이번 포스팅에서는 이번에 처음 배워보는 넘파이(Numpy)에 대해서 개념 및 기본 사용법에 대해서 정리해보려고 한다.
넘파이(Numpy)?
1 2
(1) Numpy는 C언어로 구성되었으며, 고성능의 수치계산을 위해 나온 패키지이며, Numerical Python의 약자이다. (2) Python을 활용한 데이터 분석을 수행할 때, 그리고 데이터 시각화나 전처리를 수행할 때, NumPy는 매우 자주 사용되기 때문에 중요하다.
넘파이의 기본 사용
모듈 Import
1 2 3
import numpy as np
print(np.__version__)
넘파이를 활용한 배열 생성
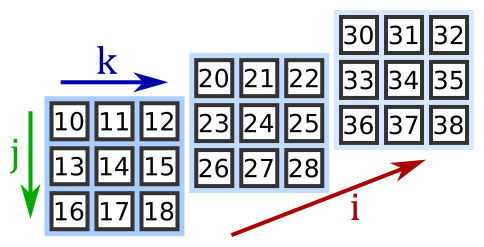
넘파이를 사용해서 배열을 생성할 수 있는데, 그 타입이 ndarray이다. ndarray는 N-dimensional array의 줄임말이다. 넘파이의 배열은 일차원 배열부터 다차원 배열의 형태를 만들 수 있다.
- 배열의 정보를 확인하는 다양한 함수 존재
- 현재 저장된 배열에 대해 RAM의 주소를 확인
1
print(array_2D.data) #<memory at 0x7f445e6339f0>
- 배열의 구조를 확인 할 수 있다.
1
print(array_2D.shape) #(3, 4)
- 배열의 데이터 타입을 확인할 수 있다.
1
print(array_2D.dtype) #int64
- 배열간의 간격 및 각 요소간의 간격에 대해서도 확인이 가능하다.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
import numpy as np
arr = np.array([[1,2,3,4],[5,6,7,8]])
# strides : 걸음걸이, 보폭 (Numpy에서는 각 dimensions를 건너가는데 몇 bytes나 뛰어넘어야 하는지에 대한 정보)
# 8바이트인 int64형이 각 배열에 4개씩 있기 때문에, 32bytes로, dimension간의 간격은 32, 각 배열의 elements간의 간격은 8바이트이므로 (32, 8)로 표기
arr.strides # (32, 8) - (dimensions 간의 간격, elements 간의 간격)
# Numpy에서는 배열을 생성할때 두 번째 인자로 내부에 들어갈 데이터의 타입을 지정해줄 수 있다. # int32 - 4byte # int8 - 8byte arr = np.array([[1,2,3,5],[4,5,6,10]], 'int32') arr.strides # (16, 4) - (dimensions 간의 간격, elements 간의 간격)
# Full Array fullArray = np.full((2, 2), 7) # 2행 2열 배열에 숫자 7로 채워라라는 의미 print(fullArray)
# output #[[7 7] # [7 7]]
# Array of Evenly-Spaced Values (1차원 배열) # arange 특정한 규칙에 따라 증가하는 수열을 생성한다. evenSpacedArray = np.arange(10,50,5) print(evenSpacedArray) # [10 15 20 25 30 35 40 45]
# linspace & logspace 명령은 선형 구간 혹은 로그 구간을 지정한 구간의 수 만큼 분할을 한다. evenSpacedArray2 = np.linspace(0,2,9) print(evenSpacedArray2) # [0. 0.25 0.5 0.75 1. 1.25 1.5 1.75 2. ]
# 열이 같으면 행을 기준으로 붙일 수 있고, 행이 같으면 열을 기준으로 붙일 수 있다. # 위에서 b를 reshape를 통해 a와 같은 2행으로 reshape하고, 열을 기준으로 concatenate해주도록 하자.
b = b.reshape(2, -1) np.concatenate((b, a), axis=1) # axis=1은 열을 기준으로 2차원 배열 a와 b를 붙여준다는 의미이다. # array([[5, 1, 2], # [6, 3, 4]])
.T = 전치행렬 (행과 열을 교환)
reshape를 사용하여 직접 행, 열의 수를 지정하여 행과 열이 교환된 배열의 모양으로 수정해줄 수도 있지만, 간단하게 .T를 사용해서 간단하게 행과 열이 교환된 배열의 모양으로 만들어줄 수 있다.
1
np.concatenate((b.T, a), axis=1)
브로드 캐스팅(Broadcasting)
배열을 가지고 연산을 할 때, 배열의 모양(shape)이 서로 다른 경우에도 서로 다른 배열간의 산술연산이 가능하도록 하는 메커니즘이 바로 브로드 캐스팅이다. 통신에서도 이 브로드 캐스팅이라는 용어가 있는데, 뭔가 신호나 패킷을 특정 도메인 영역에 뿌려준다는 것을 생각하면, NumPy에서의 브로드 캐스팅은 배열내의 전체적인 산술연산을 해주는 것이라고 생각하면 된다.
1 2 3
[브로드 캐스팅의 조건] (1) 두 ndarray 중 최소한 하나의 배열의 차원이 1 이하이면 가능 (2) 두 ndarray의 차원의 축의 길이가 동일하면 가능