이번 포스팅에서는 이전 포스팅에서 개괄적으로 분류해보았던 Reinforcement Learning에 대해서 좀 더 구체적으로 정리를 해보고자 한다.
강화학습(Reinforcement Learning)?
강화학습이란 다른 머신러닝(지도학습, 비지도학습)과는 달리 agent라는 개념이 도입된다. 이 agent는 environment(환경)에서 행동을 하는 주체이며, 행동에 의해 새로운 action을 갖으며, 이에 따라 새로운 state(상태)를 갖는다. 이 상대적인 action에 따라 environment(환경)은 새로운 state(상태)와 함께 보상(rewards)을 행동의 주체인 agent에게 부여한다.예시) 미로에서 치즈를 찾는 생쥐 - 환경(미로) / action(쥐의 미로 속 이동) / rewards(치즈) / state(미로 내 쥐의 위치)
- Supervisor가 없고, 환경(Environment)에 의해서 보상을 받고 최상의 rewards를 얻기 위한 action을 선택하도록 한다.
- Feedback이 delay될 수 있다.
- Action이 순차적으로 미래에 주어지는 보상에 영향을 줄 수 있다.
- 환경이 어떤 새로운 상태를 반환할지 예측할 수 없기 때문에
Black box 상태로,어떤식으로 rewards, state를 나타내는지 알지 못한다. - The key challenge is to learn to make good decisions under uncertainty. (핵심 과제는 불확실성에서 최고의 결정을 도출해내는 것을 배우는 것이다.)
OpenAI 사용해보기
OpenAIhttps://gym.openai.com/
1 | import gym |
강화학습 예시1) Frozen Lake
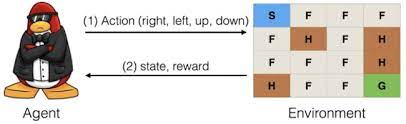
Source에서 Goal까지 이동을 하는 Agent가 존재한다. 위의 그림과 같이 얼은 빙판은 F(Frozen), 구멍이 뚫린 부분은 H(Hole)로 표기가 되어있다.
1 | import gym |
강화학습 예시2) 갤러그 게임
왼쪽, 오른쪽, 총 쏘기와 같은 액션(동작)이 주어지고, 이 액션에 따라 보상(점수)가 주어진다. agent인 player의 상태(state)는 지속적으로 업데이트를 해주며, 이러한 학습을 통해 갤러그와 같은 총 쏘기 게임을 머신러닝의 강화학습 형태로 학습할 수 있다.
강화학습 예시3) 벽돌깨기 게임
사람만이 할 수 있는 전략도 컴퓨털가 학습하여 게임에 적용할 수 있다.
강화학습 예시4) 알파고
강화학습 예시5) 자율주행
Artificial Neural networks
딥러닝(Deep Learning)은 머신러닝의 여러 방법 중 중요한 방법론이며, 인공 신경망(Artificial Neural Network)의 한 종류이다. 즉, 인공지능 ⊃ 머신러닝 ⊃ 인공신경망 ⊃ 딥러닝 관계가 성립한다.
우선 딥러닝에 대해서 학습을 할 것이기 때문에 뉴럴 네트워크의 역사적 배경에 대해서는 상식적으로 알아두어야 한다. 그래서 큼직큼직한 사건은 알아두도록 하기 위해 정리하고 암기해둬야겠다.
Neural network, 한국말로하면, 신경 네트워크이다. 이 Neural network라는 말은 요즘 들어 각광을 받고 있지만, 이 말은 1940년대부터 쓰였던 말이었다. 이 시기부터 사람들은 사람의 뇌 신경 구조를 전자기적 형태(인공 신경망)로 구현하고자 했다. 그래서 1940년대에는 Electronic brain라고 해서 X AND Y X OR Y와 같은 형태로 구조화 시키려고 했다. 하지만 현실적으로 AND, OR로 신경 구조를 만드는 것은 불가능했다.
1957년 Perceptron이라는 개념이 등장을 했는데, 이때부터 사람의 뇌 신경구조를 모방한 인공 신경망을 구현할 수 있었다.
1960년부터 1970년까지 Neural network의 황금기였다가 1970년대에 XOR 문제가 발견이 되면서 Neural network의 암흑기로 돌아간다.
1986년 조페리 힌튼(Geoffrey Hinton)이 Multi-layered Perceptron(Back Propagation)으로 XOR문제를 해결할 수 있다고 증명하였으나, 그 과정이 너무 복잡하고 긴 학습시간으로 주목받지 못하였다.
이후에 1995년 SVM(Support Vector Machine)을 활용해서 XOR문제와 같은 비선형 관계를 학습할 수 있는 모델이 등장하였고, 조페리 힌튼이 제시한 BackPropagation보다 간단하고 효과적이었다.
