이번 포스팅에서는 하둡의 생태계에 대한 전반적인 구성에 대해서 정리해보려고 한다. 하둡은 다양한 기술들의 집합체로, 총 3개의 세션으로 구분할 수 있다.
우선 첫 번째 Query Engine 5개의 기술스택, 두 번째 Core Hadoop Ecosystem으로 16개의 기술스택, 세 번째 External Data Storage로 3개의 기술스택, 도 합 24개의 기술들로 구성이 되어있다.
아직 막 하둡의 개념정도만 공부하고 있는 이 시점에 이렇게 방대한 하둡의 생태계에 대해서 정리하는 이유는 하둡의 전체적인 생태계를 이해하고 숲을 그려놓은 상태에서 부분 기술들을 학습하게 되면, 나중에 해당 기술스택이 왜 쓰이는지, 어떤 기술스택이 어떤 기술 스택의 대체로 사용이 될 수 있고 어떤 상황에서 어떤 기술스택 간의 조합이 적절한지에 대한 판단을 할 수 있기 때문이다.
아직은 다 알지도 알 수도 없지만, 지금은 하둡의 생김새에 대해서 알아보자.
우선, 하둡의 가장 핵심적인 부분부터 살펴볼겠다.
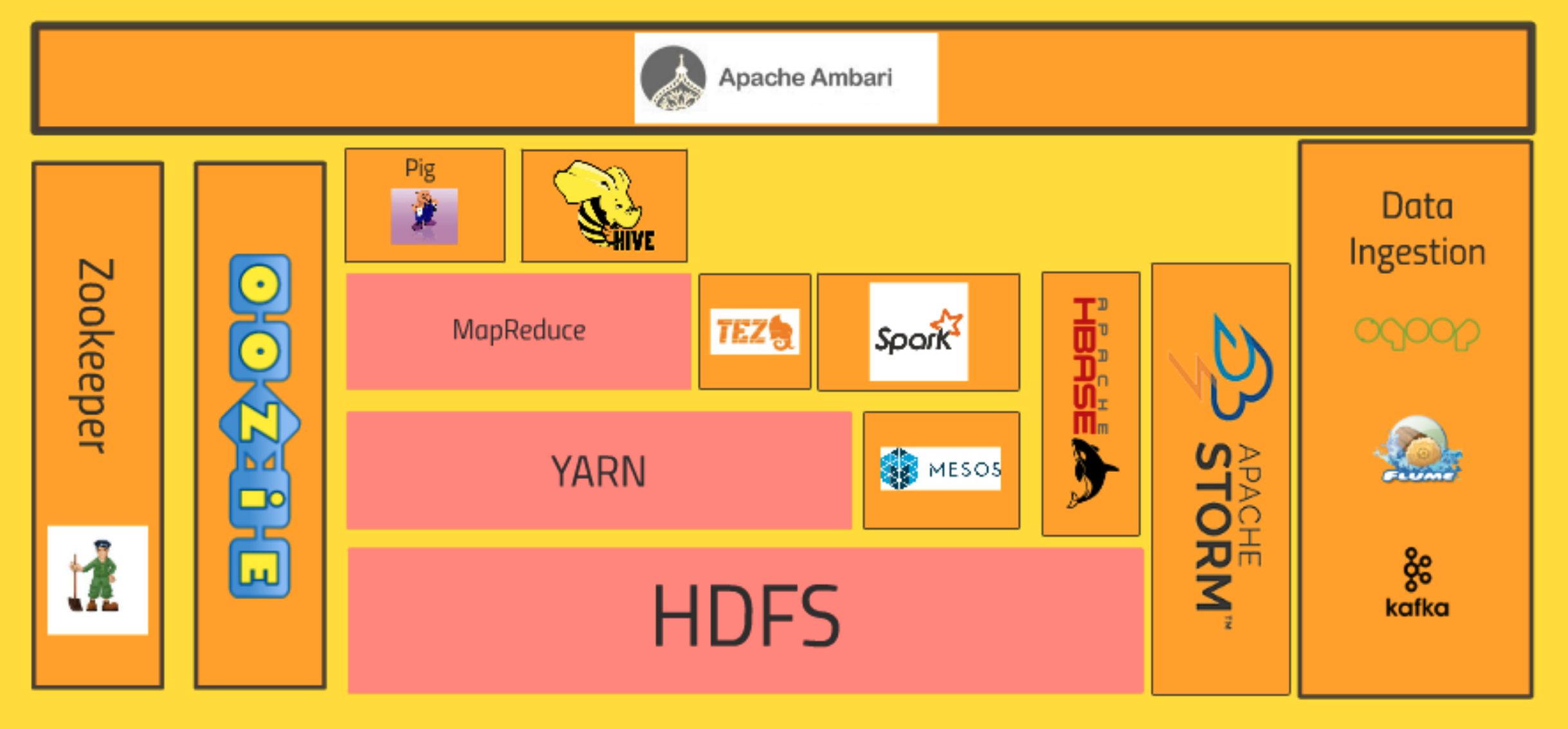
Core Hadoop Ecosystem
![[STEP1 - STEP10]](/images/post_images/220402_first_complete.png)
[STEP 1]
하둡의 가장 핵심적인 생태계의 구성을 살펴보면, 가장 바닥에 HDFS(Hadoop Distribution File System)이 기반을 잡고 있다. 이 부분은 이전에 하둡의 역사에 대해서 알아봤듯이, 구글이 만든 GFS(Google File System)이라는 기술을 기반으로 만든 하둡의 버전의 기술이다.
HDFS는 빅데이터를 클러스터의 컴퓨터들에 분산 저장하는 시스템이다. 클러스터의 하드 드라이브들이 하나의 거대한 파일 시스템을 사용하고, 그 데이터의 여분 복사본까지 만들어서 혹여나 컴퓨터가 불에 타서 녹아버리면, 백업 복사본을 사용해서 자동으로 손실을 회복하도록 한다.(HDFS = 분산 데이터 저장소 역할)
