서 사용되는 데이터 구성
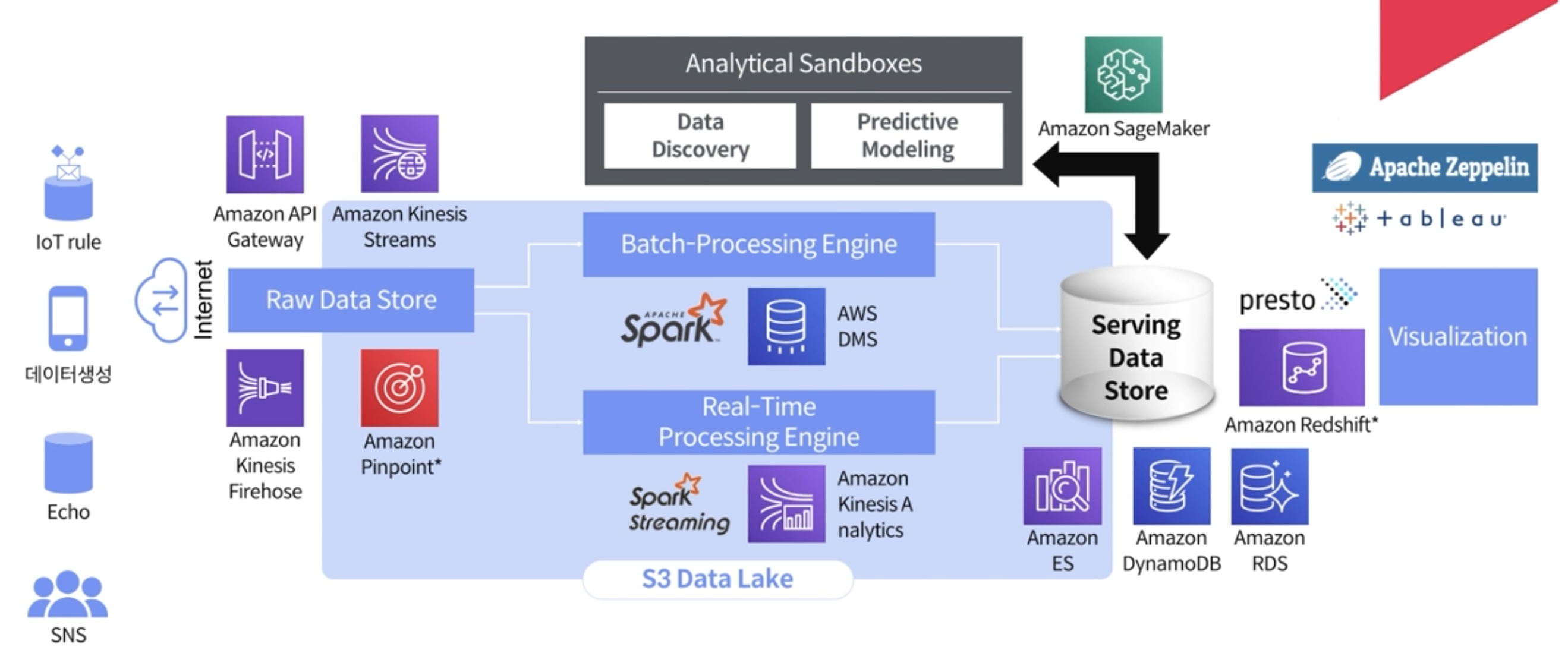
Serving Data Store가 구축이 되고, 자연스럽게 데이터를 보게 되면, Data Discovery/Predictive Modeling 즉, ML/DL에 대한 니즈 예측값에 대한 데이터를 구성할 수 있다.(우선 서빙 데이터 스토어를 제대로 구성하는 것이 중요하다!)Serving Data를 제대로 구성해야만 예측값을 구하기 위한 코스트를 줄이기 위한 방법중 하나이다.
Serving Data Store가 구성이 안되었는데, Raw data 스토어를 통해서 Amazon SageMaker나 툴들을 사용해서 predict ML 코딩을 위해서 들이는 코스트 보다는 데이터 전처리에 대한 코스트가 크기 때문에 이 방법은 비추한다.
