이번 포스팅에서는 하둡의 생태계에 대한 전반적인 구성에 대해서 정리해보는 그 네번째 시간으로, Hadoop Ecosystem의 Core 영역을 지나 외부 데이터 스토리지 영역(External Data Storage)에 대해서 알아보도록 하겠다.
기존에 하고 있던 개발관련 공부의 분량이 많아서 아주 가끔씩 시간을 내서 하둡에 대해서 공부를 하고 있는데, 처음에는 너무 막막해서 어려웠지만, 지금은 그래도 어느정도 이 친구가 어떤 기술스택들의 집합체이고, 각자가 어떤 역할을 하는지에 대해서 정도만 개괄적으로 알게 된 것 같다.
그냥 새로운 사람을 만났을 때 생김새와 이름, 사는 곳 정도만 알고 있는 수준일테지만, 좀 더 깊이 있게 알아가다보면 어느 순간 정말 이 기술에 대해 어느정도 잘 알고 있다고 말 할 수 있을 날이 오지 않을까 싶다.
자 그럼 시작해보자.
[STEP 1]
사실 이전에 Core Hadoop Ecosystem 영역에 있던 HBase도 이 External Data Storage의 범주에 속하지만 하둡 스택의 일부이기 때문에 빠져있다.
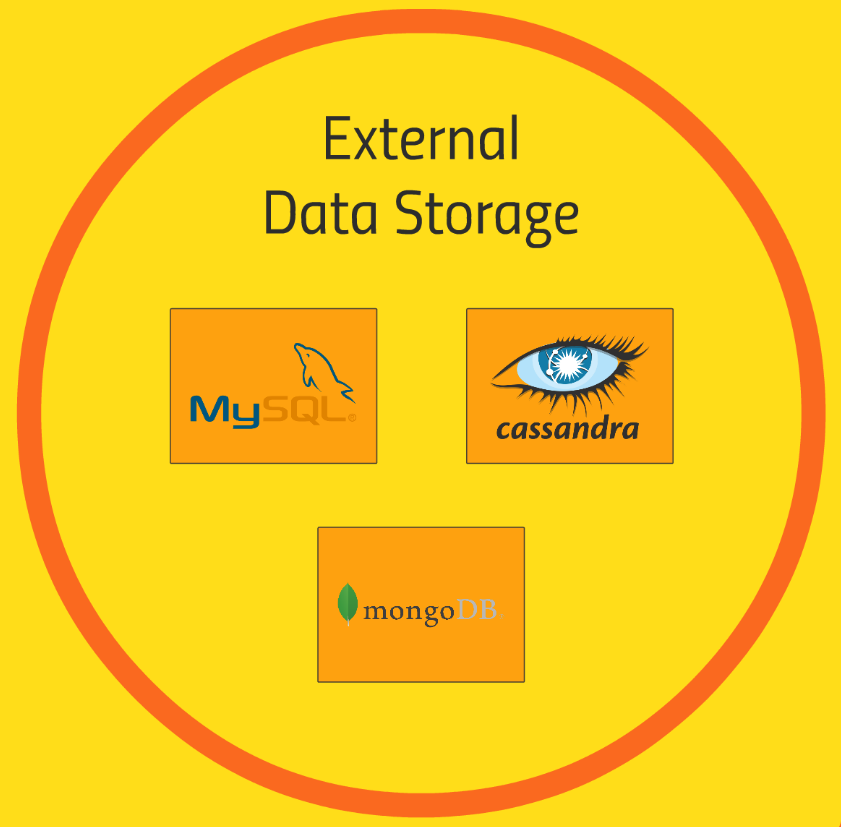
위의 외부 데이터 스토리지 영역에서 볼 수 있듯이, MySQL은 물론이고 어떤 SQL 데이터베이스라도 클러스터와 통합해서 사용할 수 있다.
이전에 배웠던 Sqoop을 사용해서 우리 클러스터로 데이터를 가져올 수 있다는 것을 배웠고, 반대로 MySQL로 내보낼 수도 있다.Spark와 같은 여러 기술은 JDBC나 ODBC 데이터베이스에 기록을 할 수 있고, 중앙 데이터베이스에 직접 저장하거나 필요하다면 그곳에서 결과를 검색할 수도 있다.
Cassandra와 MongoDB는 HBase처럼 ‘기둥형 데이터 스토어’이며, 웹 애플리케이션 등에 데이터를 실시간으로 노출하는데 활용할 수 있다.
고로 실시간 어플리케이션과 클러스터 사이에 Cassandra나 MongoDB 같은 층을 만들어두는 것을 추천한다고 한다.
Cassandra와 MongoDB 둘 다 많은 처리량을 가진 간단한 ‘키-값 데이터 스토어’를 사용함에 있어 인기있는 선택으로, MySQL, Cassandra, MongoDB는 모두 클러스터와 통합할 수 있는 외부 데이터베이스이다.
