1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
|
portfolio_df = pd.DataFrame({
'stocker ticker symbols': ['NVDA','MSFT','FB', 'AMZN'],
'number of shares': [3, 4, 9, 8],
'price per share[$]': [3500, 200, 300, 400]
})
portfolio_df
portfolio_df['price per share[$]']
portfolio_df['number of shares']
stocks_dollar_value = portfolio_df['price per share[$]'] * portfolio_df['number of shares']
print(stocks_dollar_value)
stocks_dollar_value.sum()
print('Total Portfolio Value = {}'.format(stocks_dollar_value.sum()))
1. DEFINE A PANDAS DATAFRAME
[2]
1초
import pandas as pd
[3]
0초
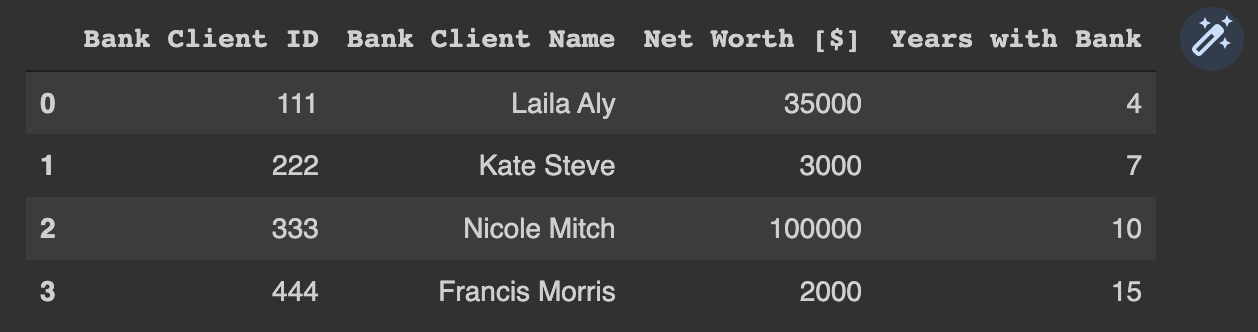
bank_client_df = pd.DataFrame({'Bank Client ID':[111, 222, 333, 444],
'Bank Client Name':['Laila Aly', 'Kate Steve', 'Nicole Mitch', 'Francis Morris'],
'Net Worth [$]':[35000, 3000, 100000, 2000],
'Years with Bank':[4, 7, 10, 15]})
bank_client_df
[4]
0초
type(bank_client_df)
pandas.core.frame.DataFrame
[7]
0초
bank_client_df.head(3)
[8]
0초
bank_client_df.tail(1)
[9]
0초
bank_client_df.shape
(4, 4)
[10]
0초
bank_client_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4 entries, 0 to 3
Data columns (total 4 columns):
--- ------ -------------- -----
0 Bank Client ID 4 non-null int64
1 Bank Client Name 4 non-null object
2 Net Worth [$] 4 non-null int64
3 Years with Bank 4 non-null int64
dtypes: int64(3), object(1)
memory usage: 256.0+ bytes
MINI CHALLENGE
A porfolio contains a collection of securities such as stocks, bonds and ETFs. Define a dataframe named 'portfolio_df' that holds 3 different stock ticker symbols, number of shares, and price per share (feel free to choose any stocks)
Calculate the total value of the porfolio including all stocks
[20]
portfolio_df = pd.DataFrame({
'stocker ticker symbols': ['NVDA','MSFT','FB', 'AMZN'],
'number of shares': [3, 4, 9, 8],
'price per share[$]': [3500, 200, 300, 400]
})
portfolio_df
portfolio_df['price per share[$]']
portfolio_df['number of shares']
stocks_dollar_value = portfolio_df['price per share[$]'] * portfolio_df['number of shares']
print(stocks_dollar_value)
stocks_dollar_value.sum()
print('Total Portfolio Value = {}'.format(stocks_dollar_value.sum()))
|