이번 포스팅에서는 본격적으로 Hadoop이라는 녀석의 개요와 역사 그리고 생태계에 대해 알아보고 본격적으로 설치를 해보는 것에 대해 작성해보려고 한다.
처음이라 마냥 어렵게 느껴지지만, 이 친구도 이 세상의 많은 기술들 중에 하나이며, 다 이유가 있어서 태어난 친구이기 때문에 한 번 친해져보려고 한다.
재미있는 것은 이 하둡(Hadoop)이라는 녀석과 나는 초면이 아니라는 것이다. (그냥 과거에 스쳐간 인연..)
내가 라즈베리파이에 관심이 한창 있을 무렵에 구글링을 하다가 우연히 라즈베리파이로 슈퍼컴퓨터를 만든 사람이 올린 사진을 보았었는데, 그때 어떻게 만들었는지 너무 궁금해서 이것 저것 찾아보다가 컴퓨터 클러스터링 기술과 관련된 내용을 보았었는데, 이 곳에서 데이터 분산저장하는 기술로 이 하둡(Hadoop)이라는 친구에 대한 내용이 있었다. 딱 여기까지..그때는 컴퓨터로 클러스터링(병렬화)한다는 내용과 이런 내용들이 마냥 어렵게만 느껴져서 이 친구와의 인연은 딱 거기서 마무리되었었다.
그런데 이번에 데이터 엔지니어관련 공부를 하면서 인연의 끈이 있었던 것인지, 이렇게 다시 좀 더 딥하게 공부할 수 있는 기회가 되었다.
자, 이제 컴퓨터 클러스터의 방대한 데이터 세트를 변형하고 분석하는 강력한 도구인 하둡(Hadoop)과 친해져보도록 하자.

HDP(Hortonworks Data Platform)?
분산 스토리지 및 대규모 멀티 소스 데이터 세트 처리가 가능한 오픈소스 프레임워크이다. 이 프레임워크를 설치하는 이유는 이 프레임워크에 Hadoop이 이미 설치가되어있고, 관련 기술들도 일괄 설치가 되어있다.
그래서 나와 같이 하둡을 처음 접하는 사람에게는 적합하다.
간단하게 Virtualbox에 이미지를 올려서 실습하려고 했는데, 기본 RAM이 8GB로 설정이 되어있다.내가 휴대하면서 사용하고 있는 노트북의 RAM이 8GB라 어려울 것 같다는 느낌적인 느낌이 든다. 그래서 간단하게 AWS에 이미지를 올려서 사용을 해보기로 했다.
(이번 기회에 RAM 32GB/SSD 1TB/i5 11세대 스펙이 되는 노트북 하나를 장만했다. 아무래도 향후 프로젝트를 진행하게 되면서 다양한 프로그램을 돌리게 될텐데, 사양이 안좋은 PC로 더 이상 작업을 이어가기 어려울 것 같아 이번 기회에 사양대비 저렴한 노트북 한 대를 구매하였다. 미래를 위한 일종의 투자라고 생각하자.)
앞으로의 학습 목표! 하둡(Hadoop) 생태계의 중요한 요소를 이해 & 기본 사용법 익히기
하둡과 관련된 기술들은 정말 다양하다. 따라서 각 각의 기술들이 하둡의 생태계에서 어떤 역할을 하고 있는지 전체적인 그림을 이해하고, 앞으로 어떻게 더 깊이있게 학습할 것인지에 대한 방향설계에도 도움이 될 것이다.우선적으로 VirtualBox에 다운받은 Hortonworks Sandbox image를 올려서 실습환경을 구축하였다.
Hands-on으로 흥미를 갖고, 살붙이기 식으로 개념을 심도있게 학습하기
기술에 있어, 개념과 원리 그리고 역사는 중요하다. 하지만 실제로 기술적으로 어려운 개념에 대해 학습하는데 있어, 초반에 너무 개념 익히기만 하면 금방 지치게 되는 것 같다. (나는 그렇다. 이건 사람마다 다른 것 같다) 그래서 이번 하둡 그리고 하둡과 관련된 기술들을 학습 할 때에는 직접 실습을 많이 해보고 그 원리와 개념에 대해서 심도있게 학습해보는 방향으로 해보기로 했다.
나의 첫 번째 하둡 실습
한 대의 PC와 여러 대의 PC가 연결된 클러스터 환경에서 데이터가 관리되는 것은 관리 대시보드를 보면 별 차이가 없어보인다. 다만 그 차이는 처리되는 데이터의 양과 규모의 차이일 뿐이다.
나의 첫 번째 하둡 실습은 앞서 셋팅해뒀던 Hortonworks sandbox환경에서 했다.
