이번 포스팅에서는 Seaborn에 대해서 학습한 내용에 대해서 작성해보려고 한다.
Seaborn
Seaborn은 강력한 데이터 시각화 라이브러리로, matplotlib의 최상에 속하는 라이브러리이다. 그래서 Seaborn이 matplotlib에 비해 기능을 높이는 것을 볼 수 있다고 한다.
우선 판다스와 Seaborn을 활용해서 데이터를 시각화해보는 연습을 해보겠다.
앞으로 많은 것을 학습하고, 까먹을 수 있기 때문에 기본적인 시각화하는 방법에 대해서 기록을 해두겠다.
시각화를 하는 방법에는 여러 방법이 있지만, 그것들은 방법이지 정말 중요한 것은 가장 기본이 되는 시각화를 통해서 얻고자하는 결과와 어떤 사회적 현상을 해결할 수 있는지에 대한 인식의 전환이 필요한 것 같다.
단순히 parameter값을 뭐를 넣고 빼고 함으로써 그래프를 뽑아내는 것이 중요한 것이 아닌, 실제 시각화를 통해서 머신러닝 모델링하기 전에 해당 데이터셋에 적합한 최적의 알고리즘을 선택하기 위한 직관을 얻기 위한 용도로써 데이터 시각화를 바라봐야 되는 것 같다.
아직은 잘 모르는 단계이지만, 일단 이정도의 이론상 개념을 알고 있는 상태에서 앞으로의 AI, ML에 대한 공부도 확장해가야겠다.
1 | import pandas as pd |
1 | import pandas as pd # Import Pandas for data manipulation using dataframes |
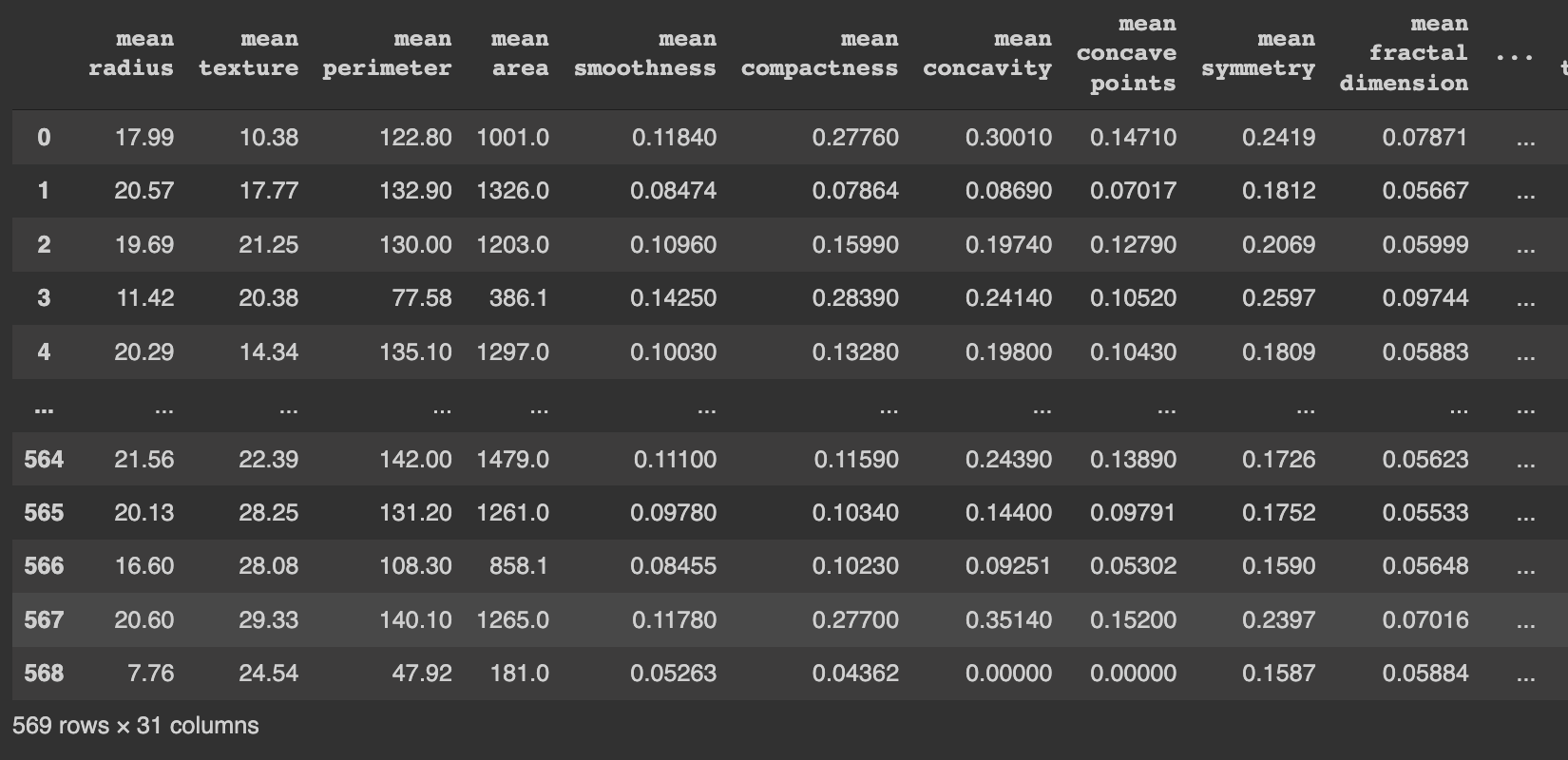
아래의 데이터는 모두 유방암에 대한 데이터 세트이다.