[STEP 2]
HDFS의 위에는 YARN(Yet Another Resource Negotiator)이 있는데, 이 친구는 '또 다른 리소스 교섭자'의 의미로, 데이터의 처리 부분을 담당한다.
HDFS에서 데이터의 저장 부분을 담당했다면, YARN은 HDFS에 저장된 데이터를 처리하기 위한 일종의 데이터 관리자의 역할을 해준다고 보면된다.
다시말해, YARN은 컴퓨터 클러스터의 리소스를 관리하는 시스템이다. 자세히 말하면 YARN은 누가 작업을 언제 실행하고 어떤 노드가 추가 작업을 할 수 있고, 없는지에 대한 결정을 한다. 클러스터를 작동하는 심장박동 같은 곳이 YARN이다.
[STEP 3]
이러한 YARN의 리소스 교섭역할을 통해 그 위에 새로운 어플리케이션 계층이 만들어진다. 그 중 하나는 MapReduce로, 데이터를 클러스터 전체에 걸쳐 처리하도록 하는 프로그래밍 메타포 혹은 프로그래밍 모델이다.
이 MapReduce는 Mapper와 Reducer로 구성이 되어있는데, 이 프로그램을 사용할 때 사용하는 두 개의 구분된 스크립트 혹은 함수라고 볼 수 있다.
Mapper는 클러스터에 분산되어있는 데이터를 효율적으로 변형시킬 수 있고, Reducer는 그 데이터를 집계하는 역할을 한다. 간단하게 역할 정의를 했지만 실제로는 아주 다양한 역할을 수행한다.
본래 MapReducer와 YARN은 거의 같은 역할을 했는데, 최근 분리되었다. 그로 인해 YARN 위에 MapReducer와 같은 역할을 더 효율적으로 수행하는 또 다른 어플리케이션이 개발이 되었다.
[STEP 4]
MapReducer 위에는 Pig라는 기술이 구축이 되는데, 만약 Java나 Python으로 MapReduce를 코딩하기보다 SQL과 같은 스크립팅 언어에 더 익숙하다면 이 Pig라는 친구가 적격이다. Pig는 고수준의 API로, 많은 경우 SQL과 비슷한 간단한 스크립트를 작성해서 쿼리를 연결하고, 복잡한 답을 구할 수 있다.