[작업 순서]
(1) VirtualBox 구동
——— Ambari browser Interface ————–
이 곳에서는 하둡 인스턴스에서 일어나는 일들을 시각화해서 보여준다.
(2) localhost:1080 페이지에서 “LAUNCH DASHBOARD” 선택
(default id/password : maria_dev)
(3) 페이지 최 상단의 헤더의 가장 우측 사용자 배너의 왼쪽에 위치한 격자 무늬 버튼을 클릭 -> “Hive View” 선택
(4) “Upload Table” 탭을 클릭해서 앞서 미리 준비한 CSV dataset을 import 해준다.
- u.data : 평점(rating)관련 데이터 sep=”\t”
- u.item : 영화 제목 정보 sep=”|”
(5) “Query” 탭을 클릭해서 아래의 query를 작성한다.
1 | SELECT movie_id, count(movie_id) as ratingCount |
실제 위의 각 SQL query들을 실행시켜주게 되면, 결과값이 Ambari Browser Interface 출력이 되지만, 내부적으로는 많은 과정을 거쳐서 결과값이 도출이 된다.(내부 가정에 대한 이해 중요!)
만약 위의 작업이 한 대의 PC가 아닌 클러스터에서 진행되었다면, 데이터를 최적으로 쪼갠 후에 전체 클러스터로 배분하고 모두 병렬 처리를 했을 것이다.
(6) 우측 그래프 모양(Visualization) 아이콘을 클릭하고, Positional의 X,Y axis에 각 각의 column을 넣어주면, 분포도가 출력됨을 알 수 있다.
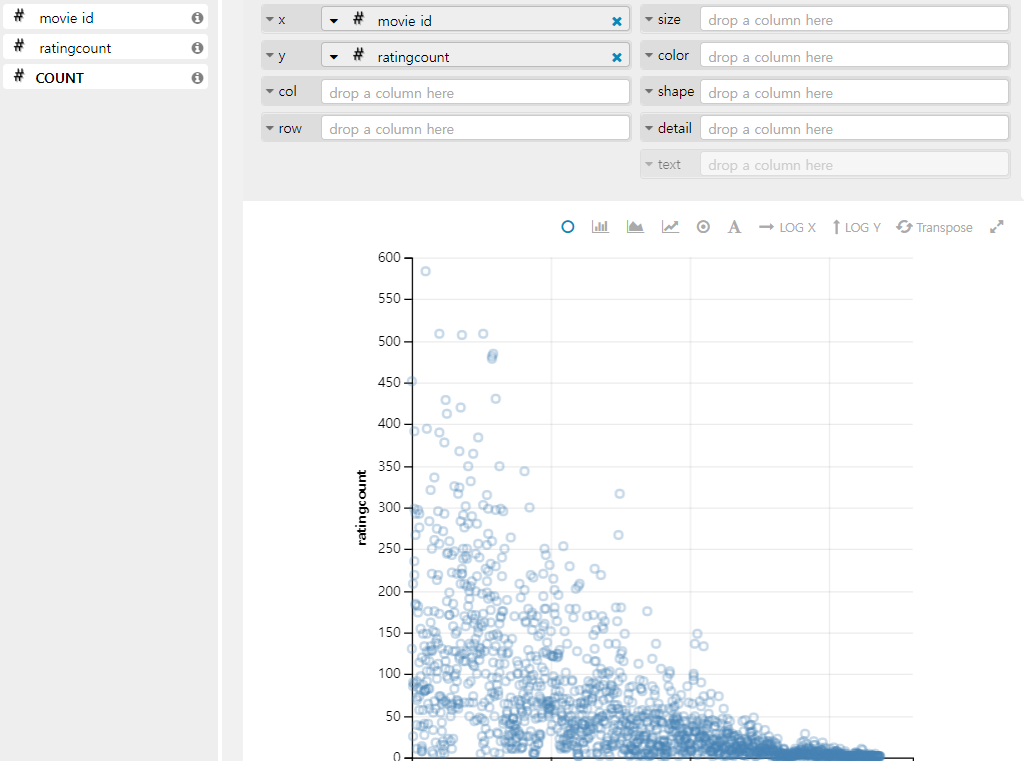
Hive
아직 Hive에 대해서 잘 알지는 못하지만, Ambari에서 Query를 실행시켜보면, Hive는 관계형 데이터베이스는 아니면서 마치 관계형 데이터베이스마냥 행세를 하는 그런 녀석이다. 이번 실습에서는 여기까지만 알고, 앞으로 차근차근 Hive에 대해서 심도있게 알아가자.