(코스트가 많이드는 파이프라인)
S3 Data Lake에 쌓인 데이터 관리
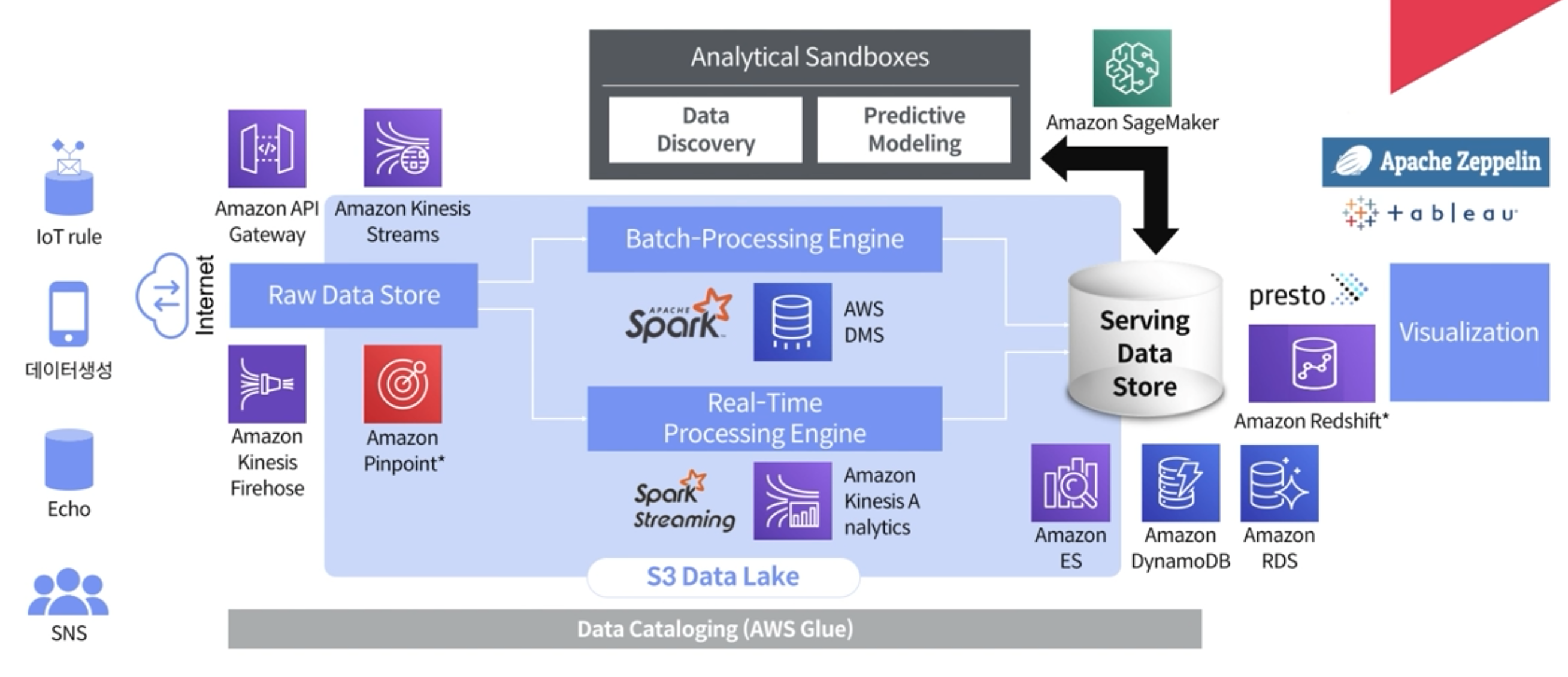
S3에 데이터가 많이 쌓인다. 과거에는 DBMS를 많이 사용했고, DBMS의 데이터를 관리하고 Archiving해서 테입 드라이브에 저장을 했다.
현재는 AWS 서비스 중에서 Glacier 서비스가 있는데, S3중에서 최 하위 제일 느린 서비스인데, Archiving 하기 좋다. 이 서비스에 Archiving 할 수 있는 생명주기를 가져가는 것이 좋고, Data Cataloging은 하둡같은 곳에서 메타스토어라고 하는데, 메타 스토어를 통해서 관리해줘야 분석할 수 있는 사람이 메타데이터를 통해서 분석을 빠르게 해줄 수 있다.