시각화를 할 때 단순히 수치가 나와있는 데이터 세트를 그래프로 시각화히기 위함이 아니다.
아래의 데이터의 수치는 자세히 보면, 종양에 대한 평균 반지름, 평균 질감, 평균 둘레에 대한 정보를 포함하고 있다. 이 데이터 세트에서 마지막 칼럼(target)을 제외한 나머지 칼럼의 값은 주로 머신러닝을 위해 머신러닝 모델에서 입력값으로 쓰인다.
예를들어, AI 모델을 훈련시키기 위한 것으로 쓰이게 되는데, 데이터 세트를 사용하는 목표 또는 목적은 target(특정대상)을 예측하기 위함인데, 이 target column은 모두 0과 1로만 이뤄져 있다.
종양에 대한 평균 반지름 ~ 평균 둘레에 대한 정보의 숫자 정보들은 모두 target이라는 column으로 추려지는데, 0 아니면 1로 표시되고 이것이 악성인지 양성인지 판단되는 척도가 된다. (악성 또는 양성이라는 의미는 암이 자라고 있다는 뜻이거나 종양으로 볼 수 있다는 의미)
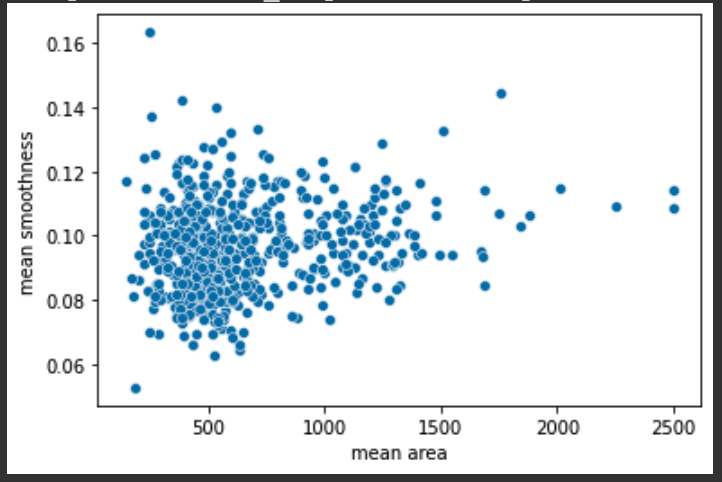
(1) mean area vs mean smoothness 사이의 데이터를 산포도(Scatterplot)으로 그려서 출력을 해볼 것이다.
1 | sns.scatterplot(x = 'mean area', y = 'mean smoothness', data = cancer_df) |
(2) mean area vs mean smoothness 데이터를 산포도(Scatterplot)으로 그려서 출력하되, 악성 종양인지 아닌지를 판별하는 마지막 칼럼(target)을 활용하여 암인 영역대와 암이 아닌 영역대를 색상으로 구분하여 출력될 수 있도록 산포도를 구성한다.