2006년 Deep Neural Network(Pretraining)모델이 등장을 하게 되고, 1986년 Multi-layered Perceptron(Back Propagation)을 제시했던 조페리 힌튼이 어떻게 학습하는지에 대한 제안을 하게된다.
cf) 심층 신경망(Deep neural networks)
(1) 입력 변수들 간의 비선형 조합이 가능하다.
(2) 특징 표현(Feature representation)이 학습 과정에서 함께 수행될 수 있다.
(3) 데이터가 증가함에 따라 성능이 개선될 수 있다.
이에따라 2010년 후반에는 CNN기반의 이미지 분류 모델인 AlexNet을 통해 Neural Network 모델이 복잡한 문제를 해결할 수 있음을 증명
AI vs ML vs DL 상관관계
AI(Artificial Intelligence)는 ML(Machine Learning)과 DL(Deep Learning)을 아우르는 개념이다. AI는 1990년대 전후로 나눠서 살펴 볼 수 있는데, 1990년대 전에는 명시적 룰(rule)만을 적용해서 기계가 판단하는 식이 전부였다. 하지만 1990년대 이후부터는 명시적 룰(rule)이 아닌 통계를 기반으로 기계가 판단을 하였다.
DL(Deep Learning)은 수많은 parameter들을 가진 복잡한 모델을 어떻게 학습 할 것인지에 대해서 학습기법이다.
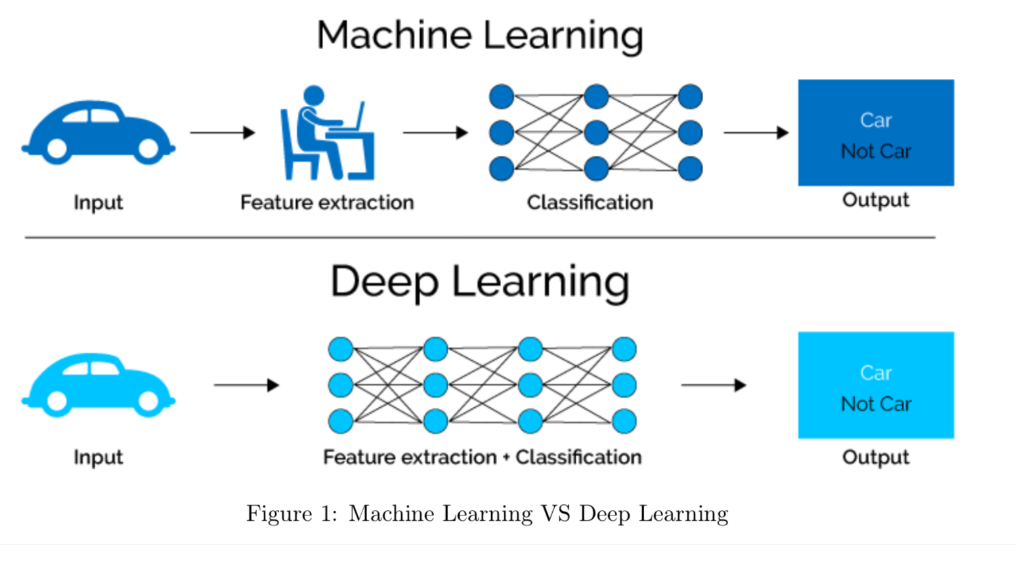
전통적인 머신러닝과 딥러닝의 가장 큰 차이는 feature extraction 과정과 classification 과정의 분리/통합 유/무 상태이다. 전통적인 머신러닝은 두 과정이 서로 분리되어있으며, feature extraction을 통해 나온 출력결과와 Output의 결과가 서로 비교되어 관계학습을 하게 된다.
하지만 딥러닝에서는 feature extraction 단계가 전통적인 머신러닝에서는 필수 단계로 간주되었던 것과 달리, feature extraction(=learned feature) + classification가 통합되어 학습으로 관여된다.
사용하는 측면에서 end to end learning이기 때문에 쉽지만, 이해하는 측면에서는 Black box 형태로 가려져있기 때문에 어렵다.
딥러닝 모델의 예시
Convolutional Neural Network(CNN) : 합성곱 신경망
Recurrent Neural Network(RNN) : 순환 신경망
→ 순차적 관계를 가진 시계열 데이터 처리에 가장 적합한 심층 신경망 기법Graph Neural Network(GNN) : 그래프 신경망
Image Classification
- SVN 25% ERROR RATE
- AlexNet 16% ERROR RATE
Speech Recognition : 2010년 초 RNN model 적용
Machine Translation : 2010년 speech to speech model 적용, 2018 - 2019년 Transformer 적용 (Google translator/Naver Papago)