이번 포스팅에서는 학습했던 Pandas series에 대한 내용에 대해서 복습 및 실습을 하고, 그에 대한 내용을 정리해보고자 한다.
우선 Pandas란 데이터를 분석하고 각종 처리를 할 때 이용하는 파이썬 언어 기반의 라이브러리이다.Pandas로 데이터를 표현하는 두 가지 방법이 있는데 바로 여지까지 학습했던 시리즈(Series)라는 녀석과 데이터프레임(DataFrame)이란 놈이다.
이전 포스팅에서 두 개념(시리즈/데이터프레임)에 대해서 간단하게 다뤄보았지만, 아주간단하게 요약을 하자면,
시리즈(Series)란, 표(table)로 포멧팅되지 않은 리스트 형태로만 표현된 것으로, 열(Column)이 하나인 데이터 프레임이라고 생각하면 된다. 즉, 데이터 프레임은 여러 column의 series를 dictionary형태로 묶은 것이라고 볼 수 있다.
1 | # DataFrame 예시 |
그래서 왜 Pandas를 사용하는데?
실제로 실무에서 분석하고 처리해야되는 데이터는 위에서 예시로 든 데이터와는 비교도 안 될 정도로 엄청 크고 방대할 것이다.
따라서 한눈에 보기 어려운 많은 양의 데이터가 어떤 개요(Overview)와 성향(Features)를 가지고 있고, 그 성향을 좀 더 잘 해석하기 위해서는 어떻게 데이터가 그룹화되어 표현되어야 하는지에 대한 남다른 해석능력도 필요하다. 그리고 데이터 중에서 유독 튀는 이상한 값은 없는지, 항상 확인하고 조작하는데 이 Pandas를 활용한다.
(Kaggle dataset)구글 플레이 스토어 앱 다운로드
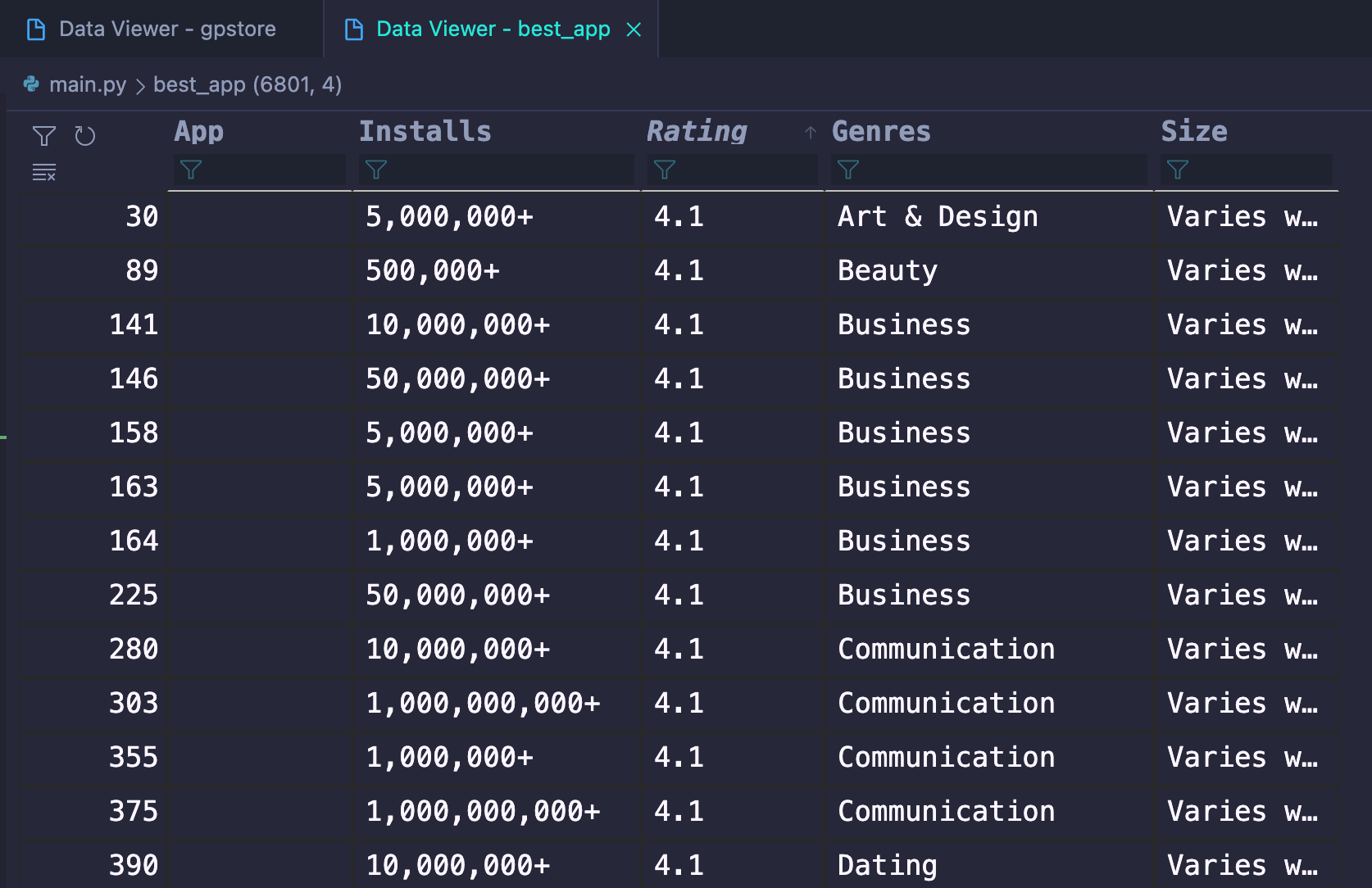
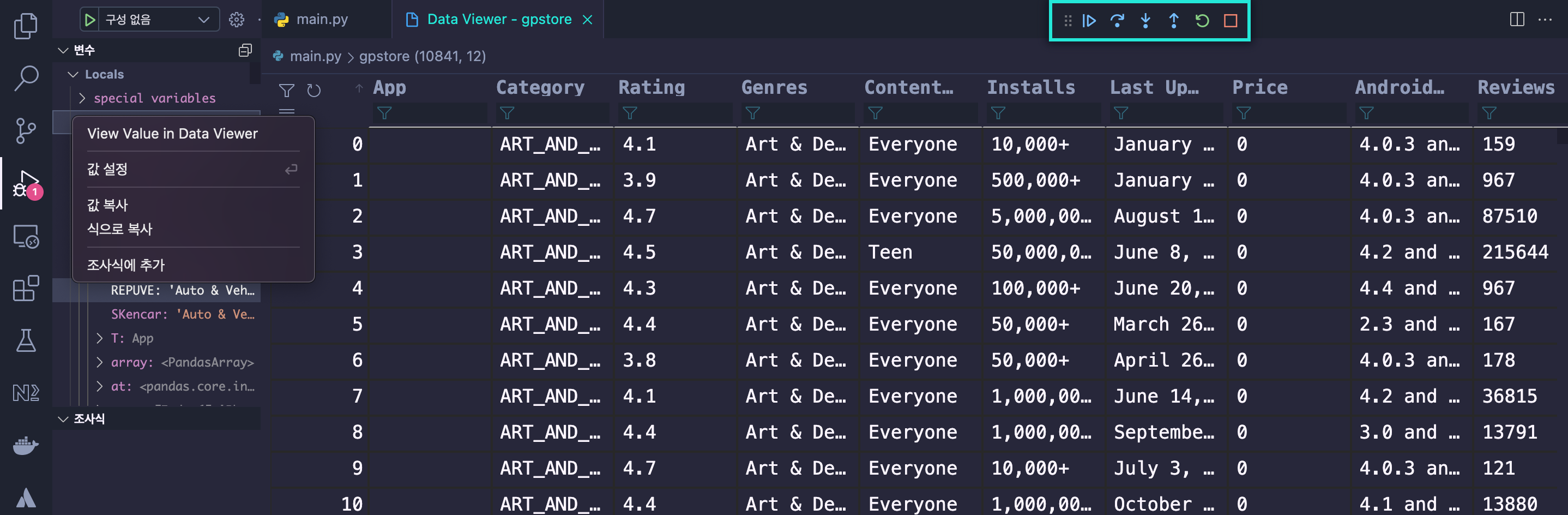
CSV 파일을 Pandas를 이용해서 읽어보고 직접 조작해보도록 하겠다. dataset은 kaggle에서 제공해주는 데이터 중에서 개인적인 흥미에 따라 구글 플레이 스토어 앱 다운로드와 관련된 데이터셋 데이터 정보를 다운받았다.
1 | import pandas as pd |
1 | # 구글플레이 스토어에서 다운받은 앱들 중에서 평점이 4.0 이상인 것들만 Genres, Rating, Installs, Size 항목으로 분류해서 나타낼 수 있도록 DataFrame 구성 |