다시말해, Pig는 작성된 스크립트를 MapReducer가 읽을 수 있도록 번역하고, MapReducer는 다시 YARN과 HDFS에게 데이터를 처리하고 원하는 답을 가져오게 한다.
[STEP 5]Hive는 Pig와 같은 레벨의 계층에 있는 어플리케이션으로, 실제 SQL쿼리를 받고 파일 시스템에 분산된 데이터를 SQL 데이터베이스처럼 취급한다.
shell client나 ODBC등을 통해 Open Database Connectivity 데이터베이스에 접근을 할 수 있고, Hadoop 클러스터에 저장이 되어있는 데이터가 내부적으로는 관계형 데이터베이스가 아님에도 불구하고, SQL로 쿼리할 수 있다.SQL에 익숙하다면, Hive API를 유용하게 사용할 수 있다.
[STEP 6]최 상단에는 Ambari라는 애플리케이션이 위치하는데, 이 친구는 클러스터와 그 위에 동작하는 어플리케이션들의 상태를 볼 수 있게 한다. 이와 비슷한 기능을 하는 다른 기술이 있는데, Cloudera와 MapR이 있으며, 내가 지금 학습용으로 설치한 Hortonworks는 Ambari를 사용한다.
[STEP 7]Mesos는 Hadoop의 일부는 아니지만, YARN과 동일한 계층으로 YARN의 대안 정도로 생각될 수 있다. Mesos 또한 YARN과 같이 리소스 교섭자 역할을 하며, YARN과 Mesos는 서로 다른 방식으로 처리를 한다.
즉, Mesos도 클러스터의 리소스를 관리하는 또 하나의 방법이다. Mesos는 YARN과 같이 협업하게 할 수도 있다.
[STEP 8]
Mesos와 연결되는 기술이 바로 하둡의 생태계에서 가장 흥미로운 기술인 Spark로 이어진다. Spark는 MapReducer와 동등 레벨의 어플리케이션인데, Spark는 YARN과 Mesos중 어느 쪽을 기반으로 하든 데이터에 쿼리를 실행할 수 있다.
MapReducer와 동등 레벨의 어플리케이션이기 때문에 MapReduce와 같이 Python이나 Java 혹은 Scala를 사용해서 Spark의 스크립트를 작성해야한다.
그런데 그 중에서 Scala가 추천된다.
Spark는 무지막지하게 빠르고, 현재 전성기를 누리고 있으며, 이 기술에 대한 다양한 개발활동이 진행 중에 있다. 매우 흥미롭고 강력한 기술이며, 클러스터의 데이터를 신속하고 효율적이며 안정적으로 처리할 수 있다는 강점을 가지고 있다.
이 외에도 굉장한 다양성을 가지고 있어서, 클러스터에 걸친 정보로 머신 러닝을 수행하는 SQL 쿼리도 처리가 가능하고, 실시간으로 스트리밍 되는 데이터를 처리하는 등 다양하고 멋진 작업을 할 수 있다.
[STEP 9]TEZ는 Spark와 비슷한 기술을 사용한다. 특히 방향성 비사이클 그래프를 사용하고, 그로인해 TEZ는 MapReduce의 일을 할 때 더 유리해진다. 그 이유는 쿼리 실행에 더 효율적인 계획을 세우기 때문이다. TEZ는 Hive와 함께 사용이 되어 성능을 가속한다.
위의 구조도에서는 Hive가 MapReducer위에 올라가있는데, TEZ위에서도 동작을 할 수 있다. Hive가 MapReduce를 통과할 때 보다 TEZ를 통과할 때 더 빠를 수 있다.
둘이 서로 다른 방식으로 쿼리를 최적화하고, 클러스터에서 효율적인 답을 구하기 때문이다.
[STEP 10]HBASE는 YARN과 MapReduce 계층을 아우르고 있는데, HBASE는 클러스터의 데이터를 트랜잭션 플랫폼으로 노출하는 역할을 하며, NoSQL 데이터베이스라고 불린다.
