이번 포스팅에서는 학습 16일차에 Kaggle에 있는 타이타닉 생존자예측 dataset을 분석하고, 분석한 dataset을 시각화하는 연습한 내용을 정리하려고 한다. 이번 미니 프로젝트를 통해 얻었던 나 자신에 대한 피드백은 우선 첫 번째 dataset에 대한 사전 분석이 부족했다는 것이다. 그리고 두 번째, DataFrame과 시각화 작업에 대해 연습이 부족하여 작업함에 있어 미숙한 부분이 많았다.
이 피드백을 통해 알게된 개선해야 될 부분에 대해서는 앞으로 차근차근 채워가도록 해야겠다.
타이타닉 생존자 예측 dataset
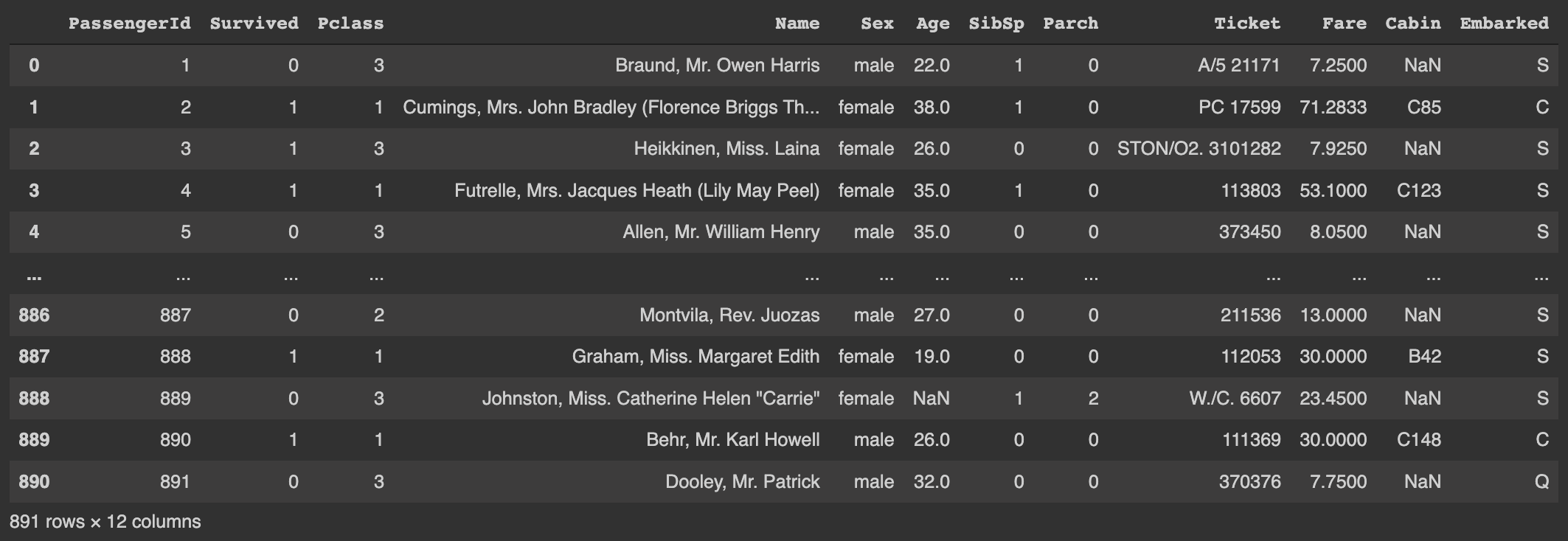
주어진 dataset은 총 12개의 칼럼과 891개의 행으로 구성되어있다. 즉, 한 사람당 총 12 종류의 정보를 포함하고 있다. 특정 승객의 새존 여부를 알아보려면 survived 항목의 값을 살펴보면 된다. (1:생존) 주어진 test.csv 파일의 구조는 train.csv 파일과 거의 동일하지만, survived 항목이 없다.
1 2 3 4 5 6 7 8
import pandas as pd import numpy as np # 데이터 분석을 위한 NumPy import matplotlib.pyplot as plt # 데이터 시각화 라이브러리 import seaborn as sns # 데이터 시각화 라이브러리
train_df = pd.read_csv('train.csv')
print(train_df)
타이타닉 dataset 분석
데이터셋을 시각화하고 결론을 도출해내기 전에는 우선적으로 주어진 dataset에 대한 분석이 필요하다. 이번 미니 프로젝트에서 간과했던 부분이었는데, dataset이 주어졌다면, 우선적으로 주어진 dataset의 columns 구성(df.columns.values),데이터 자료 구성 정보(df.info())를 확인해야한다.