S3 DataSecurity & Governance
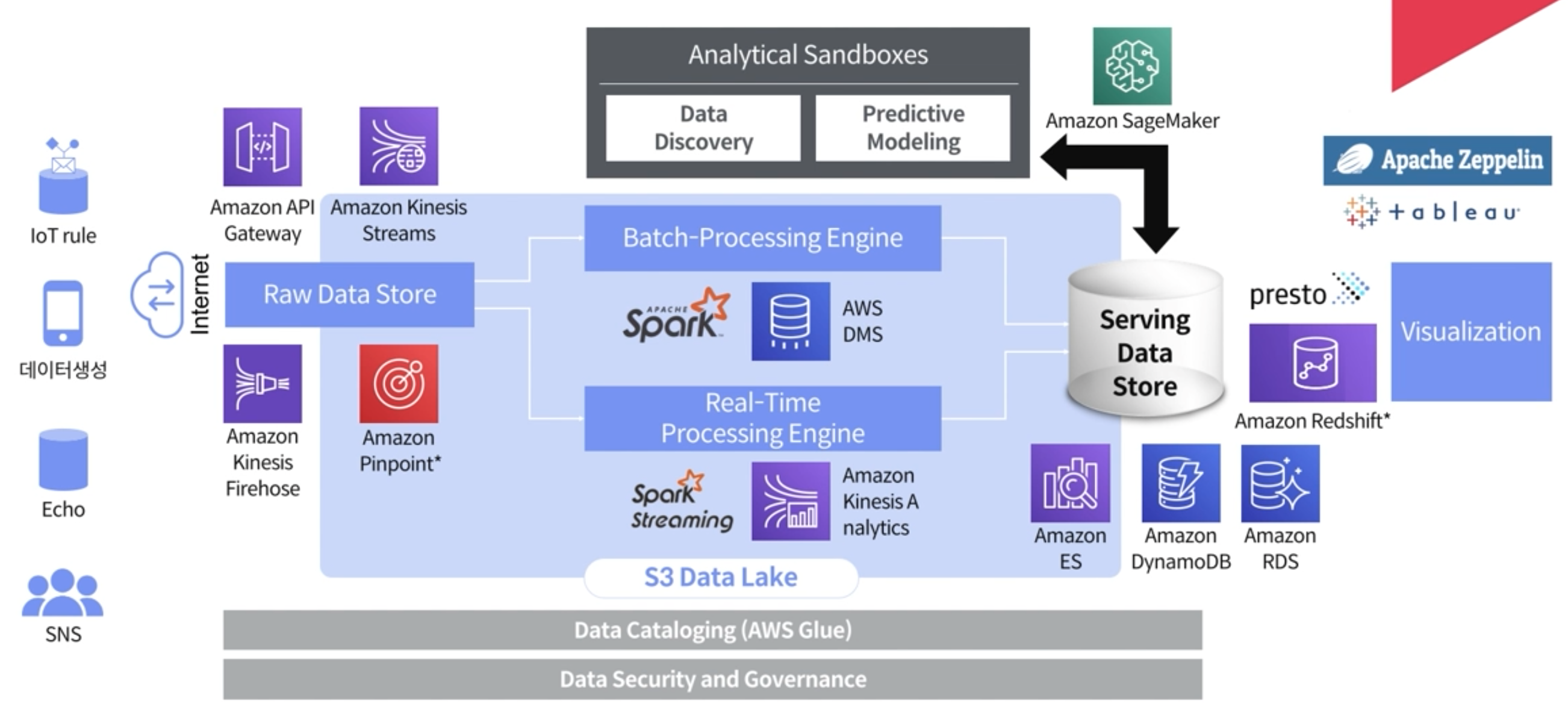
생명주기는 Governance에 해당되는데, 이 부분을 잘 고려해서 파이프라인 구축을 시작해야한다. 처음부터 완벽할 수 없고, 비어있는 부분이 많고, 발전시킬 부분에 대해서 고려를 해야하면서 작업을 해야한다. 이와 관련된 많은 CSP 서비스들이 등장하고 있다.
이제 앞서 배운 파이프라인 구축에 접근하는 방법을 통해 나만의 파이프라인, 플랫폼을 구성하도록 반복학습을 하고 연습을 해야겠다.