HBASE는 기둥형 데이터 스토어이고, 기둥형 데이터 스토어란 단위 시간당 실행되는 트랜잭션의 수가 큰 아주 빠른 데이터베이스를 말한다.
그러므로 데이터를 웹 어플리케이션이나 웹 사이트에 노출시켜서 OLTP(Online Transaction Processing)트랜젝션을 하는데 적합하다.
요약하자면, HBASE는 클러스터에 저장된 데이터를 노출시키고, 데이터는 Spark나 MapReduce등에 의해 전환되었을 수도 있고, 그 후에 결과를 다른 시스템에 노출시킬 방법을 제공한다.
[STEP 11]Apache STORM은 스트리밍 데이터를 처리하는 방식이다. 만약 센서나 웹 로그로부터 데이터를 스트리밍한다면, Apache STORM이나 'Spark Streaming'을 통해 실시간으로 처리할 수 있다.
Apache STORM은 스트리밍 데이터를 실시간으로 처리하기 위해서 개발이 되었으며, 이로인해 더 이상 일괄로 처리할 필요가 없어졌다.
데이터가 실시간으로 입력됨에 따라 실시간으로 기계학습을 업데이트하거나 데이터를 데이터베이스에 저장할 수 있다. 엄청 쿨한 기능이다.
[STEP 12]
OOZIE는 클러스터의 작업을 스케쥴링한다. Hadoop 클러스터에 여러 단계나 시스템이 필요한 작업을 해야 할 때가 있다. 이러한 경우에 OOZIE는 일정에 따라 이런 작업을 순차적으로 진행할 수 있도록 스케줄링한다.
예를들어, 데이터를 Hive에 호출 -> Pig를 통해 통합 -> Spark를 통해 쿼리 -> 결과를 HBASE로 변환시킨다고 하면, OOZIE가 이 모든 것을 관리해서 안정적이고 일관성 있게 실행 할 수 있다.
[STEP 13]
Zookeeper도 OOZIE와 같이 옆으로 따로 빠져있는데, Zookeeper는 클러스터의 모든 것을 조직화하는 기술이다. 이 기술을 사용해서 어떤 노드가 살아있는지 추적할 수 있고, 여러 어플리케이션이 사용하는 클러스터의 공유 상태를 안정적으로 확인한다.
많은 어플리케이션이 실제로 Zookeeper에 의존을 하며, 어떤 노드가 다운되더라도 일관성 있고 안정적인 성능을 전체 클러스터에 걸쳐 유지할 수 있다.
예를들면, Zookeeper는 어떤 것이 마스터 노드이며 어떤 노드가 살아있고 다운되어있는지 추적하는데 사용될 수 있으며, 이외에도 더 다양하게 사용될 수 있지만, 많기 때문에 차차 알아가는 것이 좋다.
[STEP 14]
그 다음으로 살펴볼 내용은 데이터 수집에 특화된 시스템이다.
이 데이터 수집 특화 시스템의 3대장으로는 Sqoop/FLUME/Kafka가 있다.
어떻게 외부 데이터를 클러스터와 HDFS로 가져올 수 있을까?
바로 Sqoop은 Hadoop의 데이터베이스를 관계형 데이터베이스로 엮어낸다. ODBC나 JDBC(Java Database Connectivity)로 소통 가능한 데이터는 Sqoop을 통해 HDFS의 파일로 변형할 수 있다.
다시말하면, Sqoop은 레거시 데이터베이스와 Hadoop을 연결하는 연결 장치라고 볼 수 있다.
[STEP 15]
그 다음 데이터 수집 특화 시스템에는 FLUME이 있다. FLUME을 통해 대규모 웹로그를 안정적으로 클러스터에 불러올 수 있다. 그 예로, 웹 서버 여러 개를 가지고 있다고 가정하자. FLUME은 실시간으로 웹 서버의 웹로그를 감시하고, 클러스터에 게시해서 STORM이나 Spark Streaming을 사용해서 실시간으로 처리한다.
[STEP 16]
Kafka도 데이터 수집을 하지만 좀 더 포괄적으로 사용된다. PC 혹은 웹 서버 클러스터에서 모든 종류의 데이터를 수집해서 Hadoop 클러스터로 내보낸다.