1 | sns.scatterplot(x = 'mean area', y = 'mean smoothness', hue = 'target', data = cancer_df) |
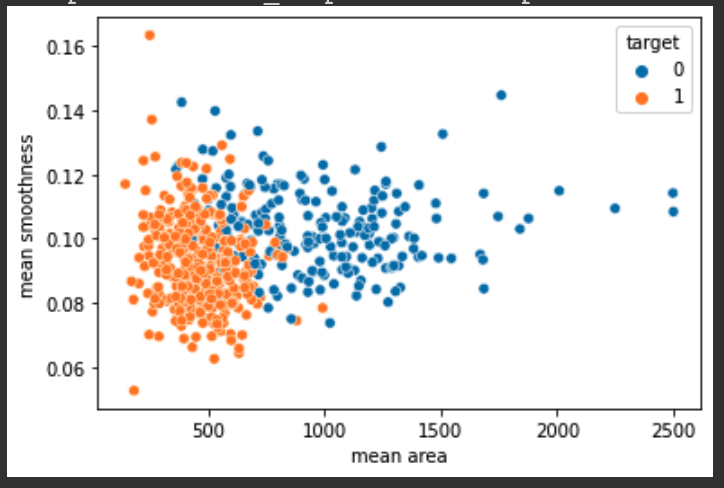
위의 산포도를 분석한다면, target이 0인 것이 target이 1인 것에 비해 평균 영역이 더 높거나 크게 위치해 있는 것을 알 수 있다.
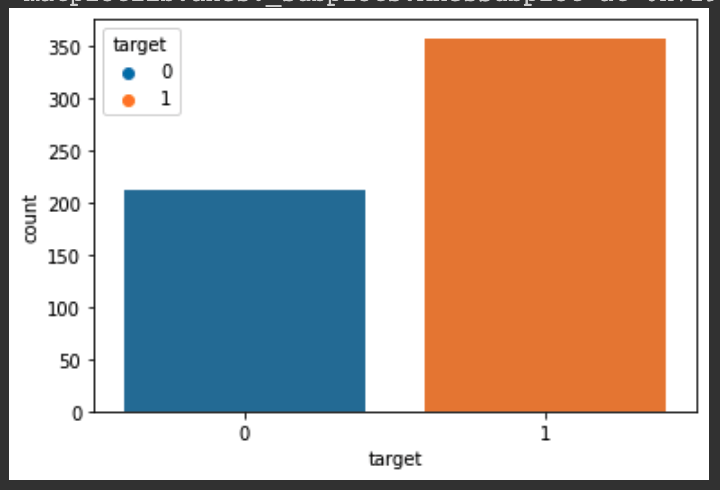
Seaborn으로 극대화 시킬 수 있는 CountPlot
Seaborn으로 극대화해서 보여줄 수 있는 Plot 중에 CountPlot이라는 녀석이 있다.
이 녀석을 기본적으로 unbalanced dataset이라고도 부른다.
(다른 클래스에 비해서 한 클래스에 더 많은 데이터 샘플이 있는 데이터 세트인 경우를 말한다)
1 | # target 칼럼의 0과 1의 갯수를 카운트해서 그래프로 보여주는 CountPlot |
MINI CHALLENGE #1 mean radius와 mean area 사이의 값을 ScatterPlot으로 그리고 Plot에 comment 달기
1 | sns.scatterplot(x = 'mean radius', y = 'mean area', hue = 'target', data = cancer_df) |
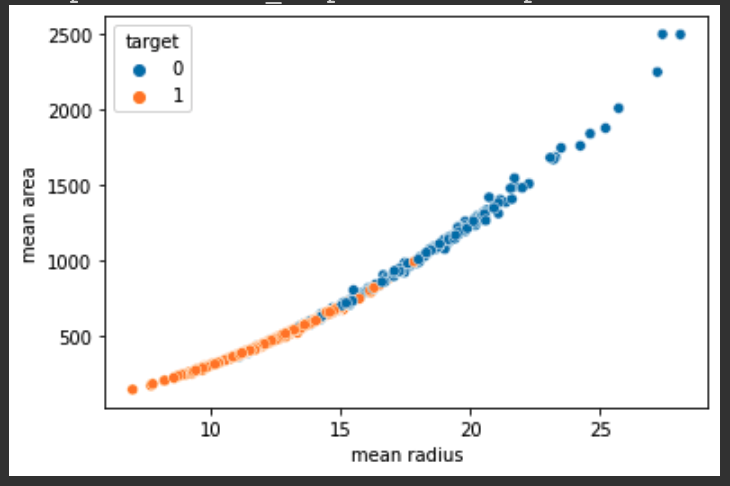
comment on the plot :
산포도를 보면, 정상인 종양이 비 정상인 종양보다 더 넓은 반지름과 넓이를 가지고 있음을 알 수 있다.