[STEP 2]
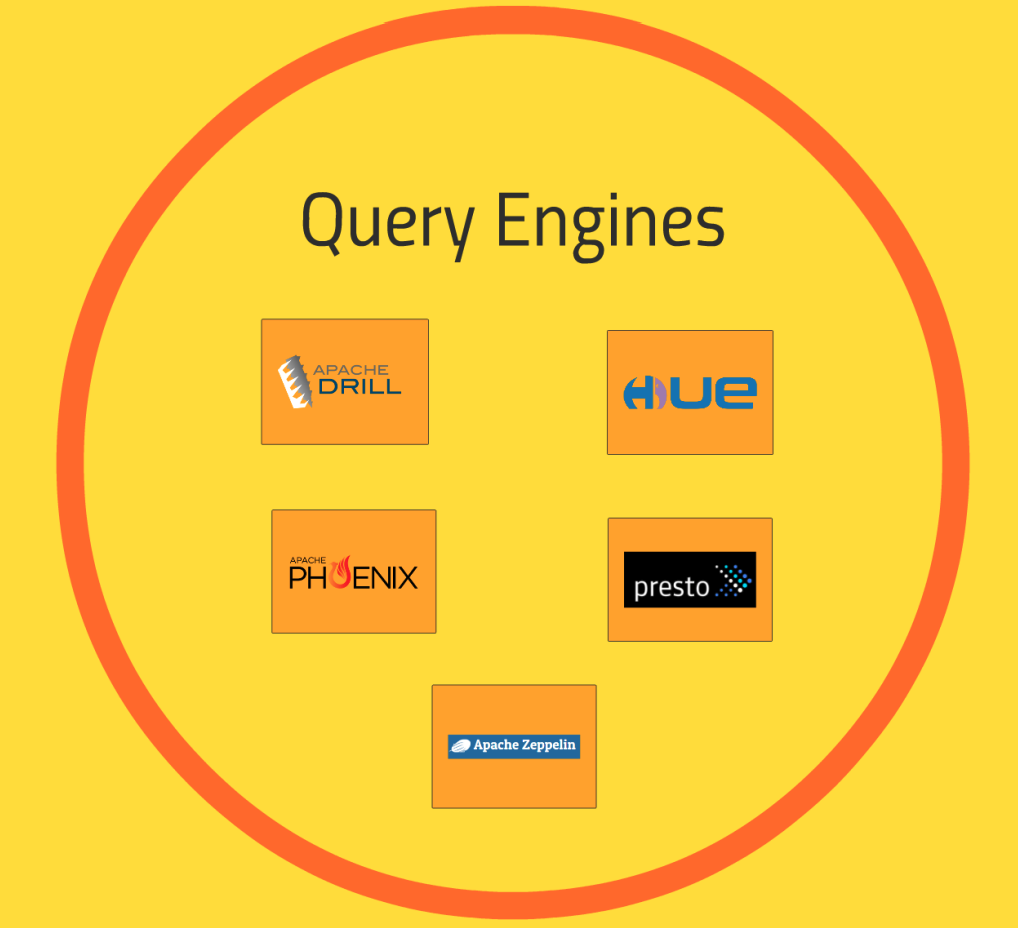
클러스터 위에서 작동하는 쿼리엔진에는 몇 가지가 있는데, 이 기술을 사용해서 대화형으로 SQL 쿼리를 입력할 수 있다. 위의 원 안의 기술들이 다른 원 안의 기술들과 꼭 들어맞지는 않는다.Hive도 비슷한 일을 할 수 있는데, Hive는 Hadoop과 더 견고하게 엮인 기술이라 위의 외부 데이터 스토리지 범주에 포함되어있지 않지만, Hive도 데이터 쿼리하는데 사용된다.
Apache DRILL은 또 하나의 멋진 기능으로, 다양한 NoSQL, 데이터베이스에 SQL쿼리를 작성해서 사용할 수 있도록 도와준다.
예로 DRILL은 Hbase, Cassandra, MongoDB의 데이터베이스와 소통을 할 수 있으며, 소통한 내용을 엮어서 이질적인 데이터 스토어들에 걸쳐 쿼리를 작성하고, 그 결과를 한데 모아줄 수 있다.
[STEP 3]
HUE는 Hive, HBase에 잘 작동하는 쿼리를 대화형으로 생성할 수 있도록 도와준다. 실제로 Cloudera에서는 HUE가 Ambari의 역할을 담당하여, 모든 것을 내려다 볼 수 있도록 시각화하고 전체 Hadoop 클러스터에 쿼리를 실행한다.
[STEP 4]
Apache PHOENIX는 Apache DRILL과 비슷한데, 전체 데이터 스토리지 기술에 걸쳐 SQL 스타일의 쿼리를 할 수 있게 한다. 한 단계 더 나아가서 ACID(Atomicity, Consistency, Isolation, Duration) OLTP를 제공한다.
이를 통해 NoSQL, Hadoop 데이터 스토어에 ACID가 보장되면, 관계형 데이터베이스의 관계형 데이터 스토어와 매우 비슷해진다.presto 또한 전체 클러스터에 쿼리를 실행할 수 있는 또 다른 방법이며, Apache Zeppelin은 클러스터와의 상호작용과 사용자 인터페이스를 노트북 유형으로 접근하는 새로운 관점을 채택했다.
앞서 설명한 모든 기술은 쿼리를 실행하고 별도의 코드를 작성할 필요 없이 클러스터에서 어떤 의미를 추출하는 작업을 수행한다.
[하둡이 어려운 이유?]
여지까지 봐도 어렵게만 느껴지지만, 모든 기술을 사용하고 이해하기는 상대적으로 쉽다고 한다.
다만, 하둡이 어려운 이유는 이렇게 많은 기술들이 있고, 서로 중복되는 기능들이 많기 때문이다.
하지만, 그 기술간의 차이점은 무엇인지, 무엇을 선택할 것인지,그리고 어떻게 종합해서 현실의 문제를 해결할 것인지를 알고 있다면, 그것이 바로 기술자를 고용해서 쓰는 이유이다.